You're paying Claude Opus prices for tasks that a $0.14/M model handles identically. Here's the fix that cuts AI costs by 70-90% without losing quality.
A developer in the OpenClaw Discord posted a screenshot of his Anthropic invoice last month. $178. One week. A single agent.
The replies were a mix of horror and recognition. Someone else shared $340 in a month. Another said they'd burned through $40 in a single afternoon because their agent got stuck in a reasoning loop with Claude Opus.
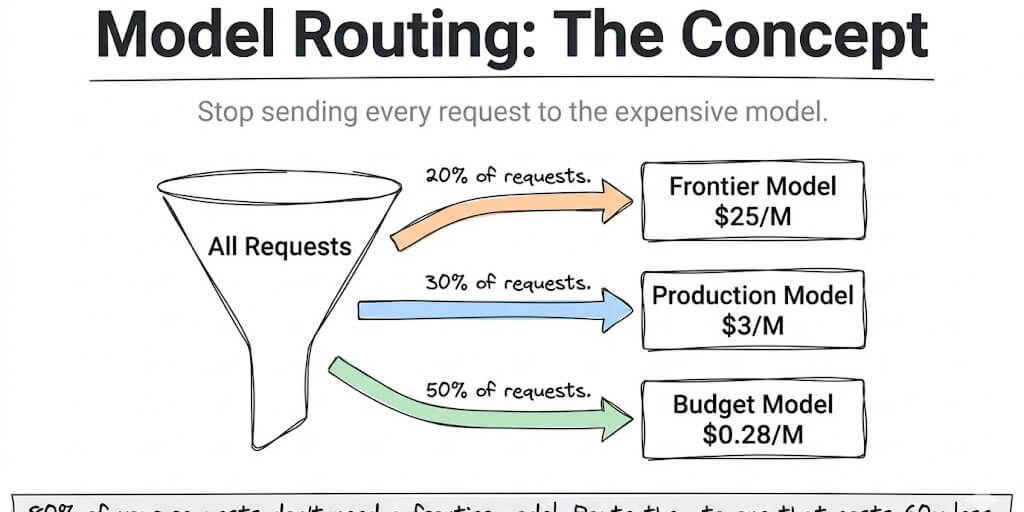
Here's the thing nobody told any of them: 80% of those requests didn't need Opus.
The "hello, what's on my calendar?" message. The email classification. The quick Slack reply. The heartbeat status check that fires every 5 minutes. All of those went to Claude Opus 4.7 at $5/$25 per million tokens... the same model that scores 87.6% on SWE-Bench... for tasks a $0.14/M model handles identically.
That's not a billing problem. That's a model routing problem. And it's the single most expensive mistake in AI right now.
The math that should make you uncomfortable
Let's run the numbers on a typical AI agent handling 1,000 requests per day.
Without routing (everything goes to Claude Opus 4.7):
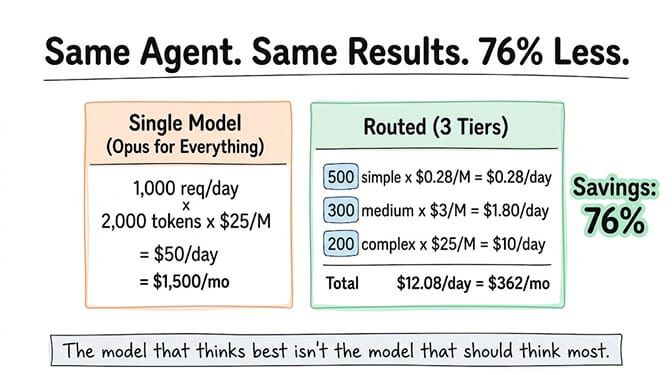
1,000 requests. Average 1,500 input tokens and 500 output tokens per request. At $5/$25 per MTok: ($5 x 1.5M + $25 x 0.5M) / 1,000,000 = $20/day input + output combined. That's $600/month.
But here's what those 1,000 requests actually look like:
500 are simple (greetings, status checks, classification, formatting, heartbeat pings). 300 are moderate (email drafts, search summaries, calendar management). 200 are complex (multi-step reasoning, code generation, nuanced analysis).
With routing (three tiers):
500 simple requests on DeepSeek V4 Flash ($0.14/$0.28): $0.21/day. 300 moderate requests on Claude Sonnet 4.6 ($3/$15): $3.60/day. 200 complex requests on Claude Opus 4.7 ($5/$25): $3.50/day.
Total: $7.31/day. That's $219/month.
Same agent. Same results on every task. $381/month saved. 63% reduction.
And that's being conservative. If you push the simple tier to Gemini Flash-Lite ($0.10/$0.40) or Amazon Nova Micro ($0.035/$0.14), the savings climb past 80%.
The single most expensive decision in AI isn't which model you pick. It's using one model for everything.
