

M3 costs 5% of Claude Opus per task. GLM-5.1 topped SWE-Bench Pro. But benchmarks and agent workloads are not the same thing. Here's the real math.
Our ops lead sent me a cost spreadsheet last week. We'd been running a 6-step email triage agent on Claude Sonnet 4.6. Reliable. Fast. Accurate. Also $47/day in API costs at our volume.
Then MiniMax M3 launched on June 1. Same task. Same volume. Projected cost: $2.80/day.
Ninety-four percent cheaper. Same 1-million-token context window. Tool calling support. Benchmarks claiming to approach Claude Opus 4.7 on coding. The internet lost its mind.
But here's what nobody asked in the hype cycle: does it actually hold up when an agent calls tools 200 times a day, accumulates context over multi-turn conversations, and needs to follow complex system prompt instructions for weeks without drifting?
Because MiniMax M3 isn't competing in a benchmark. It's competing against Claude Sonnet and GLM-5.1 in production agent workloads. And that's a completely different test.
Here's the side-by-side, with the numbers that matter for agents.
The pricing table nobody shows you

Let me put the raw numbers on the table first. These are verified as of June 2026.
MiniMax M3: $0.60 per million input tokens, $2.40 per million output tokens (standard API). OpenRouter is running a temporary 50% launch promo at $0.30/$1.20, but that expires without a defined end date. Budget on the standard rate. Context window: 1 million tokens.
GLM-5.1: $0.98 per million input tokens, $3.08 per million output tokens via the cheapest provider. Context window: 203,000 tokens. Released April 7, 2026, by Z.ai (formerly Zhipu AI). 754B total parameters, 40B active per forward pass (MoE architecture). MIT license.
GLM-5 (base): $0.57-0.60 per million input tokens, $1.92-2.08 per million output tokens. Same 200K context. Slightly weaker on coding benchmarks but 40-75% cheaper than GLM-5.1.
Claude Sonnet 4.6: $3.00 per million input tokens, $15.00 per million output tokens. Context window: 200,000 tokens. Prompt caching available (reduces repeated context costs by 80-90%).
Claude Opus 4.8: $5.00 per million input tokens, $25.00 per million output tokens. Context window: 1 million tokens.
Now the math that matters. For a task requiring 500,000 input tokens and 100,000 output tokens:
- MiniMax M3 at standard pricing: $0.54. At promo: $0.27.
- GLM-5.1: $0.80.
- Claude Sonnet 4.6 without caching: $3.00. With prompt caching (typical agent setup where 80% of input is repeated): approximately $0.90.
- Claude Opus 4.8: $5.00.
MiniMax M3 is 5-18x cheaper than Claude depending on model tier and caching. But the cheapest model isn't always the cheapest agent. Tool call failures, retries, and hallucinations add hidden token costs.
The benchmarks everyone's quoting (and what they miss for agents)
MiniMax M3
59.0% on SWE-Bench Pro. 66.0% on Terminal-Bench 2.1. 83.5 on BrowseComp. 74.2% on MCP Atlas. These are frontier-class numbers. MiniMax claims M3 surpasses GPT-5.5 and Gemini 3.1 Pro on coding benchmarks and approaches Claude Opus 4.7.
The architecture is genuinely interesting. MiniMax Sparse Attention (MSA) cuts per-token compute at 1M context to one-twentieth of the previous generation. That's how they offer a million-token context window at this price. If it works as claimed, it explains the pricing without assuming they're running at a loss.
GLM-5.1
Topped SWE-Bench Pro outright, beating GPT-5.4 and Claude Opus 4.6. 94.6% of Claude Opus 4.6's coding performance. BrowseComp 68.0%, MCP-Atlas 71.8%. Independently verified at 1530 Elo on Code Arena (3rd globally on the agentic webdev leaderboard).
Z.ai claims GLM-5.1 can autonomously maintain goal alignment for up to 8 hours per task across thousands of tool calls. The "from vibe coding to agentic engineering" positioning is deliberate. This model was designed for long-running agent sessions.
