Every major AI model's input cost, output cost, context window, and best use case in one bookmarkable page. Last verified: June 1, 2026.
Prices verified against official provider pricing pages. If something here disagrees with a provider's rate card, trust the rate card and let us know.
I spent an afternoon last week hopping between OpenAI's pricing page, Anthropic's docs, Google's confusingly nested Vertex AI console, DeepSeek's changelog, and xAI's pricing dashboard. Eight browser tabs. Five different pricing formats. Three different definitions of "million tokens."
All I wanted was one page where I could compare every model side by side.
This is that page.
Every LLM pricing number below comes from the provider's official pricing page or API documentation, cross-referenced against at least one independent source. We'll keep this updated monthly as pricing changes, which in 2026 means... constantly.
The master pricing table
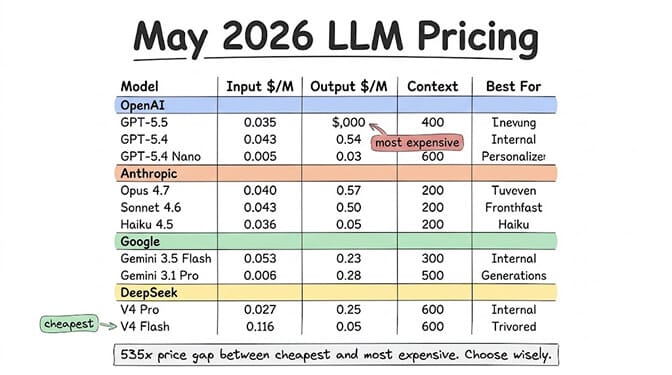
Here's every major model you'd realistically use for an AI agent, app, or API integration. All prices are USD per 1 million tokens.
OpenAI
GPT-5.5 (current flagship): $5.00 input / $30.00 output. Context: 1,050,000 tokens. Built-in reasoning. This is the most capable OpenAI model and the most expensive per output token in the lineup. Cached input drops to $0.50/M (90% savings). Batch processing halves all rates. Best for: the hardest coding and agent tasks where quality trumps cost.
GPT-5.4 (previous flagship, still excellent): $2.50 input / $15.00 output. Context: 1,050,000 tokens. Half the price of GPT-5.5 on both input and output. For most production workloads, this is the right OpenAI model. Best for: production apps where you need frontier quality without frontier pricing.
GPT-5.4 Nano (ultra budget): $0.20 input / $1.25 output. The cheapest current-gen OpenAI model. Handles classification, extraction, simple routing. Best for: high-volume simple tasks where you need an OpenAI model specifically.
GPT-4o (multimodal workhorse): $2.50 input / $10.00 output. Context: 128,000 tokens. Still widely used for vision and multimodal tasks. Best for: image understanding, legacy integrations.
GPT-4.1 Nano (absolute floor): $0.10 input / $0.40 output. The cheapest model in OpenAI's entire lineup. Best for: routing, tagging, the simplest possible tasks.
Anthropic
Claude Opus 4.7 (current flagship): $5.00 input / $25.00 output. Context: 1,000,000 tokens. Leads coding benchmarks (87.6% SWE-Bench Verified). Cached input: $0.50/M. Batch: 50% off. Important note: Opus 4.7 uses a new tokenizer that can generate up to 35% more tokens for the same text compared to older models. So your effective per-request cost may be higher than the rate card suggests. Benchmark before migrating. Best for: coding agents, complex reasoning, agentic workflows.
Claude Sonnet 4.6 (best value in the lineup): $3.00 input / $15.00 output. Context: 1,000,000 tokens. Near-Opus quality at 40% lower cost. This is the model most production teams should default to. Best for: the majority of production workloads. Coding, analysis, writing, customer-facing apps.
Claude Haiku 4.5 (speed tier): $1.00 input / $5.00 output. Context: 200,000 tokens. Best for: classification, routing, extraction, summarization. Use this for the 80% of tasks that don't need frontier reasoning.
Gemini 3.5 Flash (fastest frontier model): $1.50 input / $10.00 output. Context: 1,000,000 tokens. 289 tokens/second output speed. Beats the previous Pro model on coding benchmarks while running 4x faster. Cached input: $0.15/M (90% discount, the most aggressive cache pricing in the market). Best for: high-volume agentic workloads where speed matters. Free tier: 1,000 requests/day at no cost.
