
Stop reading benchmark tables. Start here instead. A decision-first guide to picking the right model for your actual use case and budget.
Last month I watched two founders have the exact same argument in a Slack group. One had just switched from Claude to GPT-5.5 and was raving about the tool-calling ecosystem. The other had switched from GPT-5.5 to DeepSeek V4 Pro and couldn't believe they'd been overpaying by 60x.
Both were right. Both were wrong. They were building completely different things.
This is the core problem with every "GPT vs Claude" comparison you've read. They rank models on benchmarks and declare a winner. But the model that scores 87.6% on SWE-Bench isn't automatically the right model for your customer support agent. And the model that costs $0.14 per million tokens isn't automatically wrong for your coding workflow.
The question isn't which model is best. It's which model is best for what you're building.
This guide is structured by decision, not by model. Find your use case. Get your answer. Move on. Bookmark this page because we update it every time a major model drops.
Last updated: June 1, 2026.
If you need the best coding agent: Claude Opus 4.7

Claude Opus 4.7 leads SWE-Bench Verified at 87.6%. That's not a number you ignore. In practice, it means Opus correctly resolves more real GitHub issues than any other model. For coding agents that review PRs, fix bugs, refactor modules, or write tests, Opus is the current best.
The pricing: $5.00 input / $25.00 output per million tokens. 1,000,000-token context window at flat pricing (no surcharges for long context).
Where it shines: Complex multi-file edits. Long-document understanding. Following nuanced instructions precisely. The 1M context at flat rate is significant because you can load an entire codebase without worrying about tiered pricing kicking in.
Where it falls short: It's not the cheapest frontier option. The new tokenizer in Opus 4.7 generates up to 35% more tokens for the same input text compared to Opus 4.6. So your per-request cost can be higher than the rate card suggests even though the per-token price didn't change. Benchmark before migrating from older Claude models.
Also: extended thinking tokens are billed as output ($25/M), and Opus 4.7 hides thinking content by default. You might be paying for reasoning you never see unless you explicitly opt in.
The honest verdict: If code quality is your #1 priority and you can absorb the cost, Opus 4.7 is the best in class. If you need near-Opus quality at 40% lower cost, Claude Sonnet 4.6 ($3/$15) is the production default most teams should use. (For the head-to-head on just the two biggest labs, see our OpenAI vs Anthropic pricing breakdown.)
If you need the broadest agent capabilities: GPT-5.5
GPT-5.5 is OpenAI's current flagship. It launched in late April 2026 with a 2x price increase over GPT-5.4.
The pricing: $5.00 input / $30.00 output per million tokens. 1,050,000-token context window. Cached input: $0.50/M (90% off). Batch: 50% off.
GPT-5.5 is the most expensive model on output ($30/M vs. Claude's $25/M). But it has something nobody else matches: the widest tool-calling and integration ecosystem in the market. OpenAI's function calling is the de facto standard. Most third-party tools, SDKs, and frameworks were built OpenAI-first. If your agent needs to call 15 different APIs through complex multi-step orchestration, GPT-5.5's tool ecosystem is the most battle-tested.
Where it shines: Multi-step agentic workflows. Broad tool integration. The largest developer ecosystem means more examples, more libraries, and faster debugging.
Where it falls short: The $30/M output cost is the highest of any frontier model. The context window charges a surcharge above 272,000 tokens (applied to the entire session, not just the overage). And hidden reasoning tokens are billed as output without appearing in the response, which means a 500-token reply can cost you 2,000+ tokens.
GPT-5.5 is the safest default if you don't know what you need yet. It's also the most expensive default if you never revisit the choice.
If cost matters and you don't need 5.5 specifically, GPT-5.4 at $2.50/$15.00 is half the price with 90% of the capability for production workloads. And GPT-5.4 Nano at $0.20/$1.25 is there for the simple stuff.
If you need frontier quality on a budget: DeepSeek V4 Pro
Here's where the comparison gets uncomfortable for the incumbents.
