Your agent isn't broken. It's just expensive. Here's what's actually happening when OpenClaw loops, and the fastest way to stop the bleeding.
It was 11:47 PM on a Tuesday. I'd set up an OpenClaw agent to summarize support tickets and push updates to Slack. Simple workflow. Twenty minutes, tops.
I went to bed.
I woke up to a $38 API bill from Anthropic. For one night.
The agent had gotten stuck in a retry loop. Every failed Slack post triggered another reasoning cycle. Every reasoning cycle packed more context into the prompt. Every prompt burned more tokens. For six hours straight, my agent was essentially arguing with itself about why a Slack webhook URL was wrong, spending real money on every single turn of that argument.
If you're running OpenClaw and you've seen your API costs spike without explanation, you're not alone. And this isn't a bug. It's a design reality of how autonomous agents work.
Here's what's actually going on.
Why Your OpenClaw Agent Gets Stuck in a Loop (It's Not What You Think)
Most people assume a looping agent means something is misconfigured. Bad YAML. Wrong API key. Broken skill file.
Sometimes, yes. But the more common cause is subtler and more expensive.
OpenClaw agents operate on a reason-act-observe loop. The agent reads its context, decides what to do, takes an action, observes the result, and then reasons again. This is the core pattern behind every agent framework, not just OpenClaw.
The problem starts when the "observe" step returns ambiguous feedback.
Think about it. If a tool call returns "request failed, please try again," the agent should try again. That's what it's designed to do. It's being a good agent. But without explicit limits on how many times it retries, or any awareness of how much each retry costs, it will keep trying forever.
Research from AWS shows that agents can loop hundreds of times without delivering a single useful result when tool feedback is vague. The agent keeps calling the same tool with slightly different parameters, convinced the next attempt will work.
And every single one of those attempts costs tokens.

The Math That Should Scare You
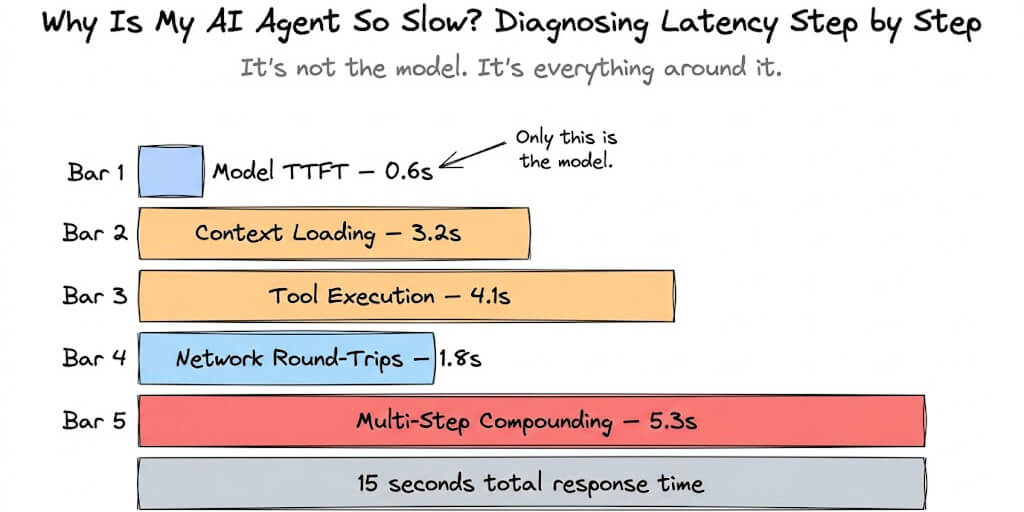
Let's do some quick napkin math on what an OpenClaw loop actually costs.
Say your agent is running Claude Sonnet. Each reasoning cycle sends the full conversation history plus tool definitions plus the latest observation. That's easily 50,000 to 80,000 input tokens per turn once context starts growing.
At Anthropic's current pricing, that's roughly $0.15 to $0.24 per turn for input tokens alone. Add output tokens and you're looking at $0.20 to $0.35 per reasoning cycle.
Now imagine 100 cycles in an hour. That's $20 to $35 burned on a single stuck task.
Switch to a more powerful model like Claude Opus? The numbers get worse fast. And if your agent is running overnight or over a weekend with no circuit breaker, the math becomes genuinely painful.
A single runaway agent loop can consume your monthly API budget in hours. This isn't hypothetical. It happens to people building with autonomous agents every single week.
