To fix OpenClaw memory loss, set maxContextTokens to 80% of your model's limit, pin critical instructions with [PINNED] tags, disable automatic context compaction with compactMessageCount: -1, and mount a persistent volume for Docker deployments. The root cause is GitHub bug #25633 — context compaction silently destroys active work mid-session.
Your agent didn't forget. OpenClaw threw away its memory while it was still thinking.
I was three hours into a complex research task. My OpenClaw agent had been browsing competitor pricing pages, compiling data into a structured comparison, and was halfway through a summary when it just... stopped making sense.
It started repeating itself. Asked me for context I'd already given. Then it confidently summarized data it had never actually collected - hallucinating a competitor's pricing that didn't exist.
I checked the logs. That's when I saw it: Context compaction triggered. Summarizing prior messages.
OpenClaw had silently decided my context window was too full, compressed everything into a summary, and destroyed the actual data my agent was working with. Three hours of structured research - gone. Replaced by a lossy summary that kept the vibes but lost the facts.
I thought I'd misconfigured something. Turns out, I'd stumbled into one of the most frustrating open issues in the entire OpenClaw ecosystem.
GitHub Issue #25633: The Bug Report That Hit a Nerve
The issue is titled something innocuous. The reactions tell the real story.
Hundreds of developers reporting the same thing: OpenClaw's context compaction silently destroys active work mid-session. Not old conversations from last week. Not stale memory files. The thing you're working on right now.
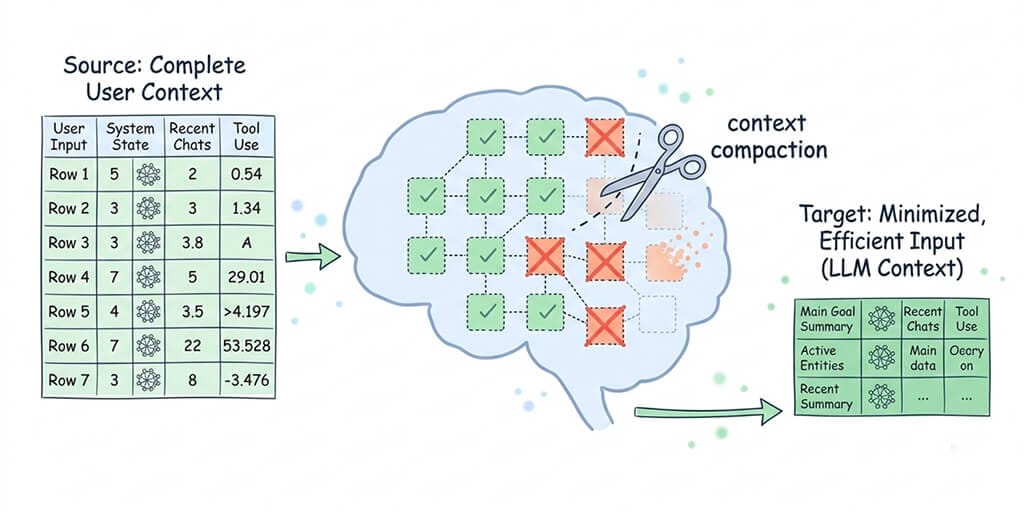
Here's what makes this particularly painful. Context compaction isn't a bug in the traditional sense - it's a design decision. When your conversation history gets too large for the model's context window, OpenClaw's runtime compresses older messages into a summary. The idea is sound. The execution is brutal.
The compaction algorithm doesn't know what's important to your current task. It just sees tokens that need trimming. So your carefully structured data table gets compressed into "the agent collected competitor pricing data." Your multi-step instructions get flattened into "the user asked for a research summary."
The information that made your agent useful? Replaced by a description of that information.
OpenClaw doesn't lose memory because it forgets. It loses memory because it summarizes - and summaries are lossy by design.
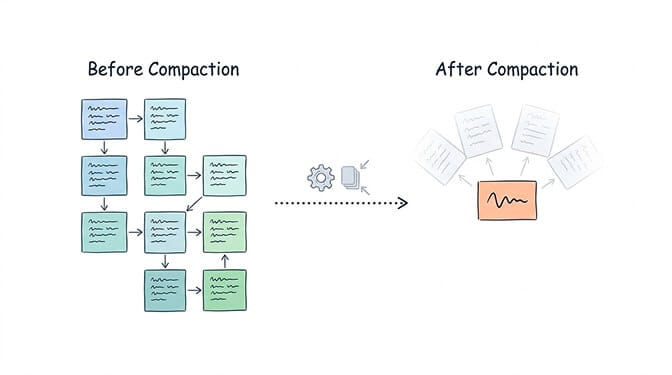
How OpenClaw Memory Actually Works (And Where It Falls Apart)
To understand why this keeps happening, you need to understand how OpenClaw's memory architecture works under the hood.
OpenClaw stores everything as files on disk. Your agent's personality lives in SOUL.md. Skills are YAML and Markdown files. And memory? Also Markdown files in your workspace directory.