Gemini 3.1 Pro: $2.00 input / $12.00 output. Context: 1,000,000 tokens. Google's reasoning flagship. Best for: complex analytical tasks on Google Cloud.
Gemini 3.1 Flash-Lite: $0.10 input / $0.40 output. One of the cheapest capable models available from any major provider. Best for: ultra-high-volume simple tasks.
Gemini 2.0 Flash: $0.10 input / $0.40 output. Budget champion from the previous generation. Still supported. Best for: cost-sensitive prototyping, testing.
DeepSeek
DeepSeek V4 Pro: $0.435 input / $0.87 output. Context: 1,000,000 tokens. 384K max output. The price leader among frontier-class models. 80.6% SWE-Bench Verified, competitive with Claude Opus at 11x lower cost. Cache hit pricing: $0.003625/M (absurdly cheap). Best for: teams that want frontier coding quality without frontier pricing.
DeepSeek V4 Flash: $0.14 input / $0.28 output. Context: 1,000,000 tokens. The cheapest frontier-capable model in existence. Cache hit input: $0.0028/M. If you're building a high-volume agent and every token counts, this is where to start. Best for: high-volume agents, extraction, routing, and any task where the cost-per-token math matters more than peak quality.
xAI (Grok)
Grok 4.3: $0.20 input / $0.60 output. Context: 2,000,000 tokens (largest in the market). The context-to-cost ratio here is unmatched. $0.20/M input for 2M tokens of context. Best for: tasks that need enormous context windows (full codebases, long document processing, entire conversation histories). Also available free via SuperGrok subscription ($30/month) with voice, image, video, and X search included.
Grok 3: $3.00 input / $15.00 output. Previous generation flagship. Best for: teams locked into xAI who need a higher-capability tier.
Grok 3 Mini: $0.30 input / $0.50 output. Budget option with $25 in free credits for new users. Best for: trying xAI's ecosystem without commitment.
Mistral
Mistral Small 4: $0.10 input / $0.30 output. 566 tokens/second output, the fastest model in the market. GDPR-compliant, EU-based. Best for: European teams needing data sovereignty, speed-critical applications.
Mistral Large 3: Higher pricing tier for complex reasoning. Best for: teams committed to the Mistral ecosystem.
Codestral: Coding-focused model. Best for: developer tooling integrations.
Amazon Nova
Nova Micro: $0.035 input / $0.14 output. The cheapest model from any major cloud provider. Best for: the absolute floor on cost if you're inside AWS already.
Nova Lite: $0.06 input / $0.24 output. Slightly more capable than Micro. Best for: budget Bedrock workloads.
Nova Pro: Higher tier. Best for: Bedrock-native applications needing more reasoning.
Open-Weight Models (Llama, Qwen, etc.)
Meta Llama 4, Qwen 3 Coder, and other open-weight models are free to download. Running costs depend entirely on your GPU infrastructure: cloud GPU hosting ranges from $0.50 to $5.00/hour depending on model size. Third-party API access via Groq, Together AI, and Fireworks AI varies wildly ($0.10 to $3.00 for the same model weights). Best for: teams with existing GPU infrastructure who want zero per-token costs and maximum control.
The number that actually matters: 535x

The gap between the most expensive output token (GPT-5.5 at $30/M) and the cheapest (Amazon Nova Micro at $0.14/M, or DeepSeek V4 Flash at $0.28/M) is over 200x on output alone.
That's not a rounding error. That's the difference between a $3,000/month AI bill and a $15/month one for the same volume of requests.
The model you choose is the single biggest cost lever on your AI bill. Not the infrastructure. Not the provider. The model. (If you're not sure which model fits your task, our four-question LLM selection framework narrows it down fast.)
What your monthly bill actually looks like
Let's do the math for a real scenario. You're running an AI agent that handles 500 interactions per day, with an average of 2,000 input tokens and 1,000 output tokens per interaction.
That's 30,000,000 input tokens and 15,000,000 output tokens per month.
- GPT-5.5: $150 input + $450 output = $600/month
- Claude Sonnet 4.6: $90 input + $225 output = $315/month
- Gemini 3.5 Flash: $45 input + $150 output = $195/month (or $0 if you stay under the free tier)
- DeepSeek V4 Pro: $13.05 input + $13.05 output = $26/month
- DeepSeek V4 Flash: $4.20 input + $4.20 output = $8.40/month
- Grok 4.3: $6 input + $9 output = $15/month
Same workload. Same 500 interactions per day. Monthly bill ranges from $8.40 to $600.