One developer recently filed a bug report showing a subagent that burned $350 in 3.5 hours after entering an infinite tool-call loop with 809 consecutive turns. The agent kept reading and re-reading the same files, never concluding its task. Worse, the cost dashboard showed only half the real bill due to a pricing tier mismatch.
This is the risk nobody talks about in the "just deploy an agent" tutorials.
The Three Loop Patterns That Drain Your Wallet
Not all loops are created equal. In our experience running managed OpenClaw deployments at Better Claw, we see three patterns over and over again.
1. The Retry Storm
A tool call fails. The agent retries. Same error. Retries again. Each retry adds the error message to context, making the prompt longer and more expensive. The agent isn't learning from the failure. It's just paying more to fail again.
This is the most common pattern. It usually comes from external API timeouts, rate limits, or webhook misconfigurations.
2. The Context Avalanche
This one is sneakier. The agent successfully calls tools, but each tool returns a massive payload. Full file contents. Entire database query results. Complete API responses. The context window balloons with every turn. Eventually, the agent is spending most of its tokens just reading its own history rather than doing useful work.
If you've looked at how OpenClaw handles API costs, you know that context management is half the battle.
3. The Verification Loop
The agent completes a task successfully but then enters an infinite verification cycle. It checks its own work, decides something might be slightly off, "fixes" it, checks again, fixes again. Round and round, perfecting something that was already done, burning tokens on what is essentially AI anxiety.

What OpenClaw Doesn't Do (That You Need to Do Yourself)
Here's what nobody tells you about self-hosting OpenClaw.
OpenClaw is a powerful agent framework. It handles task execution, skill loading, multi-channel communication, and tool calling really well. But it was designed as a framework, not a managed service. That means certain operational safeguards are left to you.
There's no built-in per-task cost cap. No automatic circuit breaker that kills a loop after N iterations. No alert that fires when token consumption spikes. No rate limiting on the agent's own behavior.
If you're self-hosting OpenClaw on a VPS, all of this is your responsibility. You need to configure max retries, set cooldown periods, implement session budgets, and monitor token usage in real time.
The fix itself isn't complicated. A basic circuit breaker config looks something like this:
max_retries: 3 # max retries per task
cooldown_seconds: 60 # cooldown between failures
max_actions_per_session: 50 # cap total actions per session
# kill the agent if it exceeds a dollar threshold per run
Four rules. That's it. But most people don't add them until after the first surprise bill.
How to Stop the Bleeding Right Now
If your agent is stuck in a loop right now, here's what to do.
First, kill the process. Don't wait for it to finish gracefully. Every second it runs is money spent. If you're running in Docker, docker stop will do it. If you're on a VPS, kill the node process.
# If running in Docker
docker stop openclaw
# If running on a VPS, kill the node process instead
Second, check your API provider's dashboard. Look at the token usage for the last few hours. Identify which model was being used and how many requests were made. This tells you the actual damage.
Third, look at the agent's conversation history. Find the point where it started looping. What tool call failed? What was the response? This is your debugging starting point.
Fourth, add guardrails before restarting. Minimum viable guardrails for any OpenClaw deployment: set max_retries in your agent config, implement a session timeout, and add a cost ceiling per task.
If you want to go deeper on preventing these issues before they start, our guide on OpenClaw best practices covers the full configuration approach.
The Case for Not Managing This Yourself
I'll be direct here. We built Better Claw because we got tired of being the human circuit breaker for our own agents.
Every OpenClaw deployment we managed for ourselves had the same lifecycle: set up the agent, it works great for a week, something goes sideways at 2 AM, wake up to a cost spike, spend half a day debugging, add another guardrail, repeat. The agent itself was doing its job. The infrastructure around it was the problem.
BetterClaw runs your OpenClaw agent on managed infrastructure with built-in cost controls, automatic monitoring, and loop detection baked in. $19/month per agent, you bring your own API keys. Your first deploy takes about 60 seconds. We handle the Docker, the uptime, the security patches, and the "why is my agent spending $50 at 3 AM" problem.
You handle the interesting part: building the actual workflows your agent runs.
The Bigger Picture: Why This Problem Is Getting Worse
Here's something worth thinking about.
As models get smarter, agent loops get more expensive, not less. Newer models have larger context windows, which means a looping agent can accumulate more context before hitting limits. They're also better at generating plausible-sounding reasoning, which means they can loop longer before producing output that looks obviously wrong.