When you start a conversation, the Agent Runtime assembles a context window. It packs in your system instructions, conversation history, relevant memories, tool schemas, active skills, and workspace rules. All of this gets sent to whatever LLM you've configured - Claude, GPT-4, or one of the 28+ supported providers.
Here's the problem. Frontier models have large context windows - 100K to 200K tokens. But OpenClaw's context assembly is aggressive. Between the Soul file, skill definitions, tool schemas, and conversation history, you can burn through 50K+ tokens before your agent even starts working on your actual request.
That leaves less room than you think.
And when the conversation fills up? Compaction kicks in. Silently.
There's no warning. No "hey, I'm about to compress your conversation history." No option to choose what gets kept. The runtime just does it. And your agent continues responding as if nothing happened - except now it's working from a summary instead of the actual data.
This is the part that drives people crazy. The agent doesn't crash or throw an error. It seems fine. It keeps talking confidently. But its outputs are subtly wrong - based on compressed approximations of what it used to know.
The Three Ways Your OpenClaw Agent Loses Its Mind
Context compaction is the most common culprit, but it's not the only way OpenClaw memory breaks. After spending weeks in the community forums and Discord, I've mapped out three distinct failure modes.
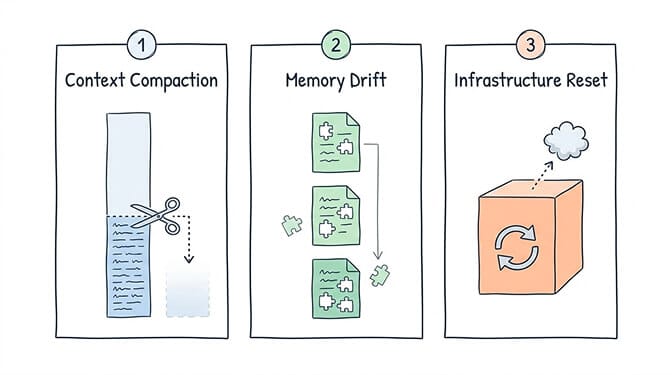
1. Context Compaction Mid-Task
This is GitHub issue #25633. Your agent is actively working, the context window fills up, and the runtime compresses the conversation history. Active data gets summarized. Structured outputs become vague descriptions. Your agent continues operating on degraded information without telling you.
Who it hits hardest: Anyone running complex, multi-step tasks. Research workflows. Data analysis. Long coding sessions. Anything where the agent builds up context over time.
2. Memory File Drift
OpenClaw's persistent memory lives in Markdown files that get "compacted" when the agent decides they're too large. Community member Nat Eliason documented this extensively - he built an elaborate three-layer memory system just to make retention reliable because the default memory pruning kept dropping important context.
The memory files are inspectable, which is great for transparency. But inspectable also means fragile. One bad compaction pass and your agent's long-term knowledge develops gaps. Worse - you might not notice for days, until the agent makes a decision based on something it no longer remembers correctly.
3. Infrastructure Resets
This one's unique to self-hosted deployments. Docker container restarts, OpenClaw updates, server reboots - any of these can wipe conversation state if your volume mounts aren't configured correctly. Community members on the DigitalOcean 1-Click deployment have reported losing entire agent histories after routine updates, with some noting broken self-update scripts and fragile Docker interaction issues.
Your memory files might survive on disk. But the active session context - the thing your agent is currently working with - lives in runtime memory. When the process restarts, it's gone.
The Community Workarounds (And Why They Only Get You Halfway)
The OpenClaw community is nothing if not resourceful. With 850+ contributors and one of the most active Discord servers in open source, people have built impressive workarounds for the memory problem.
Explicit memory pinning. Some users write critical information directly into their SOUL.md file - effectively hardcoding important context so it can't be compacted away. This works, but it eats into your base context budget. Every token in SOUL.md is a token not available for your actual conversation.
Reduced skill loading. Each active skill adds tokens to your context assembly. Users running 15+ skills often hit compaction within minutes. The workaround: only load the skills you need for each session. Effective, but defeats the purpose of having a multi-capable agent.
Shorter sessions. Some power users deliberately end and restart conversations before compaction triggers, manually carrying over key context. It works. It also turns an autonomous agent into a tool you babysit.
Custom memory architectures. Nat Eliason's three-layer system - with separate files for short-term, medium-term, and long-term memory - is genuinely clever. But it took him weeks to build and tune, and it's still fighting against OpenClaw's built-in compaction logic.
Every one of these workarounds has the same fundamental problem: you're patching around a design limitation that exists because OpenClaw treats memory as an afterthought.
The file-on-disk approach is beautiful for transparency. You can git diff your agent's entire personality. You can inspect every memory in a text editor. But transparency and reliability aren't the same thing. And when you're running an agent for real business use cases - client communications, daily briefings, project management - "usually works" isn't good enough.
Watch: Understanding OpenClaw's Architecture and Memory System
If you want to see the full picture of how OpenClaw's Gateway, agent loop, and memory system interact - and why compaction triggers when it does - this 55-minute course from freeCodeCamp walks through the entire architecture. The memory management section starting around the 30-minute mark is particularly relevant to everything we've covered here.
The Real Problem: Memory Shouldn't Be Your Job
Here's what I kept coming back to while researching this article.
