We ran the same 7 agent tasks across 4 providers. The price differences will make you rethink everything.
I ran the exact same morning briefing task on four different models last Tuesday. Same prompt. Same OpenClaw config. Same Telegram channel.
Claude Sonnet 4.6 returned a crisp summary with my calendar, priority emails, and a weather note. Cost: $0.04.
GPT-4o gave a slightly longer response with similar quality. Cost: $0.03.
DeepSeek V3.2 produced a perfectly adequate briefing with minor formatting differences. Cost: $0.002.
Kimi K2.5 delivered a solid summary, slightly less polished on the email prioritization. Cost: $0.003.
Same task. Same result. A 20x price difference between the most and least expensive option.
That single data point changed how I think about the OpenClaw model comparison entirely. Because the question isn't "which model is best?" It's "which model is best for this specific task at this specific price?"
And for an always-on agent that runs dozens of tasks daily, that distinction is worth hundreds of dollars a month.
Why "best model" is the wrong question for OpenClaw
Most OpenClaw model comparison articles rank providers on benchmarks. Reasoning scores. Code generation accuracy. Context window size.
Those benchmarks matter if you're building a chatbot or a coding assistant. They matter much less if you're running an autonomous agent that checks your calendar, triages emails, runs scheduled research, and manages reminders.
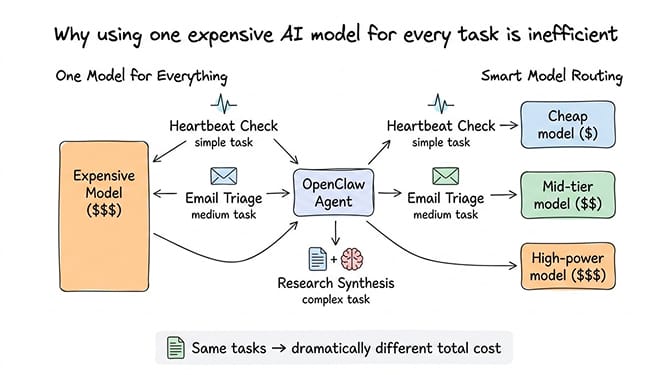
OpenClaw agents perform a mix of tasks with wildly different complexity levels. A heartbeat check (the periodic "are you alive?" ping that runs every 30 minutes) needs zero reasoning capability. An email triage that categorizes 50 messages needs moderate intelligence. A multi-step research synthesis needs genuine reasoning power.
Paying the same per-token rate for all three is like paying steak prices for every meal, including breakfast cereal.
For a detailed look at how these costs compound across different usage patterns, we wrote a full breakdown of OpenClaw API costs with monthly projections by provider.
The four providers worth comparing (and their real pricing)
OpenClaw supports 28+ model providers. But in practice, the OpenClaw community has converged on four that actually work well for agent tasks. Here's what each costs per million tokens (input/output) in March 2026.
OpenAI GPT-4o: $2.50 / $10.00. The most familiar option. Strong all-around performance, massive community support, reliable tool calling.
Anthropic Claude Sonnet 4.6: $3.00 / $15.00. The community favorite for serious agent work. Best-in-class tool calling reliability, prompt injection resistance, and long-context accuracy.
DeepSeek V3.2: $0.28 / $0.42. The budget champion. Surprisingly capable for standard tasks, excellent at code generation, 10-35x cheaper than the top-tier options.
Moonshot Kimi K2.5: ~$0.50 / $1.50. Strong multilingual performance, solid reasoning, emerging as a serious mid-tier contender with OpenClaw-specific community traction.
Those are the list prices. But list prices don't tell you what an agent task actually costs. Token counts vary dramatically by task type, model verbosity, and context accumulation.
So we measured it.