A GPT-4 era agent might loop 50 times before filling its context window. A newer model might loop 500 times in the same window, each turn more expensive than the last.
The industry is moving toward longer-running, more autonomous agents. That's exciting. But it also means the cost of a stuck agent is going up, not down.
The tools for building agents are getting better every month. The tools for operating agents safely are still catching up. That gap is where your API budget disappears.
This is why operational infrastructure matters as much as the agent framework itself. The difference between self-hosted and managed OpenClaw isn't just about convenience. It's about whether you have production-grade safeguards running by default or whether you're building them from scratch every time.
What I'd Tell Someone Just Getting Started
If you're setting up your first OpenClaw agent today, here's what I wish someone had told me.
Start with a cheap model for testing. Use Claude Haiku or GPT-4o-mini while you're iterating on your skill files and task configurations. Switch to a more capable model only after you've confirmed the workflow runs without loops. Our model comparison guide breaks down when each model makes sense.
Set cost alerts on your API provider dashboard from day one. Anthropic, OpenAI, and Google all let you set usage alerts. A $5 daily alert is a simple early warning system.
Never leave an agent running overnight without a session timeout. Just don't. The 30 minutes it takes to add a timeout config will save you hundreds of dollars over the life of your deployment.
And if you'd rather skip the infrastructure headaches entirely and just focus on what your agent does, give BetterClaw a try. It's $19/month per agent, BYOK, and your first deploy takes about 60 seconds. We handle the infrastructure. You handle the interesting part.
The Real Cost Isn't the Bill
The thing that actually bothers me about runaway agent loops isn't the money. Money can be recovered.
It's the trust erosion.
Every time an agent loops and burns your budget, it chips away at your confidence in the whole approach. You start second-guessing whether autonomous agents are ready. You add more manual oversight. You reduce the agent's autonomy. And slowly, the thing that was supposed to save you time becomes another system you babysit.
The fix isn't to distrust agents. The fix is to give them proper guardrails so they can be trusted. A well-configured agent with cost caps, retry limits, and monitoring is more autonomous than one you have to watch like a hawk because it might bankrupt you at 3 AM.
Build the guardrails. Trust the agent. Ship the workflow.
Or let us handle the guardrails and skip straight to the good part.
Frequently Asked Questions
Why does my OpenClaw agent get stuck in a loop?
OpenClaw agents loop when tool calls return ambiguous or failed responses without clear stop conditions. The agent's reason-act-observe cycle keeps retrying because it's designed to be persistent. Without explicit max-retry limits or circuit breakers configured in your setup, the agent will keep attempting the task indefinitely, burning API tokens on every iteration.
How much does an OpenClaw agent loop cost in API fees?
A single stuck loop can cost anywhere from $5 to $50+ per hour depending on your model choice and context size. With Claude Sonnet, expect roughly $0.20 to $0.35 per reasoning cycle. At 100 cycles per hour, that's $20 to $35. One documented case showed a subagent burning $350 in just 3.5 hours during an uncontrolled loop with over 800 consecutive turns.
How do I stop an OpenClaw agent that's stuck in a loop right now?
Kill the process immediately. Use docker stop if running in Docker, or terminate the node process on your VPS. Then check your API provider's usage dashboard to assess the damage. Before restarting, add guardrails: set max_retries to 3, add a 60-second cooldown between failures, and cap total actions per session at 50.
Is BetterClaw worth it compared to self-hosting OpenClaw?
If you value your time and want to avoid surprise API bills, yes. BetterClaw costs $19/month per agent with BYOK (bring your own API keys). You get built-in monitoring, loop detection, and managed infrastructure. Self-hosting is free but requires you to handle Docker maintenance, security patches, uptime monitoring, and building your own cost safeguards from scratch.
Can I prevent OpenClaw agent loops without switching to a managed platform?
Absolutely. Set max-retry limits in your agent configuration, implement session timeouts, add per-task cost ceilings, configure cooldown periods between retries, and set up API usage alerts with your provider. These five steps will prevent most runaway loops. The trade-off is that you're responsible for maintaining and updating these safeguards yourself as OpenClaw evolves.
Related Reading
- OpenClaw Not Working: Every Fix in One Guide — Master troubleshooting guide for all common setup issues
- OpenClaw OOM Errors: Complete Fix Guide — Memory crashes that can trigger restart loops
- OpenClaw Memory Fix Guide — Context compaction issues that cause agents to lose track mid-task
- OpenClaw API Costs: What You'll Actually Pay — Understand the cost impact of runaway loops