

M3 costs $0.60 per million tokens. Sonnet costs $3. M3 has a 1-million-token context window. Sonnet has 200K. But Sonnet's tool calling is still the most reliable in the industry. Here's when the price difference matters and when it doesn't.
We ran both models on the same support agent for a week. Same system prompt. Same tool definitions. Same customer emails.
MiniMax M3 classified 94% of tickets correctly. Claude Sonnet 4.6 classified 97%.
M3 cost $18 for the week. Sonnet cost $89.
Is that 3% accuracy gap worth $71?
For a low-stakes email triage agent, no. For a healthcare intake agent where misclassification has consequences, absolutely. That's the entire MiniMax M3 vs Claude Sonnet 4.6 decision in one scenario. The question isn't which model is better. It's whether the quality premium justifies the cost premium for YOUR specific agent.
Here's the full breakdown.
The verdict (don't make me scroll for it)
MiniMax M3 is the better choice for high-volume, cost-sensitive agents that handle structured tasks, long documents, or multimodal input (images, video). It's 5x cheaper on input and delivers strong performance on coding, browsing, and sustained agentic workflows.
Claude Sonnet 4.6 is the better choice for agents that need precise instruction following, reliable tool calling, nuanced reasoning, or customer-facing output quality. It costs more and justifies it on the tasks where getting it right matters more than getting it cheap.
The smart play: Use M3 as your default for volume work and Sonnet for precision work. Route between them based on the task.
Price: M3 is 5x cheaper on input, 6x cheaper on output
MiniMax M3: $0.60/M input, $2.40/M output. Promotional pricing at $0.30/M input available at launch.
Claude Sonnet 4.6: $3/M input, $15/M output. Cached input: $0.30/M (90% discount).
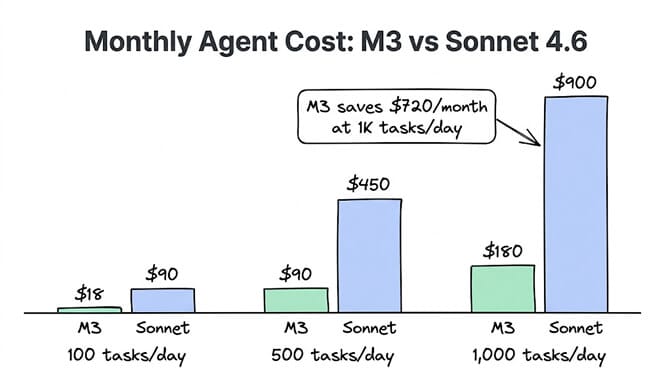
The gap: 5x on input, 6.25x on output. For an agent processing 500 tasks per day at 10,000 tokens per task, the monthly difference is roughly $90 (M3) vs $450 (Sonnet). That's $360/month per agent, or $4,320/year. For how M3 lands against the rest of the budget field, see our cheapest AI providers guide.
With prompt caching, Sonnet narrows the gap on input ($0.30/M cached vs M3's $0.60/M standard). But output is never cached, and Sonnet's output at $15/M is over 6x M3's $2.40/M. For agents that generate long responses (reports, emails, summaries), output cost dominates, and M3 wins decisively.
For every $1 you spend on MiniMax M3, you'd spend $5-6 on Sonnet for the same token volume. On output-heavy agents, the gap is even wider.
Context window: M3 wins by 5x
MiniMax M3: 1,000,000 tokens (1M). Powered by MiniMax Sparse Attention (MSA). Guaranteed minimum of 512K tokens.
Claude Sonnet 4.6: 200,000 tokens (200K).
This is the biggest architectural difference. M3 can hold an entire codebase, a 400-page document, or hours of conversation history in a single context window. Sonnet can't.
For agents that process long documents (legal contracts, research papers, codebases), M3's 1M context eliminates the need for chunking, summarization, or RAG retrieval. The entire document fits. The agent sees everything at once.
For agents that handle short interactions (support tickets, email triage, CRM updates), 200K is more than enough and the context window advantage doesn't matter.
Speed: M3 is faster for most workloads
MiniMax M3 is built for speed on long-horizon tasks. The MSA architecture processes long contexts efficiently, and the model is optimized for sustained autonomous work over hours.
Sonnet 4.6 runs at approximately 50-80 tok/s depending on provider and load.
For latency-sensitive agents (real-time customer chat, interactive assistants), M3's speed advantage translates to noticeably faster responses. For scheduled background agents (daily reports, batch processing), speed differences are irrelevant.