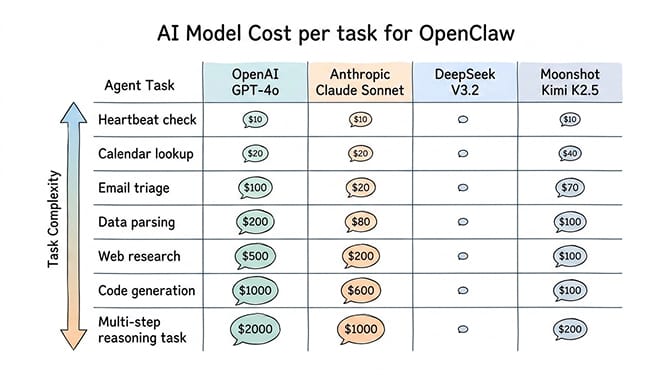
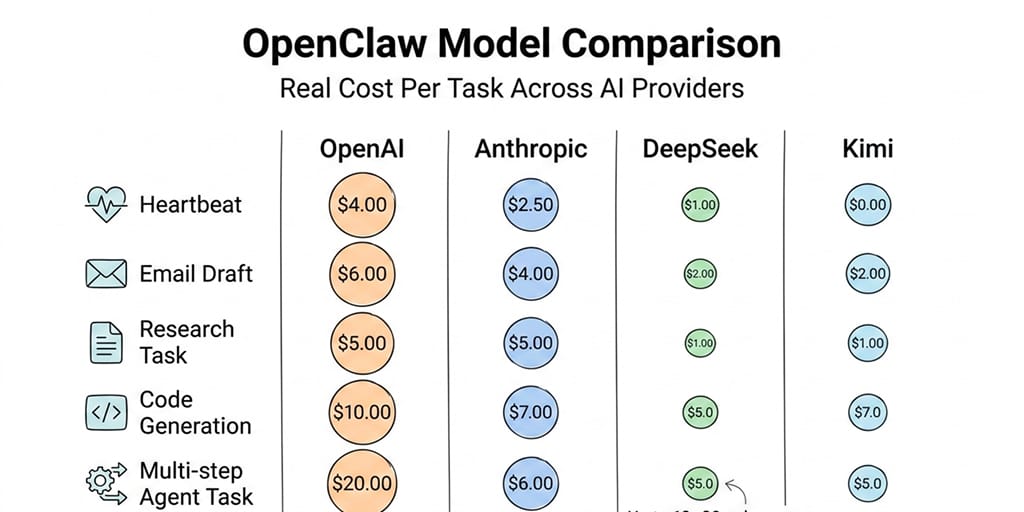
Real cost per task: 7 common agent operations tested
We ran each of these tasks 10 times per provider and averaged the token usage and cost. Same OpenClaw version, same skill configurations, same prompts. Here's what the numbers looked like.
Task 1: Heartbeat check
The periodic status ping. Runs every 30 minutes by default. 48 times per day.
GPT-4o: ~200 tokens, $0.002 per check, $2.88/month Claude Sonnet: ~180 tokens, $0.003 per check, $4.32/month DeepSeek: ~210 tokens, $0.0001 per check, $0.14/month Kimi K2.5: ~195 tokens, $0.0003 per check, $0.43/month
This is where the math starts to sting. If you're running Claude for heartbeats, you're spending $4.32/month on a task that literally just confirms your agent is alive. DeepSeek does the same thing for 14 cents.
Task 2: Morning briefing (calendar + weather + priority emails)
A moderate-complexity task most agents run daily.
GPT-4o: ~2,500 tokens, $0.03 per briefing, $0.90/month Claude Sonnet: ~2,200 tokens, $0.04 per briefing, $1.20/month DeepSeek: ~2,800 tokens, $0.002 per briefing, $0.06/month Kimi K2.5: ~2,600 tokens, $0.004 per briefing, $0.12/month
Quality difference was minimal. All four models produced usable briefings. Claude was slightly more concise. DeepSeek was slightly more verbose (hence the higher token count). The output quality was functionally identical for this use case.
Task 3: Email triage (categorize and prioritize 20 emails)
Medium-complexity reasoning with structured output.
