

Search interest for MiniMax M3 spiked 800% overnight. Here's whether the benchmarks hold up for real agent workloads.
I woke up Monday morning to seventeen Slack messages from our ops team, all variations of the same question: Have you seen MiniMax M3?
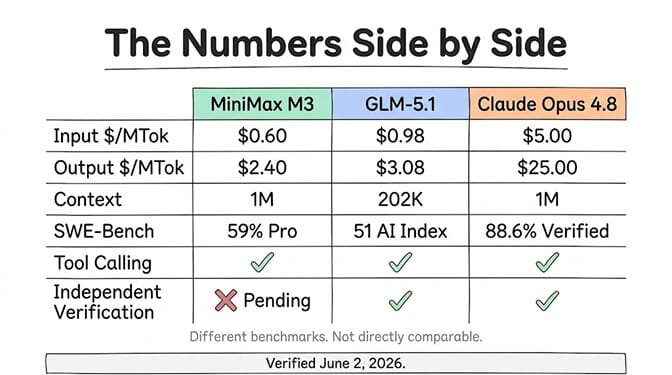
VentureBeat had published the story overnight. A Chinese AI startup just dropped a model claiming to beat GPT-5.5 on coding benchmarks, match Claude Opus 4.7 on autonomous browsing, and do it all at $0.60 per million input tokens. One-eighth the price of Claude. One-eighth the price of GPT-5.5.
The MiniMax M3 AI agent angle was obvious. If this model is real, every routing table in production needs updating. A model that costs $0.60/$2.40 per million tokens with a 1-million-token context window and tool-calling support? That changes the math on everything from support agents to research bots.
But here's the thing. Cheap frontier claims from Chinese AI labs have a pattern. The benchmarks are real... on the benchmark. Then you throw real agent workloads at them, and the numbers shift. Kili Technology, which runs production AI evaluations, found in 2026 that enterprise agentic AI systems show a 37% average gap between lab benchmark scores and real-world deployment performance.
So before you rewrite your routing logic, let's actually compare MiniMax M3 against GLM-5.1 and Claude on the metrics that matter for agents. Not just cost per token. Tool-call reliability. Latency. Context handling. And whether "approaching Opus 4.7" translates to "can actually run a multi-step agent workflow without falling apart."
The MiniMax M3 spec sheet (and why you should read it skeptically)
MiniMax launched M3 on June 1, 2026. Here are the confirmed specs:
Pricing: $0.60 per million input tokens, $2.40 per million output tokens (standard API). OpenRouter is running a 50% launch promo at $0.30/$1.20, but that's temporary.
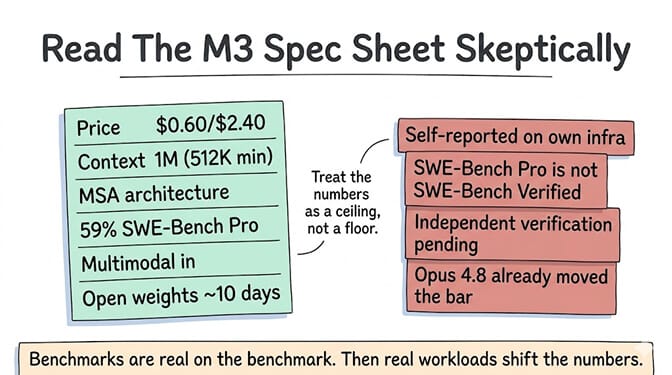
Context window: 1 million tokens, with a guaranteed minimum of 512K. The architecture behind this is MiniMax Sparse Attention (MSA), which they claim cuts per-token compute at 1M context to one-twentieth of their previous generation. That's aggressive. If true, it explains how they can offer 1M context at this price.
Benchmarks: 59.0% on SWE-Bench Pro, 66.0% on Terminal-Bench 2.1, 83.5 on BrowseComp, 74.2% on MCP Atlas.
Multimodal: Accepts text, image, and video input. Outputs text.
Open weights: Coming in roughly 10 days on HuggingFace and GitHub. MIT license expected.
Now here's what you need to read carefully.
MiniMax claims M3 beats GPT-5.5 on SWE-Bench Pro (59.0% vs 58.6%) and approaches Claude Opus 4.7 on browsing benchmarks. But these numbers were run on MiniMax's own infrastructure with their own agent scaffolding. Independent verification is still pending.
This matters for agent developers because SWE-Bench Pro and SWE-Bench Verified are different benchmarks. Claude Opus 4.8 scores 88.6% on SWE-Bench Verified. MiniMax M3 scores 59.0% on SWE-Bench Pro. These are not directly comparable numbers. You cannot put them side by side and draw conclusions. The underlying test sets, evaluation criteria, and difficulty distributions are different.