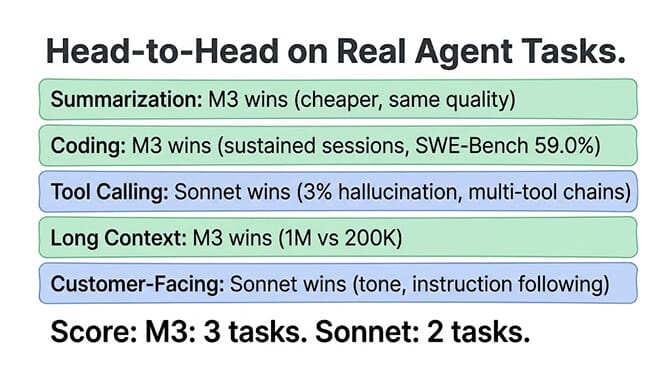
Head-to-head on 5 real agent tasks
Task 1: Summarization
Feed both models a 50,000-token document and ask for a 500-word executive summary.
M3 wins. The 1M context window means M3 ingests the entire document without truncation. Sonnet handles 50K fine within its 200K window, but M3 does it at one-fifth the cost. Summary quality is comparable for factual content.
Task 2: Coding
Both are strong. M3 scores 59.0% on SWE-Bench Pro (beating GPT-5.5's 58.6% and approaching Opus 4.7's 64.3%). Sonnet 4.6 is competitive but Opus-tier is Anthropic's coding strength, not Sonnet-tier.
M3 wins on sustained coding sessions. It's designed for 8+ hour autonomous coding runs. (For a three-way view, see our MiniMax M3 vs GLM vs Claude breakdown.) Sonnet is better for short, precise code edits where instruction following matters more than endurance.
Task 3: Tool calling
This is where Sonnet pulls ahead. Claude Sonnet 4.6 has a 3% tool-call hallucination rate, the lowest measured among frontier models. It picks the right tool, formats the right arguments, and handles multi-tool chains with high reliability.
M3 supports tool calling and scored well on agentic benchmarks (BrowseComp 83.5, beating Opus 4.7's 79.3 on browsing tasks). But for complex multi-tool chains where one wrong tool call cascades into a workflow failure, Sonnet's precision is measurably better.
Sonnet wins. For agents that chain multiple tool calls (check CRM -> draft email -> schedule meeting -> update pipeline), Sonnet's lower hallucination rate means fewer failed workflows.
Task 4: Long context processing
M3 wins by default. 1M tokens vs 200K. If your agent needs to process anything over 200K tokens (large codebases, multi-document research, extended conversation histories), M3 is the only option. Sonnet physically cannot hold the data.
Task 5: Customer-facing responses
Feed both models a customer complaint and ask for a response matching a brand voice guide.
Sonnet wins. Anthropic's instruction following produces more natural, empathetic, brand-consistent output. M3's responses are competent but less nuanced on tone calibration. For external communications where tone matters (support replies, sales follow-ups, client reports), Sonnet justifies the premium.
MiniMax M3 strengths (the surprising parts)
Multimodal native. M3 handles text, images, and video in the same model. Sonnet handles text and images. If your agent needs to process video content (product demos, meeting recordings, surveillance footage), M3 is your only option in this price bracket.
Open weights. MIT license. You can download the model and self-host (with serious hardware). Sonnet is proprietary. For teams with data sovereignty requirements or compliance needs that prohibit sending data to third-party APIs, M3's open-weight availability is a structural advantage. If you want another open-weight option benchmarked against Sonnet, see our GLM 5.2 vs Sonnet 4.6 head-to-head.
BrowseComp 83.5. M3 scored higher than Opus 4.7 (79.3) on complex browsing tasks. For agents that need to research, browse, and synthesize information from multiple web sources, M3 is surprisingly capable.
Sonnet 4.6 strengths (the things you actually pay for)
3% tool-call hallucination rate. The lowest measured. When your agent calls 10 tools per workflow and runs 100 workflows per day, the difference between 3% and 7% hallucination is 40 fewer failed workflows per day. That's not a benchmark number. That's real production impact.
Instruction following. Tell Sonnet "never mention competitor products" and it follows the instruction. Tell it "always use formal tone except when the customer uses informal language" and it handles the conditional. M3 follows instructions well but not with Sonnet's consistency on complex, conditional rules.