GPT-4o: ~8,000 tokens, $0.09 per run, $2.70/month Claude Sonnet: ~6,500 tokens, $0.11 per run, $3.30/month DeepSeek: ~9,200 tokens, $0.005 per run, $0.15/month Kimi K2.5: ~8,500 tokens, $0.014 per run, $0.42/month
Here's where provider choice starts mattering for quality. Claude was noticeably better at handling ambiguous email subjects and correctly identifying urgency. DeepSeek occasionally miscategorized promotional emails as important. GPT-4o was solid but slightly less precise than Claude on edge cases.
Task 4: Sub-agent parallel research (3 topics simultaneously)
Each sub-agent runs independently, multiplying your costs by 3.
GPT-4o: ~15,000 tokens total, $0.18 per run Claude Sonnet: ~12,000 tokens total, $0.22 per run DeepSeek: ~17,500 tokens total, $0.009 per run Kimi K2.5: ~16,000 tokens total, $0.026 per run
Sub-agents are where costs snowball. If you run parallel research tasks daily, the monthly difference between Claude ($6.60) and DeepSeek ($0.27) is $6.33. Across multiple research tasks per day, that gap widens to $30-50/month.
Task 5: Code generation (write a Python script from natural language spec)
Complex reasoning with precise output requirements.
GPT-4o: ~5,000 tokens, $0.06 Claude Sonnet: ~4,200 tokens, $0.07 DeepSeek: ~5,500 tokens, $0.003 Kimi K2.5: ~5,800 tokens, $0.009
Quality diverged significantly here. Claude produced the cleanest code with better error handling. GPT-4o was close behind. DeepSeek was competitive (it's genuinely strong at code) but occasionally missed edge cases. Kimi K2.5 produced functional code but with less idiomatic Python.
Task 6: Cron job (recurring check every 5 minutes for 24 hours)
This is where context accumulation kills your budget. 288 executions per day, each building on previous context.
GPT-4o: starts at $0.02, climbs to $0.15 as context grows. $12-25/day without limits. Claude Sonnet: starts at $0.03, climbs to $0.20. $15-30/day without limits. DeepSeek: starts at $0.001, climbs to $0.01. $0.80-2.00/day without limits. Kimi K2.5: starts at $0.002, climbs to $0.015. $1.50-4.00/day without limits.
Cron jobs with uncapped context are the single biggest cost trap in OpenClaw, regardless of which provider you use. Set maxContextTokens in your skill config or your bill will climb exponentially.
The OpenClaw memory compaction bug makes this worse. Context compaction can kill active work mid-session, and the workarounds require manual token limits that most tutorials skip.
Task 7: Complex multi-step reasoning (analyze a document, extract data, generate report)
The task that actually justifies premium models.
GPT-4o: ~20,000 tokens, $0.22 Claude Sonnet: ~16,000 tokens, $0.28 DeepSeek: ~24,000 tokens, $0.012 Kimi K2.5: ~22,000 tokens, $0.035
This is where Claude earns its premium. The report structure was tighter, the data extraction more accurate, and the reasoning chain more logical. GPT-4o was a close second. DeepSeek produced a usable report but missed nuances that the premium models caught. Kimi K2.5 fell between DeepSeek and GPT-4o in quality.
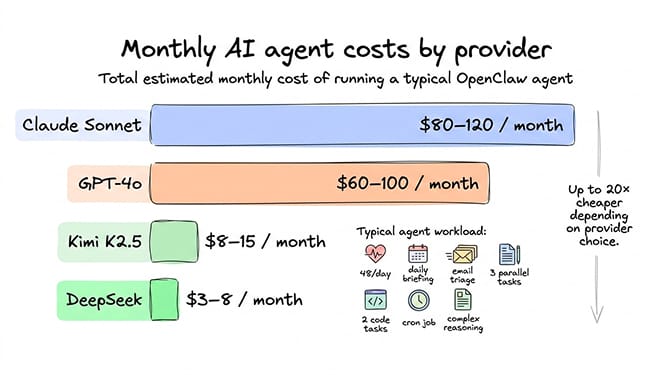
The quality vs. cost matrix (where each provider wins)
After running these tests, a clear pattern emerged.