The TechTimes analysis flagged the same issue: when M3's evaluation was designed, Opus 4.7 was the frontier reference. Opus 4.8 has since moved the bar, which places M3 further from the frontier than the launch announcement suggests.
When a lab reports its own benchmarks on its own infrastructure, treat the numbers as a ceiling, not a floor. Real-world agent performance will be lower. The question is how much lower.
GLM-5.1: The model that's been quietly running agents for two months
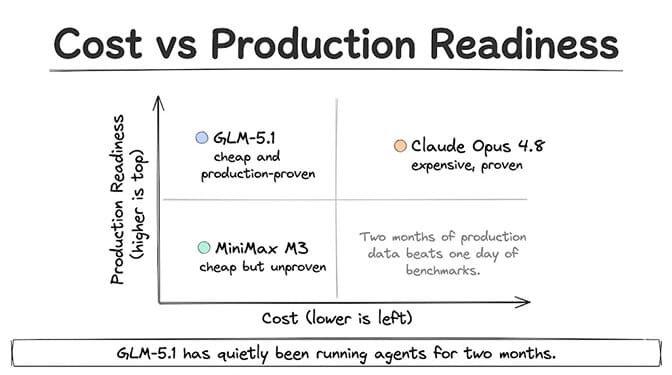
While MiniMax M3 gets the hype, Zhipu AI's GLM-5.1 has been available since April 7 and has two months of production data behind it.
Pricing: $0.98 per million input tokens, $3.08 per million output tokens on OpenRouter. $1.40/$4.40 direct from Z.ai. Cached input at $0.26/MTok.
Context window: 202K tokens. Not 1M like M3, but enough for most agent workflows that use smart context management.
Architecture: 754B parameter MoE model with 40B active parameters per token. Built on DeepSeek Sparse Attention.
Speed: 58.5 tokens per second median output, 1.52s time to first token.
Key differentiator: GLM-5.1 can work autonomously on a single task for 8+ hours. Zhipu AI's CEO stated its coding performance approaches Claude Opus 4.6 (not 4.8, not 4.7). That's a more measured claim than MiniMax's, and it's been partially validated by Artificial Analysis, which gives GLM-5.1 a score of 51 on their Intelligence Index (outperforming 96% of tracked models).
GLM-5.1 also supports tool calling and function calling natively. For agent workloads that need structured tool use (calling APIs, searching databases, triggering webhooks), this is confirmed and shipping. MiniMax M3's tool calling is listed but hasn't been stress-tested independently yet. (Zhipu has since shipped GLM 5.2 — our GLM 5.2 vs Sonnet 4.6 head-to-head covers the upgrade.)
The pricing raised 8-17% versus the previous GLM-5 Turbo, which Zhipu framed as moving toward sustainable monetization. At $0.98/$3.08 on OpenRouter, it's still roughly 5x cheaper than Claude on input and 8x cheaper on output.
If you've been following our model routing cost analysis, you already know the principle: route tasks to the cheapest model that can handle them reliably. The question is whether M3 and GLM-5.1 cross the reliability threshold for your specific workloads.
Claude: the expensive baseline that actually works
Let's be honest about why Claude is in this comparison.
It's not because Claude Opus 4.8 is in the same price class. At $5/$25 per million tokens (standard) and $10/$50 (Fast Mode), Opus 4.8 is 8x more expensive than M3 on input and 10x more expensive on output. That's not a subtle difference.
Claude is here because it's the reliability baseline. When you need to know whether a cheaper model can handle a workload, you compare it against the model you know can handle that workload. For agent tasks, that's typically Claude. For the focused two-model view, see our MiniMax M3 vs Claude Sonnet 4.6 breakdown.
Opus 4.8's agent-relevant specs:
SWE-Bench Verified: 88.6%. This is the independently verified benchmark, not a self-reported one.
Effort control: Low, high, extra, max. This is an agent cost lever. Set effort=low for simple routing decisions (cheap and fast). Set effort=max for hard reasoning tasks (expensive but accurate). The model adapts its token consumption per request.
Self-correction: 4x less likely to pass code flaws compared to 4.7. In multi-step agent loops, this compounds. Fewer mistakes early means fewer correction cycles later, which means fewer total tokens.
Context: 1M tokens at flat pricing.
Speed: Fast Mode runs 2.5x faster at $10/$50. For real-time agents, this is the latency option.
For a broader comparison of how Opus 4.8 compares to GPT-5.5 and DeepSeek V4 Pro, we published the full June 2026 model comparison with cost scenarios across three workload types.
The real comparison: cost per agent task, not cost per token
Cost per token is a useful starting point but a terrible ending point. What matters for agents is cost per completed task. A model that's 8x cheaper per token but needs 3x more attempts to complete a task correctly isn't actually cheaper.