DeepSeek V4 Pro scores 80.6% on SWE-Bench Verified. Claude Opus scores 87.6%. That's a 7-point gap. Not nothing. But look at the pricing.
The pricing: $0.435 input / $0.87 output per million tokens (permanent price after May 31 promo ends). Cache hit input: $0.003625/M. Context: 1,000,000 tokens. 384K max output.
For the same 500-interaction-per-day agent, GPT-5.5 costs $600/month. DeepSeek V4 Pro costs $26/month. Claude Opus costs roughly $500/month.
Is Claude 7 points better on SWE-Bench? Yes. Is it $474/month better for your email triage agent? Almost certainly not.
Where it shines: Any use case where the cost-per-token math matters more than squeezing out the last 5% of quality. High-volume agents. Startups watching burn. Teams that need multiple agents running simultaneously and can't afford $500/agent/month in API costs.
Where it falls short: Tool-calling format compatibility can be inconsistent compared to OpenAI's de facto standard. Creative writing and nuanced conversation are weaker than Claude. And there are legitimate concerns about data routing through Chinese infrastructure that matter for some regulated industries.
The budget option below this: DeepSeek V4 Flash at $0.14/$0.28 per million tokens. That's the cheapest frontier-capable model in existence. Cache hits at $0.0028/M. For high-volume extraction, classification, and routing tasks, nothing touches it on price. (For more budget picks ranked, see our cheapest AI providers guide.)
If you need speed above everything: Gemini 3.5 Flash

Speed isn't just a nice-to-have. For real-time agents, chat interfaces, and latency-sensitive applications, the model that thinks for 8 seconds is worse than the model that thinks for 2 seconds, even if the 8-second answer is slightly better.
The pricing: $1.50 input / $10.00 output per million tokens. Context: 1,000,000 tokens. Output speed: 289 tokens/second.
Gemini 3.5 Flash beats the previous Gemini Pro model on coding benchmarks while running 4x faster. That's the kind of efficiency gain that changes what's possible. An agent that responds in under 2 seconds feels like a colleague. One that responds in 8 seconds feels like a loading screen.
Where it shines: Any agent that talks to humans in real-time. Chat support, interactive assistants, voice-to-text pipelines, applications where perceived speed matters as much as accuracy.
Where it falls short: Not the strongest on complex multi-step reasoning. The output price ($10/M) isn't cheap. Google's "compute-based" usage limits can be unpredictable.
The free tier: Google offers 1,000 requests/day at no cost on Gemini Flash models. If your agent's traffic fits inside that, your monthly bill is $0. Zero. That's the most generous free tier from any major provider.
This is the right spot to mention something that makes all of this simpler. BetterClaw supports BYOK across all of these providers with zero inference markup. You paste your DeepSeek key for budget tasks, your Claude key for coding tasks, and your Gemini key for speed-critical tasks. All in the same agent. Switch models without rebuilding anything. Free plan available, $49/month on Pro.
If you need the biggest context window: Grok 4.3

Grok 4.3 from xAI has a 2,000,000-token context window. That's 2x the nearest competitor.
The pricing: $0.20 input / $0.60 output per million tokens. Also available free through a SuperGrok subscription ($30/month flat) which includes voice, image generation, video generation, and X search.
At $0.20/M input for 2M tokens of context, the cost-per-context-token ratio is the best in the market by a wide margin.
Where it shines: Entire codebase analysis. Processing extremely long documents (legal contracts, research papers, full book manuscripts). Conversation histories that span days or weeks without summarization. Any task where you need the model to see everything at once.
Where it falls short: Benchmark performance trails Claude and GPT-5.5 on coding and complex reasoning. The SuperGrok OAuth integration with frameworks like Hermes has known streaming bugs (see our Grok-Hermes setup guide for workarounds). xAI's ecosystem is smaller than OpenAI's or Anthropic's.
If you need the absolute cheapest: Amazon Nova Micro
Amazon Nova Micro costs $0.035 input / $0.14 output per million tokens. That's the cheapest model from any major cloud provider.