Claude Sonnet wins on: tool calling precision, prompt injection resistance, code quality, complex reasoning, conciseness (fewer tokens for same output). Worth the premium for tasks where accuracy matters.
GPT-4o wins on: speed, community support, structured output consistency, broad knowledge base. The safest "default" choice with the most tutorials and community examples.
DeepSeek V3.2 wins on: raw cost efficiency, code generation (surprisingly competitive), high-volume simple tasks. The clear winner for heartbeats, sub-agents, and any task where "good enough" is enough.
Kimi K2.5 wins on: multilingual performance (especially Chinese), mid-tier value positioning, solid reasoning at budget pricing. A strong choice if you need Asian language support or want a balance between quality and cost.
If you want to see how to configure multiple providers in your OpenClaw instance and set up automatic model routing per task type, this community walkthrough covers the entire process with real cost comparisons across providers.
Watch on YouTube: OpenClaw Multi-Model Configuration and Cost Optimization (Community content)
The smart play: mix models by task type
Here's what nobody tells you about the OpenClaw model comparison: you don't have to pick one provider.
OpenClaw supports model routing. You can assign different models to different task types in your openclaw.json config:
{
"agent": {
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"heartbeat": "deepseek/deepseek-v3.2",
"subagent": "deepseek/deepseek-v3.2"
}
}
}
This single change takes a typical monthly bill from $80-120 (all Claude) down to $35-50 (Claude for primary interactions, DeepSeek for everything automated).
Add OpenRouter and you can switch models mid-conversation with /model deepseek/deepseek-v3.2 for quick tasks and /model anthropic/claude-sonnet-4-6 when you need precision. And if you want to compare these models side by side in one interface before committing them to a config, a multi-model comparison playground lets you eyeball quality differences first.
If you'd rather not manage config files, model routing, and spending caps manually, Better Claw supports all 28+ providers with BYOK and built-in cost monitoring. $49/month for Pro, zero configuration, and your model choice stays entirely in your hands.
For ideas on what agent workflows are worth the premium model spend, our guide to the best OpenClaw use cases ranks tasks by complexity and value.
The hidden cost everyone forgets: token waste
Raw per-token pricing is only half the story. The other half is how many tokens each model wastes.
Claude Sonnet consistently produced the shortest responses across our tests. Roughly 15-20% fewer output tokens than GPT-4o for equivalent quality, and 25-30% fewer than DeepSeek. Since output tokens cost 3-5x more than input tokens, Claude's conciseness partially offsets its higher per-token price.
DeepSeek is the most verbose. It tends to over-explain, repeat context, and add unnecessary qualifiers. On a per-token basis it's the cheapest. On a per-useful-information basis, the gap narrows.
Kimi K2.5 falls in the middle. Reasonably concise, occasionally verbose on complex tasks.
The cheapest model per token isn't always the cheapest model per task. Factor in verbosity, retries, and error rates when comparing providers.
This is also why OpenClaw's context accumulation problem hits differently per provider. A verbose model like DeepSeek fills your context window faster, which means your cron jobs hit the cost escalation curve sooner.
What about security? (It matters more than you think)
Cost and quality aren't the only variables. Where your data goes matters.
Anthropic (Claude): US-based. Clear data usage policies. Strong prompt injection resistance, which is critical when your OpenClaw agent processes untrusted content from emails and websites. CrowdStrike's security advisory specifically flagged prompt injection as a top risk for OpenClaw deployments.
OpenAI (GPT-4o): US-based. Well-documented privacy policies. Slightly weaker prompt injection resistance than Claude in community benchmarks, but continuously improving.
DeepSeek: Chinese infrastructure. Data routes through Chinese servers. For non-sensitive personal automation, this is fine. For business-critical or regulated workloads, it's a consideration worth thinking through carefully.
Kimi K2.5 (Moonshot AI): Also Chinese-based. Similar data routing considerations as DeepSeek.