Here's a framework for thinking about this:
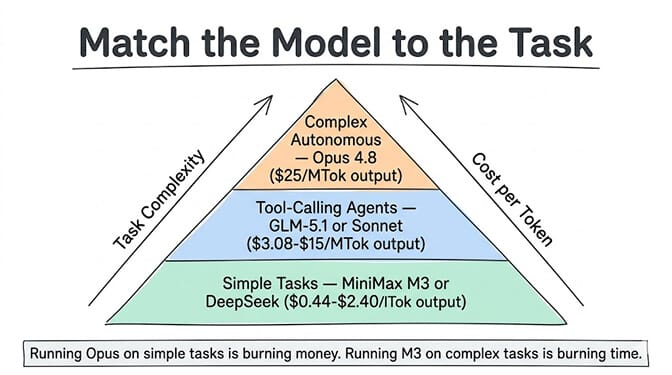
Tier 1: Simple tasks (email drafts, FAQ answers, data extraction, summarization)
These tasks have a low reasoning floor. A model doesn't need to be frontier-class to draft an email or extract structured data from a document. The failure mode isn't "wrong answer" but "slightly awkward phrasing," which is often acceptable.
Best pick: MiniMax M3 or DeepSeek V4 Pro. At $0.60/$2.40 (M3) or $0.44/$0.87 (DeepSeek), either works. DeepSeek V4 Pro is actually cheaper on output ($0.87 vs $2.40), has more production history, and is independently validated. M3's advantage is the 1M context window for tasks involving very long documents. If your extraction task fits in 200K tokens, DeepSeek wins on price. If it needs 500K+, M3 is the only sub-$1 option.
Monthly cost for 2M output tokens: M3 = $4.80. DeepSeek = $1.74. Claude Sonnet 4.6 = $30. Opus 4.8 = $50.
Tier 2: Structured tool-calling agents (CRM updates, calendar management, webhook triggers)
These tasks require reliable function calling. The agent needs to select the right tool, format the parameters correctly, and handle error responses. A model that occasionally hallucinates parameter names or calls the wrong tool creates silent data corruption.
Best pick: GLM-5.1 or Claude Sonnet 4.6. GLM-5.1 has confirmed tool calling with 2 months of production use. MiniMax M3 lists tool support but lacks independent stress testing. For tool-calling agents, I'd wait 4-6 weeks for M3's open weights to be tested by the community. GLM-5.1 at $0.98/$3.08 is a solid middle ground. Claude Sonnet 4.6 at $3/$15 is the safe pick with the deepest integration ecosystem.
Monthly cost for 5M output tokens: GLM-5.1 = $15.40. Claude Sonnet = $75. Opus 4.8 = $125.
This is where a platform matters. On BetterClaw, you assign different models to different agents via BYOK with zero inference markup. Your simple email agent runs on DeepSeek or M3. Your CRM agent runs on GLM-5.1 or Sonnet. Same platform, same visual builder, wildly different cost profiles. Free plan available, $49/month on Pro. No credit card for free.
Tier 3: Complex autonomous workflows (multi-step coding, research synthesis, decision chains)
These tasks punish mistakes exponentially. A wrong decision at step 3 of a 12-step workflow means steps 4-12 are wasted tokens. The model needs strong reasoning, self-correction, and the ability to recover from errors without human intervention.
Best pick: Claude Opus 4.8 (effort=high or max). This isn't even close right now. Neither M3 nor GLM-5.1 has demonstrated the autonomous reasoning depth needed for complex multi-step workflows where errors cascade. Opus 4.8's 4x improvement in self-correction and its 88.6% SWE-Bench Verified score (independently confirmed) represent a quality tier that sub-$1 models haven't reached.
Monthly cost for 10M output tokens: Opus 4.8 = $250. Opus 4.8 effort=low for routing + effort=max for hard steps blended: ~$175.
The data sovereignty question is real
Both MiniMax (Chinese) and Zhipu AI/GLM (Chinese, Beijing-based) process data through Chinese-operated infrastructure. This isn't a technical limitation. It's a compliance and policy question.
If you're in healthcare, finance, government, or any regulated industry with data residency requirements, these models may be off the table regardless of cost. Check with your legal and compliance teams before routing production data through Chinese API endpoints.
For teams where data sovereignty isn't a concern (many startups, internal tools, non-regulated industries), the cost savings are massive enough to justify the evaluation.
What to actually do this week
Here's my honest recommendation for ops leads evaluating the MiniMax M3 AI agent opportunity:
Don't migrate production workloads to M3 yet. The benchmarks are self-reported. Independent verification is pending. Open weights aren't available for 10 days. Wait for the community to stress-test tool calling, multi-turn reliability, and long-context stability.