Where it shines: High-volume simple tasks inside the AWS ecosystem. Classification, tagging, routing, extraction. Tasks where you need a model but the model barely needs to think.
Where it falls short: Not a frontier model. Don't use it for reasoning, coding, or creative work. It's a calculator, not a colleague.
For non-AWS teams, DeepSeek V4 Flash ($0.14/$0.28) or Google Gemini 3.1 Flash-Lite ($0.10/$0.40) are comparable budget options without AWS lock-in.
The comparison table you'll actually use
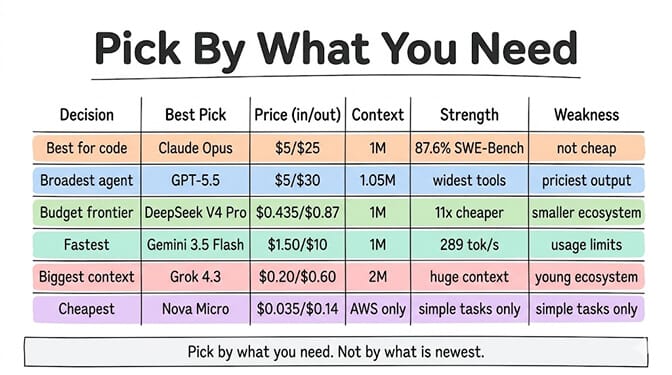
Best for coding agents: Claude Opus 4.7. $5/$25. 87.6% SWE-Bench. 1M context flat.
Broadest agent ecosystem: GPT-5.5. $5/$30. Widest tool-calling support. 1.05M context (surcharge above 272K).
Budget frontier quality: DeepSeek V4 Pro. $0.435/$0.87. 80.6% SWE-Bench. 1M context. 11x cheaper than Opus on output.
Fastest responses: Gemini 3.5 Flash. $1.50/$10. 289 tok/s. Free tier (1,000 req/day). 1M context.
Biggest context window: Grok 4.3. $0.20/$0.60. 2M tokens. Free via SuperGrok ($30/mo).
Absolute cheapest: Amazon Nova Micro. $0.035/$0.14. AWS only. Simple tasks only.
Best production default: Claude Sonnet 4.6. $3/$15. Near-Opus quality, 40% cheaper, 1M context. This is what most agent builders should start with.
If you want a structured way to map these models to your own workload, our four-question LLM selection framework does exactly that.
Where every model falls short (the part nobody writes)
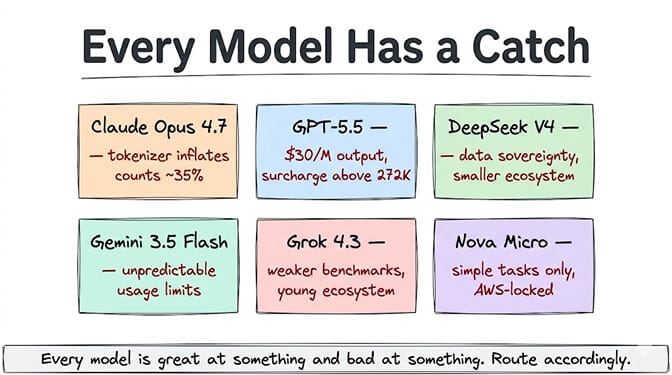
Claude Opus 4.7: New tokenizer inflates token counts by up to 35%. Extended thinking billed as output but hidden by default. Not cheap.
GPT-5.5: Most expensive output token in the market ($30/M). Context surcharges above 272K tokens. Hidden reasoning tokens inflate bills. 2x price increase over GPT-5.4 that many developers are still unhappy about.
DeepSeek V4: Tool-calling format can differ from OpenAI's standard. Data sovereignty concerns for regulated industries. Smaller developer ecosystem means fewer examples and community support.