The Anthropic ecosystem. Prompt caching (90% discount), extended thinking mode, native tool calling format, and the broadest MCP support. If your stack is Anthropic-native, Sonnet 4.6 is the path of least resistance.
Both models work on BetterClaw with zero config changes to switch between them. 28+ providers via BYOK. Pick MiniMax from the dropdown for your volume agent. Pick Sonnet for your precision agent. Same platform. Same integrations. Same 200+ skills. Free plan with 1 agent and 500 credits a month. $49/month on Pro. Zero inference markup.
Who should use which
Use MiniMax M3 when:
Budget is a factor and you're processing high volume. At $0.60/M vs $3/M, the savings compound fast across thousands of daily tasks.
Your agent handles long documents, large codebases, or extended research sessions. The 1M context window is not available on Sonnet at any price.
You need multimodal (especially video). M3 is one of the few models that process video natively.
You're exploring open-weight deployment. MIT license, weights on HuggingFace.
Use Sonnet 4.6 when:
Tool calling reliability is critical. 3% hallucination vs higher rates means fewer production failures on multi-tool workflows.
Customer-facing output quality matters. Tone, empathy, brand voice consistency.
You're already in the Anthropic ecosystem. Prompt caching, extended thinking, native MCP.
The task involves nuanced judgment, not just execution. Complex reasoning, conditional logic, ambiguous instructions.
The model market in 2026 is not about finding "the best model." It's about finding the right model for the right task at the right price. MiniMax M3 at $0.60/M is an extraordinary value for structured, high-volume, long-context agent work. Sonnet 4.6 at $3/M is worth every token for precision, reliability, and customer-facing quality.
The teams building the best agents in 2026 use both. They route. They match the model to the task. They don't overpay on email triage and they don't underspend on customer communication.
Give BetterClaw a look if you want both models available from one dashboard. Switch between M3 and Sonnet 4.6 with a dropdown. Free plan with 1 agent and 500 credits a month. $49/month for Pro. We handle the model routing. You handle the agent logic.
Frequently Asked Questions
How does MiniMax M3 compare to Claude Sonnet 4.6 for AI agents?
MiniMax M3 is 5x cheaper ($0.60/M vs $3/M input), has a 5x larger context window (1M vs 200K), and supports native video input. Claude Sonnet 4.6 has the lowest tool-call hallucination rate (3%), stronger instruction following, and better customer-facing output quality. M3 wins on volume, cost, and long-context tasks. Sonnet wins on precision, tool reliability, and nuanced reasoning. Most production agent setups benefit from using both with task-based routing.
Is MiniMax M3 reliable enough for production agents?
Yes, with the right task match. M3 scored 59.0% on SWE-Bench Pro (beating GPT-5.5) and 83.5 on BrowseComp (beating Claude Opus 4.7). It handles structured extraction, summarization, coding, and browsing tasks reliably. For multi-tool chains where a single wrong tool call causes cascading failures, Sonnet 4.6's lower hallucination rate makes it the safer choice. The recommendation: use M3 for volume work, Sonnet for high-stakes tool chains.
How much can I save switching from Sonnet 4.6 to MiniMax M3?
For a typical agent at 500 tasks/day: Sonnet costs approximately $450/month, M3 costs approximately $90/month. That's $360/month savings per agent, or $4,320/year. The savings scale linearly with volume. At 1,000 tasks/day, you save $720/month. The key: switch only tasks where M3 matches quality (summarization, extraction, coding, long context), keep Sonnet for tasks where precision matters (customer communication, complex tool chains, safety-critical workflows).
Can MiniMax M3 handle tool calling and function calling?
Yes. M3 supports native tool calling and scored 83.5 on BrowseComp (a benchmark for complex, multi-step browsing tasks requiring tool use). It handles structured tool schemas, argument formatting, and result parsing. The limitation compared to Sonnet is reliability on complex multi-tool chains. Sonnet's 3% hallucination rate means it picks the right tool more consistently when many tools are available. For single-tool or simple two-tool workflows, M3 is comparable.
Does MiniMax M3 support video and image input?
Yes. MiniMax M3 natively processes text, images, and video in the same model, powered by its MSA (MiniMax Sparse Attention) architecture. Claude Sonnet 4.6 supports text and images but not video. If your agent needs to analyze video content (product demos, meeting recordings, visual inspections), M3 is the only option in this price range. For text-only or text-plus-image agents, both models work well.