Do add M3 to your testing pipeline. Set up a shadow environment where you run the same prompts through M3 and your current model. Compare outputs. Track failure rates. Measure actual latency, not advertised latency. The 50% OpenRouter launch promo makes testing nearly free.
Consider GLM-5.1 for Tier 2 workloads now. It's been available for two months, has Artificial Analysis benchmarks, confirmed tool calling, and costs $0.98/$3.08. If you're currently running Sonnet 4.6 at $3/$15 for structured tool-calling agents, GLM-5.1 is worth testing as a 70% cost reduction.
Keep Claude for Tier 3 workloads. Nothing in this comparison changes the calculus for complex autonomous agents. Opus 4.8 with effort control remains the strongest option for workloads where reasoning depth matters. If you want to learn how to choose the right LLM for each task type, we published a decision framework last month.
Build for model portability. The next MiniMax M3 will show up in three months. And the one after that. The teams that win aren't the ones who pick the best model today. They're the ones who build infrastructure that makes switching models a configuration change, not a migration project.

The uncomfortable truth about cheap models
Here's what I keep thinking about.
We've entered a phase where frontier-class benchmarks are available at commodity prices. MiniMax M3 at $0.60 input. DeepSeek V4 Pro at $0.44. GLM-5.1 at $0.98. Two years ago, these price points didn't even exist in the mid-tier.
But benchmarks aren't deployments. A model that scores well on SWE-Bench Pro running on the lab's optimized infrastructure with curated scaffolding is a different product than that same model running your messy real-world agent workflow with partial contexts, noisy inputs, and tool-calling edge cases.
The 37% performance gap that Kili Technology documented between lab scores and production deployment isn't a flaw in any specific model. It's a property of the problem. Benchmarks measure capability. Production measures reliability. These are different things.
The cheap models are getting better. Fast. M3 is genuinely impressive for its price point. GLM-5.1 has quietly become one of the best cost-performance options for agent workloads. But "impressive for the price" and "ready to replace Claude in production" are statements separated by months of testing, community validation, and edge-case discovery.
Use the cheap models where they're sufficient. Use the expensive models where they're necessary. And build your agent infrastructure so moving between them takes seconds.
If any of this resonated, give BetterClaw a look. Free plan with 1 agent and 500 credits a month. $49/month for Pro. Connect your own API keys for all these providers. Zero markup. We handle the routing, the security, and the infrastructure. You handle picking which model goes where.
Frequently Asked Questions
What is MiniMax M3 and why is it relevant for AI agents?
MiniMax M3 is a multimodal foundation model launched June 1, 2026, by Chinese AI startup MiniMax. It's relevant for agents because it combines a 1-million-token context window, tool-calling support, and frontier-class coding benchmarks (59% SWE-Bench Pro) at $0.60 per million input tokens. That's roughly 8x cheaper than Claude Opus 4.8. Open weights are expected within 10 days.
How does MiniMax M3 compare to Claude for agent workloads?
On raw benchmarks, M3 scores 59% on SWE-Bench Pro while Claude Opus 4.8 scores 88.6% on SWE-Bench Verified (these are different benchmarks and not directly comparable). On price, M3 is 8-10x cheaper. On production readiness, Claude has years of deployment data while M3's benchmarks are self-reported and pending independent verification. For simple agent tasks, M3 may be sufficient. For complex multi-step workflows, Claude remains the safer choice.
How much does it cost to run an AI agent on MiniMax M3 vs GLM-5.1 vs Claude?
For a typical support agent processing 2M output tokens/month: MiniMax M3 costs ~$4.80, GLM-5.1 costs ~$6.16, and Claude Opus 4.8 costs ~$50. For a coding agent at 10M output tokens: M3 costs ~$24, GLM-5.1 costs ~$30.80, and Opus 4.8 costs ~$250. The gap widens at scale, but cheap models have higher task-failure rates on complex workloads, which adds hidden retry costs.
Is MiniMax M3 reliable enough for production AI agents?
It's too early to say definitively. M3 launched June 1, 2026, with self-reported benchmarks pending independent verification. Kili Technology found a 37% average gap between lab benchmarks and real-world deployment for enterprise agentic AI in 2026. The recommendation is to shadow-test M3 against your current model before migrating production workloads. Wait for open weights (expected ~10 days) and community stress-testing before committing.
Can I use MiniMax M3, GLM-5.1, and Claude in the same AI agent platform?
Yes. Platforms that support BYOK (Bring Your Own Key) across multiple providers let you assign different models to different agents or task types. BetterClaw supports 28+ model providers with zero inference markup, so you can route simple tasks to M3 or GLM-5.1 and complex tasks to Claude within the same agent infrastructure. Free plan with 1 agent, $49/month on Pro.