Claude Sonnet 4.6
We covered this in depth in our Claude vs GPT-4o comparison. The headline numbers: 3% tool call hallucination rate. Maintains instruction following at 150K+ tokens where GPT-4o degrades past 100K. ~95% coding accuracy. Preferred 47% in blind evaluations versus 29% for GPT-5.4.
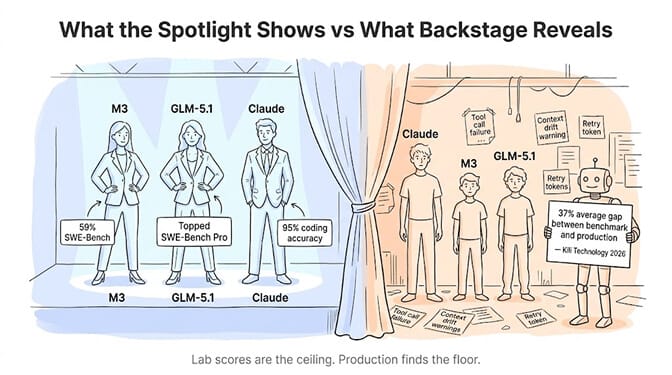
The benchmark-to-production gap
Here's the number that should make you pause. Kili Technology, which runs production AI evaluations, found in 2026 that enterprise agentic AI systems show a 37% average gap between lab benchmark scores and real-world deployment performance.
SWE-Bench Pro tests one thing: can the model solve a specific software engineering task in a controlled environment. An agent workload tests dozens of things simultaneously: following a system prompt over hundreds of turns, calling the right tool with the right arguments, handling unexpected API responses, maintaining context, knowing when to escalate.
A model that scores 59% on SWE-Bench Pro might score 37% on your actual 6-step email agent. Or it might score 55%. The point is you don't know until you test it on YOUR workload.
What actually matters for agent workloads (the honest comparison)
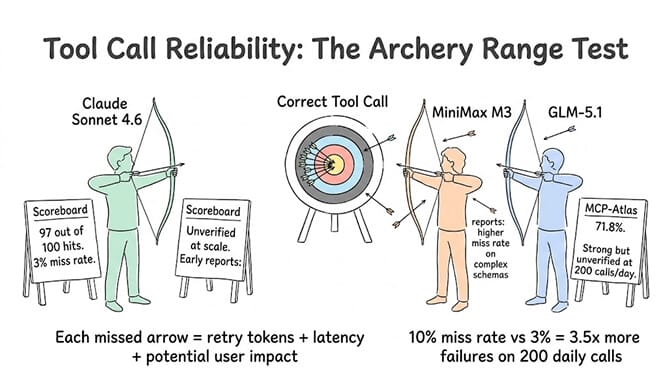
Tool calling reliability
This is where cheap models fall apart in agent workloads. Claude Sonnet's 3% hallucination rate on tool calls means 6 failures out of 200 daily calls. Manageable.
MiniMax M3 and GLM-5.1 haven't been independently benchmarked on tool call hallucination at the same rigor. Early reports on M3 suggest tool calling works but with higher error rates on complex schemas, especially multi-parameter functions. GLM-5.1's MCP-Atlas score of 71.8% versus M3's 74.2% gives directional guidance, but MCP-Atlas tests model capability, not production reliability over thousands of calls.
If your agent makes 200 tool calls per day and the hallucination rate is 10% instead of 3%, that's 20 failures versus 6. Each failure requires a retry (more tokens, more cost, more latency) or manual intervention. The "cheaper" model may not be cheaper once you account for failure costs.
Long context handling
M3 has a clear advantage here: 1 million tokens versus 200K for GLM-5.1 and Claude Sonnet. For agents that process long documents, accumulate extensive conversation history, or need to hold large tool definition sets, M3's context window is genuinely meaningful.
But context window size and context quality are different things. Claude maintains attention quality across its full 200K window. Early M3 testing shows strong performance on long-context retrieval, but the "guaranteed minimum" of 512K (versus the claimed 1M) suggests some workloads may not hit the full window consistently.
Instruction following over time
Claude's Constitutional AI training makes it unusually good at maintaining system prompt adherence over extended conversations. This matters for agents that run for weeks with the same instructions.
GLM-5.1's "8-hour autonomous sessions" claim is impressive but untested at scale outside Z.ai's own evaluations. M3 is too new for longitudinal adherence data.