What model routing actually is (and isn't)
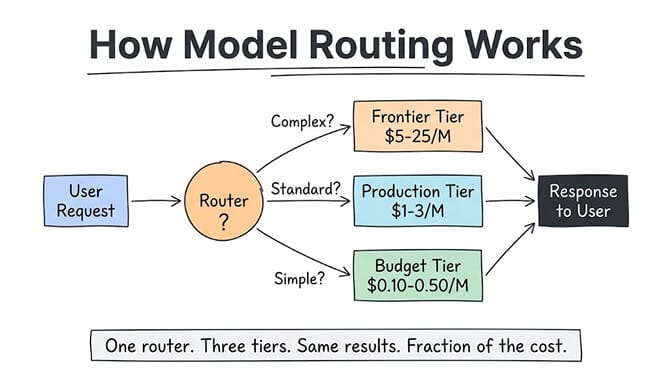
Model routing is exactly what it sounds like: a layer that sits between your application and the LLM providers, analyzes each incoming request, and sends it to the cheapest model that can handle it well.
It's not a new model. It's not fine-tuning. It's not prompt engineering. It's traffic management for AI.
Think of it like a mail room. A letter asking for your office hours doesn't go to the CEO. A contract negotiation does. Model routing applies the same logic to AI requests: simple tasks go to the fast, cheap model. Hard tasks go to the powerful, expensive one.
The routing decision happens in milliseconds and is based on one or more of these signals: input complexity (how many tokens, how many instructions), task type (classification vs. reasoning vs. creative), required output quality (customer-facing vs. internal log), or explicit rules you set ("always use Opus for code review, always use Flash for status updates"). If you're still deciding which models belong in each tier, our guide to choosing the right LLM for your task walks through it in four questions.
The three ways to implement model routing
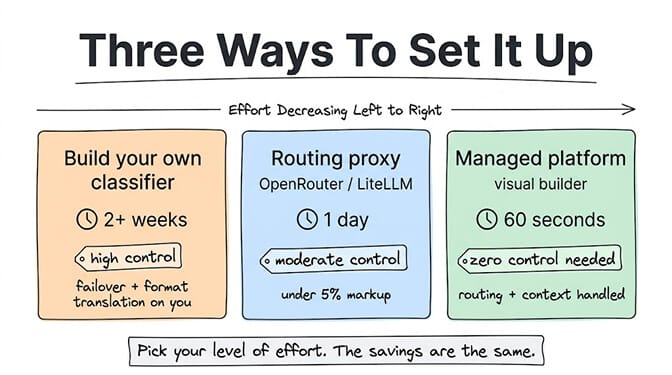
Option 1: Build your own classifier (2+ weeks, high control)
You write a lightweight classifier (often a cheap LLM call itself, or a rule-based system) that examines each request and decides which model should handle it.
Pros: Maximum control. Customized to your exact workload. No vendor dependency.
Cons: 2 to 4 weeks of engineering to build, test, and tune. Ongoing maintenance as models change. You need to handle failover, rate limiting, and format translation between providers yourself.
This is what engineering teams at companies like Notion and Figma do. If you have a dedicated ML engineer and thousands of dollars/month in AI spend to optimize, it's worth it. For a startup burning $200/month on tokens... probably not.
Option 2: Use a routing proxy (1 day, moderate control)
Services like OpenRouter and LiteLLM sit between your app and multiple LLM providers. You send requests to one endpoint, and the proxy routes them based on rules you configure.
Pros: Fast setup. Access to 200+ models through one API. Some auto-routing based on cost and capability.
Cons: Small markup on token costs (typically under 5%). Another service in your stack. You're still configuring routing rules manually.
For developers building custom applications, this is the sweet spot. If you're already managing your own agent infrastructure, adding OpenRouter takes a day and saves immediately.
Option 3: Use a platform that handles it natively (60 seconds, zero control needed)
This is where managed agent platforms come in. BetterClaw supports BYOK across 28+ model providers with zero inference markup. You paste API keys from different providers, assign models to different task types through the visual builder, and the platform handles routing. Smart context management prevents the token bloat that makes unoptimized agents 4 to 8x more expensive than they need to be. Per-agent cost caps stop runaway spending before it hits your credit card.
If the idea of building a routing classifier or managing a proxy sounds like engineering time you'd rather spend elsewhere, a managed platform eliminates that entire category of work. Free plan available, $49/month for Pro.
The hidden cost that routing alone can't fix: token bloat

Here's what most model routing articles leave out.
Routing sends each request to the right model. But if every request carries 20,000 tokens of context when it only needs 4,000, you're overpaying even on the cheap model.
This is the token bloat problem. Self-hosted agent frameworks (OpenClaw, CrewAI, LangGraph) typically send the full conversation history, all loaded skill instructions, and the complete system prompt with every single request. Even a simple "what time is it?" message costs 20K tokens of context plus 50 tokens of response.
On Claude Opus, that's $0.15 per "what time is it?" On DeepSeek V4 Flash with smart context management (only relevant history, only the active skill), it's $0.0006. That's a 250x difference for the same answer.