Every workaround I found - every custom memory layer, every SOUL.md hack, every session management strategy - required the user to manage their agent's memory. You're not just configuring an AI assistant. You're becoming its memory manager, its ops team, and its therapist.
That's backwards.
The entire point of an AI agent is that it handles the grunt work so you can focus on decisions. If you're spending 30 minutes per session making sure your agent doesn't forget what it's doing, you're not saving time. You're trading one kind of busy work for another.
Memory issues also compound your API costs - every compaction cycle wastes tokens re-establishing context. This is exactly why we built BetterClaw with a fundamentally different memory architecture. Instead of relying on Markdown files and hoping compaction doesn't eat your data, BetterClaw uses hybrid vector + keyword search backed by persistent storage that doesn't depend on your container's runtime state.
Your agent's memory survives restarts. It survives updates. It survives sessions. And because the search is vector-based, your agent doesn't need to stuff everything into the context window - it retrieves what's relevant for the current task, on demand.
No manual pinning. No three-layer workarounds. No crossing your fingers every time a long conversation gets deep. If you need managed OpenClaw hosting with this memory architecture built in, BetterClaw handles it out of the box.
If you've been fighting OpenClaw memory issues and want an agent that actually remembers what it's doing, BetterClaw is $19/month per agent with persistent memory built in. Already self-hosting? Migrate in under an hour →. Deploy in 60 seconds. Stop babysitting your agent's brain.
What This Means If You're Running Agents in Production
Let me be clear about something: OpenClaw is an extraordinary piece of software. Peter Steinberger built something that made autonomous AI agents accessible to regular developers. The 230,000+ GitHub stars aren't hype - they're earned.
But the memory architecture was designed for a different era of AI usage. When OpenClaw launched, most interactions were short. Ask a question, get an answer, move on. Context windows were smaller. Sessions were simpler.
Now people are running multi-hour research workflows. Building business operations around daily agent briefings. Deploying agents that manage client communications across multiple chat channels. The workloads have outgrown the memory system.
GitHub issue #25633 has significant reactions because it's not an edge case anymore. It's the default experience for anyone pushing OpenClaw beyond simple Q&A.
The fix isn't a config change. It's an architectural one. And it's coming - the project's move to an open-source foundation with more contributors should accelerate improvements. But if you're running agents in production today, you need a memory system that works today.
The best agents aren't the ones with the largest context windows. They're the ones that remember the right things at the right time - without you having to manage what "the right things" are.
If you've been losing work to context compaction, spending hours on memory workarounds, or just tired of your agent forgetting what you told it ten minutes ago - give BetterClaw a try. $19/month per agent. Persistent memory that actually persists. Deploy in 60 seconds, and spend your time on the work your agent was supposed to handle in the first place.
Frequently Asked Questions
What is OpenClaw memory and why does it break?
OpenClaw memory is a file-based system that stores your agent's knowledge as Markdown files on disk and loads conversation history into the LLM's context window. It breaks because of context compaction - when the conversation gets too long, OpenClaw silently summarizes and discards older messages, often destroying active work data in the process. GitHub issue #25633 documents this with significant community reaction.
How does OpenClaw context compaction work?
When your conversation history exceeds what fits in the model's context window (after accounting for system instructions, skills, and tool schemas), OpenClaw's runtime automatically compresses older messages into a summary. This happens silently with no user warning. The summary preserves general themes but loses specific data - which is why agents start hallucinating or repeating themselves after compaction triggers.
How do I fix OpenClaw memory loss in self-hosted deployments?
Common workarounds include pinning critical information in your SOUL.md file, reducing active skill count to free context space, running shorter sessions to avoid compaction triggers, and building custom multi-layer memory architectures. Each approach has tradeoffs. Managed platforms like BetterClaw solve this architecturally with hybrid vector + keyword search that retrieves relevant memory on demand instead of stuffing everything into the context window.
Is OpenClaw memory reliable enough for business use?
With default settings, no. Context compaction can destroy active work mid-session, memory files can drift during pruning, and Docker restarts can wipe session state. For business use, you either need significant custom memory management (weeks of setup and ongoing maintenance) or a managed deployment with persistent memory infrastructure built in. BetterClaw provides this at $19/month per agent with memory that survives restarts, updates, and long sessions.
How does BetterClaw handle OpenClaw memory differently?
BetterClaw replaces OpenClaw's default file-based memory with hybrid vector + keyword search backed by persistent storage. Instead of loading all memory into the context window (and compacting when it overflows), BetterClaw retrieves only the relevant memories for each interaction. This means your agent's memory survives container restarts, software updates, and long sessions - without manual pinning, custom architectures, or session babysitting.
Related Reading
- OpenClaw OOM Errors: Complete Fix Guide — Memory crashes that often trigger the issues described above
- OpenClaw Agent Stuck in Loop: How to Fix It — Loops caused by agents losing context after memory compaction
- OpenClaw Not Working: Every Fix in One Guide — Master troubleshooting guide covering all common errors
- OpenClaw Setup Guide: Complete Walkthrough — Get your memory configuration right from the start