For agents where following instructions precisely is the difference between useful and dangerous (financial agents, customer-facing support, compliance workflows), Claude's track record is the safest choice today.
The recommendation per workload tier
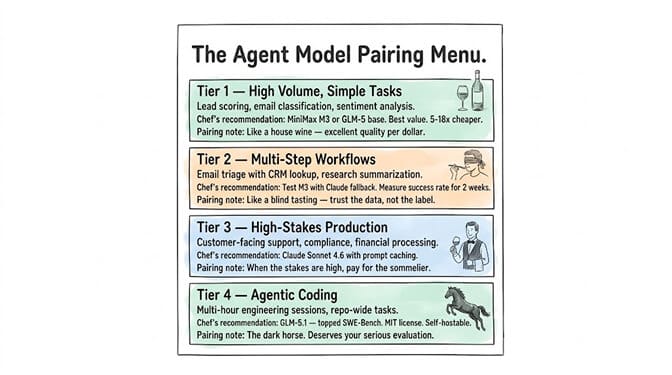
Tier 1: High-volume, simple tasks
Lead scoring. Email classification. Data extraction. Sentiment analysis.
Use MiniMax M3 (or GLM-5 base). These tasks are single-step, low-risk, and high-volume. The 5-18x cost advantage at this tier is massive. A classification agent that processes 10,000 items per day at $0.60/M tokens instead of $3.00/M saves over $1,000/month. Tool calling is minimal or absent. Instruction complexity is low.
Tier 2: Multi-step agent workflows
Email triage with CRM lookup. Support ticket resolution. Research summarization with tool calls.
Test MiniMax M3 with Claude Sonnet as fallback. Run M3 for 1-2 weeks. Measure tool call success rates, output quality, and total cost per resolved task (not per token). If M3's success rate is within 5% of Claude's, the cost savings justify the switch. If the gap is larger, use M3 for simple steps and route reasoning-heavy steps to Claude.
Tier 3: Complex, high-stakes agent workflows
Customer-facing support. Financial processing. Compliance-sensitive operations. Multi-hour autonomous sessions.
Use Claude Sonnet 4.6 (with prompt caching). The 3% tool call hallucination rate, proven instruction following at long context, and Constitutional AI discipline are worth the premium. Prompt caching closes the cost gap significantly for agent workloads where 80%+ of input is repeated context. At $0.90 per cached task versus $0.54 for M3, you're paying 67% more for substantially higher reliability.
Tier 4: Agentic coding and long-session engineering
Autonomous code generation. Multi-hour software engineering tasks. Repository-wide refactoring.
GLM-5.1 deserves serious evaluation. It topped SWE-Bench Pro. It's designed for extended agentic sessions. The MIT license and open weights mean you can self-host if data sovereignty matters. At $0.98/M input, it's 67% cheaper than Claude Sonnet on input tokens. The 28% coding improvement from GLM-5 to 5.1 came from post-training alone, suggesting the ceiling hasn't been reached.
This is exactly the kind of model routing decision that platforms should handle for you. On BetterClaw, you can assign different models to different agents. Run M3 for your high-volume classification agent. Run Claude for your customer-facing support agent. Run GLM-5.1 for your coding agent. 28+ providers, BYOK, zero markup. Switch models with a dropdown. Free plan with 1 agent and 500 credits a month. $49/month on Pro.
The honest bottom line
MiniMax M3 is real. The pricing is real. The benchmarks are real. For high-volume, simple agent tasks, it's the clear cost winner and a serious option. If you want the focused two-model read, our MiniMax M3 vs Claude Sonnet 4.6 comparison runs them head-to-head.
GLM-5.1 is the dark horse for agentic coding. Topping SWE-Bench Pro with open weights and MIT license is a genuine achievement. For teams building autonomous coding agents or doing extended engineering sessions, it deserves your evaluation time. (Its successor pushes further — our GLM 5.2 vs Sonnet 4.6 test covers the gains.)
Claude Sonnet remains the safest choice for production agents where reliability, instruction following, and tool-call accuracy matter more than per-token cost. With prompt caching, the cost gap narrows significantly.