Gemini 3.5 Flash: Google's "compute-based" usage limits are unpredictable. Some users report hitting the 5-hour restriction window after a handful of prompts. Pricing tiers based on prompt length add complexity.
Grok 4.3: Smaller benchmark scores than competitors on coding and reasoning. xAI ecosystem is young. SuperGrok OAuth has documented streaming bugs.
Nova Micro: Not suitable for anything beyond simple extraction and classification. AWS-locked.
Every model is great at something. Every model is bad at something. The teams that win pick 2-3 models and route tasks to the right one.
The real answer: use more than one
The model landscape in 2026 has a 535x price gap between the cheapest and most expensive options. Using one model for everything is like driving a forklift to the grocery store. It works. It's just wildly inefficient. For the full per-provider rate card, see our complete LLM pricing guide.
The best teams use a tiered approach: cheap models ($0.10-$0.50/M) for simple tasks. Production models ($1-3/M) for most workloads. Frontier models ($5+/M) for the hard 10-20%. We break down exactly how to wire this up in our model routing guide.
This is exactly what BYOK was designed for. On BetterClaw, you paste keys from different providers, assign models to different skills and workflows, and the platform handles routing. Smart context management prevents the token bloat that makes self-hosted agents 4-8x more expensive than they need to be. Per-agent cost caps make sure nothing runs away.
Free plan with 1 agent and 500 credits a month. $49/month for Pro. 28+ model providers. Zero inference markup. Your first deploy takes about 60 seconds.
The model that wins in 2026 isn't the one with the highest benchmark. It's the one you can swap out when something better shows up next month. And something better always shows up next month.
Frequently Asked Questions
What is the best AI model in 2026 for building agents?
There's no single best. Claude Opus 4.7 leads coding benchmarks (87.6% SWE-Bench). GPT-5.5 has the broadest tool-calling ecosystem. DeepSeek V4 Pro delivers 80.6% SWE-Bench quality at 11x lower cost than Opus. For most production agent workloads, Claude Sonnet 4.6 ($3/$15 per million tokens) offers the best balance of quality, speed, and cost.
How does GPT-5.5 compare to Claude Opus 4.7 for coding?
Claude Opus 4.7 leads on SWE-Bench Verified (87.6% vs. GPT-5.5's ~82%). However, GPT-5.5 has a larger tool-calling ecosystem and broader SDK support. Opus is the better model for pure code generation and complex multi-file edits. GPT-5.5 is better when your coding agent needs to integrate with many external tools. Opus costs $5/$25 per MTok. GPT-5.5 costs $5/$30, making Opus cheaper on output.
How much cheaper is DeepSeek V4 than GPT-5.5?
Dramatically cheaper. DeepSeek V4 Flash costs $0.14/$0.28 per million tokens vs. GPT-5.5's $5/$30. That's roughly 35x cheaper on input and 107x cheaper on output. For a 500-interaction/day agent, GPT-5.5 costs ~$600/month while DeepSeek V4 Flash costs ~$8/month. DeepSeek V4 Pro ($0.435/$0.87) is the better comparison for frontier quality, running about 11x cheaper than Claude Opus on output with competitive coding benchmarks.
Is DeepSeek safe to use for production AI agents?
DeepSeek V4 supports tool calling, JSON output, 1M context, and OpenAI-compatible API endpoints. It's a real production model. The main concern is data sovereignty: DeepSeek is a Chinese company, and requests route through Chinese infrastructure. For regulated industries (healthcare, finance, government), this may be a compliance issue. For general business use, performance and pricing are competitive with Western alternatives. BetterClaw supports DeepSeek via BYOK with zero markup, so you can test it risk-free on non-sensitive workloads.
Can I use multiple AI models in the same agent?
Yes. Platforms like BetterClaw support BYOK across 28+ model providers. You can assign different models to different tasks within the same agent: a cheap model for simple classification, a mid-tier model for most interactions, and a frontier model for complex reasoning. This model routing approach typically cuts AI costs by 70-90% compared to using a single expensive model for everything.