Model routing without context management is like switching to a fuel-efficient car but driving with the parking brake on. You save some money. You could save much more.
For a detailed breakdown of how context costs compound, our AI agent cost guide shows real monthly numbers across five use cases.
Real-world results: what routing actually saves
The community data is consistent. On r/openclaw and similar forums, developers who implement model routing report:
Before routing: $300 to $600/month in API costs for a single agent using Opus or GPT-4 for everything.
After routing (tiered models with context management): $20 to $60/month for the same agent doing the same work.
That's a 70 to 90% reduction. Not a theoretical projection. Actual bills, shared by actual users.
The pattern is always the same: Haiku or Flash for heartbeats and simple queries (fractions of a cent per request). Sonnet or GPT-5.4 for standard work (a few cents). Opus or GPT-5.5 reserved for genuinely complex tasks (used 10 to 20% of the time).
The teams that figure this out early run their agents 10x longer on the same budget compared to teams stuck on a single expensive model.
The three-tier setup that works for 90% of use cases

Here's the setup most teams converge on:
Tier 1 (50% of requests): Budget. DeepSeek V4 Flash at $0.14/$0.28, or Gemini Flash-Lite at $0.10/$0.40. For heartbeat checks, greetings, simple classification, formatting, and routing decisions.
Tier 2 (30% of requests): Production. Claude Sonnet 4.6 at $3/$15, GPT-5.4 at $2.50/$15, or Gemini 3.5 Flash at $1.50/$10. For email drafts, customer replies, search summaries, and most standard agent work.
Tier 3 (20% of requests): Frontier. Claude Opus 4.7 at $5/$25 or GPT-5.5 at $5/$30. For code generation, complex reasoning, multi-step analysis, and anything where the quality gap between production and frontier actually matters.
The key insight: most people start at Tier 3 and never leave. The fix is starting at Tier 1 and only escalating when needed.
If you can't tell the difference between the Tier 1 and Tier 3 output for a given task, use Tier 1. Your wallet will know the difference even if you can't.
The honest conclusion about model routing in 2026
Model routing isn't a hack or a trick. It's the natural evolution of how AI costs work. The price gap between the cheapest and most expensive models is now 535x (Amazon Nova Micro at $0.035 vs. GPT-5.5 at $30 on output). Using one model for everything across that range is like driving a semi-truck to pick up groceries. The full per-provider breakdown lives in our complete LLM pricing guide.
The companies that get this right run more agents, handle more volume, and build more ambitious workflows on the same budget. The companies that don't eventually hit a cost ceiling and either scale back or abandon the project entirely.
If you want to implement routing without building the infrastructure yourself, give BetterClaw a look. BYOK across 28+ model providers with zero inference markup. Assign different models to different task types through the visual builder. Smart context management prevents token bloat automatically. Per-agent cost caps stop runaway spending. Free plan with 1 agent and 500 credits a month. $49/month for Pro. Your first deploy takes about 60 seconds.
The cheapest AI isn't the cheapest model. It's the right model for each task. Model routing is how you get there.
Frequently Asked Questions
What is model routing in AI?
Model routing is a technique where a layer between your application and LLM providers analyzes each request and sends it to the cheapest model that can handle it well. Simple tasks (classification, greetings, formatting) go to budget models ($0.10-0.50/M tokens). Complex tasks (reasoning, coding, analysis) go to frontier models ($5-25/M). This typically reduces AI API costs by 70 to 90% without reducing output quality.
How does model routing compare to just using a cheaper model for everything?
Using one cheap model for everything saves money but sacrifices quality on complex tasks. Model routing gives you the best of both: cheap models where quality doesn't matter, expensive models where it does. A routed setup typically costs 60-80% less than an all-frontier setup while maintaining identical quality on every task, because the frontier model still handles the hard 20%.
How do I set up model routing for my AI agent?
Three options. DIY: build a classifier that categorizes requests and routes them (2+ weeks of engineering). Proxy: use OpenRouter or LiteLLM as a routing layer (1 day setup). Managed platform: use BetterClaw or similar platforms where you assign different models to different skills and task types through a visual builder (60 seconds). For most teams, the managed approach saves the most time.
How much can model routing save on my AI API bill?
Typical savings are 70 to 90%. A single agent running Claude Opus for everything costs $300 to $600/month. The same agent with three-tier routing (DeepSeek Flash for simple tasks, Sonnet for standard work, Opus for complex reasoning) costs $20 to $60/month. The exact savings depend on your request volume and the ratio of simple to complex tasks. Most agents are 50-80% simple tasks.
Does model routing reduce the quality of AI responses?
No, when done correctly. The key is routing by task complexity, not randomly. A budget model handling "what's on my calendar?" produces the same result as a frontier model. A frontier model handling a complex code review produces a much better result than a budget model. Routing matches capability to need. You only lose quality if you route a complex task to a model that can't handle it, which is why fallback rules matter.