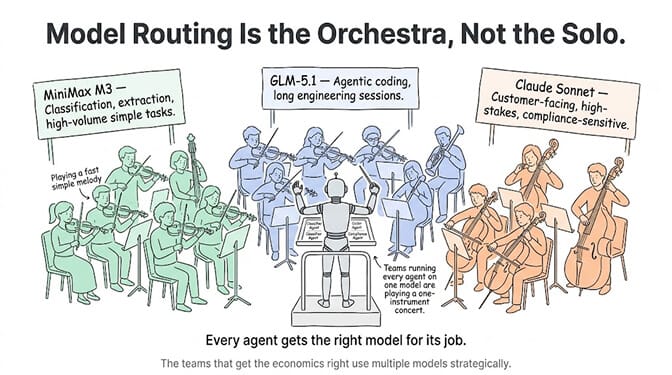
The real insight from this comparison isn't "which model is best." It's that model routing is the correct architecture for 2026. Different agents deserve different models based on their specific workload. The teams still running every agent on a single model are overpaying for simple tasks and under-resourcing complex ones.
Gartner projects 40% of enterprise applications will embed AI agents by end of 2026. The ones that get the economics right will use multiple models strategically. The ones that don't will either spend too much or ship unreliable agents.
Give BetterClaw a look if model routing matters to you. Free plan with 1 agent and 500 credits a month. $49/month for Pro. 28+ providers. Switch models per agent with a dropdown. We handle the provider abstraction. You handle the strategy.
Frequently Asked Questions
What is MiniMax M3 and why does it matter for AI agents?
MiniMax M3 is a multimodal foundation model released June 1, 2026, by Shanghai-based MiniMax. It supports a 1-million-token context window using a novel sparse attention architecture (MSA) that cuts per-token compute to one-twentieth of the previous generation. It matters for agents because it offers frontier-class benchmarks (59% SWE-Bench Pro, 74.2% MCP Atlas) at $0.60/M input tokens, which is 5x cheaper than Claude Sonnet and 8x cheaper than Claude Opus.
How does MiniMax M3 compare to Claude for agent tool calling?
Claude Sonnet 4.6 has a verified 3% tool call hallucination rate in 30-day production testing. MiniMax M3 hasn't been independently benchmarked on tool-call reliability at the same rigor, though its MCP Atlas score of 74.2% suggests capable tool use. For production agents making hundreds of tool calls daily, Claude's proven reliability comes at a premium ($3/$15 per million tokens) but reduces failure-related costs. M3's cost advantage is strongest for simple, high-volume tasks with minimal tool calling.
How does GLM-5.1 compare to MiniMax M3 for coding agents?
GLM-5.1 topped SWE-Bench Pro, beating GPT-5.4 and Claude Opus 4.6. It scores 94.6% of Claude Opus 4.6's coding performance. Z.ai claims it can maintain goal alignment for up to 8 hours per autonomous session. MiniMax M3 scores 59% on SWE-Bench Pro, which is strong but below GLM-5.1's mark. M3 wins on context window (1M vs 203K) and cost ($0.60 vs $0.98 input). For pure coding agent workloads, GLM-5.1 has the edge. For multi-modal or long-document agents, M3 has the architecture advantage.
Is MiniMax M3 cost-effective enough to replace Claude for production agents?
For high-volume, simple tasks (classification, extraction, routing), yes. M3 at $0.60/M input is 5x cheaper than Claude Sonnet. For multi-step agent workflows with tool calling, the answer depends on your error tolerance. Kili Technology found a 37% average gap between lab benchmarks and real-world agent performance, and M3 is too new for longitudinal reliability data. Test on your actual workload before switching production traffic. Claude Sonnet with prompt caching narrows the gap to roughly 67% more expensive while offering proven reliability.
Can I use multiple models for different agents on the same platform?
Yes. On BetterClaw, each agent can be assigned a different model provider. Run MiniMax M3 for your high-volume classification agent, Claude Sonnet for your customer-facing support agent, and GLM-5.1 for your coding agent. BetterClaw supports 28+ model providers through BYOK with zero inference markup. Model switching is a dropdown change with no code changes or redeployment required.