For a deeper look at the security implications of running an autonomous agent with access to your email, calendar, and files, our OpenClaw security risks guide covers every documented incident from CrowdStrike, Cisco, and the ClawHavoc campaign.
My actual recommendation (after 3 months of testing)
Here's what I run personally and what I'd recommend for most people doing an OpenClaw model comparison:
Primary model: Claude Sonnet 4.6. For direct interactions, complex tasks, email triage, and anything where quality or security matters. Yes, it's the most expensive per token. The tool calling reliability and conciseness make it worth it for tasks that touch your real data.
Heartbeats and sub-agents: DeepSeek V3.2. For the 48+ heartbeats per day and parallel worker tasks that don't need premium reasoning. This single change saves $40-60/month.
Fallback: GPT-4o. If Claude hits rate limits or has an outage, GPT-4o catches the request. Familiar, reliable, good enough.
Exploration: Kimi K2.5. If you work across languages or want a capable mid-tier option, Kimi is worth testing. Peter Steinberger also recommended MiniMax ($10/month flat rate) as a budget-friendly alternative before joining OpenAI.
Total estimated cost with this setup: $35-55/month in API fees for a moderately active agent. Compared to $80-200/month running everything through a single premium provider.
The model market is getting cheaper every quarter. The right setup today isn't a permanent decision. It's a starting point you refine as new options emerge. (For the current frontier-tier picture, our GPT-5.5 vs Claude vs DeepSeek breakdown ranks the newest models by use case.)
If you've been running your agent on a single provider and the bill keeps climbing, try the mixed-model approach above. The config change takes five minutes. The savings show up in your first billing cycle.
And if you'd rather skip the config file entirely, give Better Claw a try. It's $49/month for Pro, BYOK with any provider on this list, and your first agent deploys in about 60 seconds. We handle the infrastructure, the model routing, and the cost monitoring. You handle the interesting part.
Frequently Asked Questions
What is the best model for OpenClaw in 2026?
There's no single best model. Claude Sonnet 4.6 is the community favorite for complex agent tasks due to its tool calling reliability and prompt injection resistance. DeepSeek V3.2 is the best value for high-volume simple operations. GPT-4o is the safest all-around default. The most cost-effective approach is mixing models: Claude for interactions that matter, DeepSeek for automated tasks like heartbeats and sub-agents.
How does Claude compare to GPT-4o for OpenClaw agents?
Claude Sonnet 4.6 ($3/$15 per million tokens) outperforms GPT-4o ($2.50/$10) on tool calling precision, long-context accuracy, and prompt injection resistance. GPT-4o is faster and has more community tutorials. Claude produces 15-20% fewer output tokens for equivalent quality, partially offsetting its higher per-token price. For most agent workloads, Claude delivers better results per dollar on complex tasks.
How do I switch AI models in OpenClaw?
Edit your ~/.openclaw/openclaw.json file to change the model in the agent.model.primary field, then restart your gateway. For mid-conversation switching, type /model provider/model-name (for example, /model deepseek/deepseek-v3.2). OpenRouter lets you access 200+ models with a single API key, making switching even easier.
How much does it cost to run OpenClaw per month?
Monthly API costs range from $3-8 (DeepSeek for everything) to $80-200 (Claude or GPT-4o for everything). A mixed-model approach (Claude primary, DeepSeek for heartbeats and sub-agents) typically runs $35-55/month. Hosting adds $5-29/month depending on self-hosted VPS versus managed platforms like Better Claw. BYOK means you control API costs regardless of hosting choice.
Is DeepSeek reliable enough for production OpenClaw agents?
DeepSeek V3.2 is reliable for standard agent tasks and excels at code generation. The main tradeoffs: tool calling is less precise than Claude on complex multi-step chains, output tends to be more verbose (increasing context accumulation costs over time), and data routes through Chinese infrastructure. For heartbeats, sub-agents, and non-sensitive tasks, it's genuinely production-ready. For email triage or tasks involving sensitive data, a premium provider offers better accuracy and clearer data policies.