And here's what most people miss: for an agent that answers customer questions, sends follow-up emails, and triages support tickets, the difference in quality between a $600/month model and a $26/month model is much smaller than the 23x price difference suggests. For a deeper breakdown of agent costs across five real use cases, see our AI agent cost guide.
This is exactly why BetterClaw supports BYOK across 28+ providers with zero inference markup. You plug in whichever API key makes sense for your use case, and you pay the provider directly. No middleman markup. No vendor lock-in. Start with the free plan, use DeepSeek V4 Flash for $8/month, and upgrade to Claude Sonnet if you need the quality bump. Switch models with one click, no rebuild required.
The hidden costs nobody puts in their pricing table
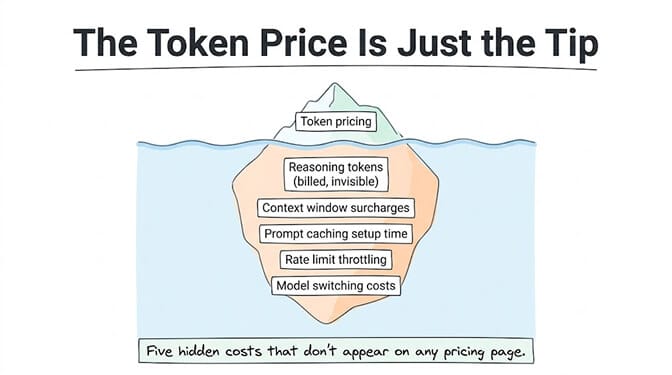
The rate card is just the beginning. Here are five costs that regularly surprise teams:
Reasoning tokens you never see. Models like GPT-5.5, Claude Opus 4.7, and the o-series generate hidden "thinking" tokens that are billed as output but never returned in the response. A 500-token visible response can consume 2,000+ total tokens. Your bill reflects the total, not just what you see.
Context window surcharges. GPT-5.5 charges higher rates when your prompt exceeds 272,000 tokens. The surcharge applies to the entire session, not just the overage. Long-context workloads need careful modeling.
Tokenizer differences. Claude Opus 4.7's new tokenizer generates up to 35% more tokens for the same input text compared to Opus 4.6. Per-token price is unchanged, but your per-request cost jumps because the same text becomes more tokens.
Agent token multiplication. AI agents are fundamentally more expensive than single-turn chat. An agent that uses tools (file read, web search, API calls) generates a round-trip per tool call. A 5-step agent workflow with a 30K-token system prompt re-sends that prompt multiple times. Agent workflows commonly consume 4 to 8x the tokens you'd estimate from the visible conversation. If you're building an agent, take your estimated token usage and multiply by 5. That's your real bill.
Prompt caching isn't free setup. Both Anthropic and OpenAI offer 90% discounts on cached input tokens. But you need to architect your system to reuse prompts consistently. The discount only applies to cache hits, which requires stable system prompts and consistent tool definitions. It's worth it, but it's not automatic.
The 3 cost tiers that actually matter
Forget memorizing 40 models. In practice, you're choosing between three tiers:
Tier 1: Frontier ($5+/M input). GPT-5.5, Claude Opus 4.7. Use these for the 10-20% of tasks that genuinely require maximum capability: complex multi-step reasoning, hard coding problems, nuanced creative work. Not for email triage.
Tier 2: Production ($1-3/M input). Claude Sonnet 4.6, GPT-5.4, Gemini 3.5 Flash, Gemini 3.1 Pro. This is where most production workloads belong. 90% of frontier quality at 30-50% of the cost. The sweet spot.
Tier 3: Budget (under $0.50/M input). DeepSeek V4 Flash/Pro, Grok 4.3, Mistral Small 4, Amazon Nova, GPT-5.4 Nano, Gemini Flash-Lite. For high-volume simple tasks, routing, classification, extraction, and any use case where volume matters more than peak quality.
The best teams use all three tiers. Route each request to the cheapest model that can handle it. Simple question? Tier 3. Analysis task? Tier 2. Complex coding problem? Tier 1. This strategy, called model routing, alone cuts most AI bills by 70-90%.
BetterClaw supports this out of the box. Plug in keys from different providers, assign different models to different agent skills, and the platform routes accordingly. Smart context management prevents the token bloat that makes self-hosted agents 4-8x more expensive than they need to be. Free plan available. $49/month on Pro.
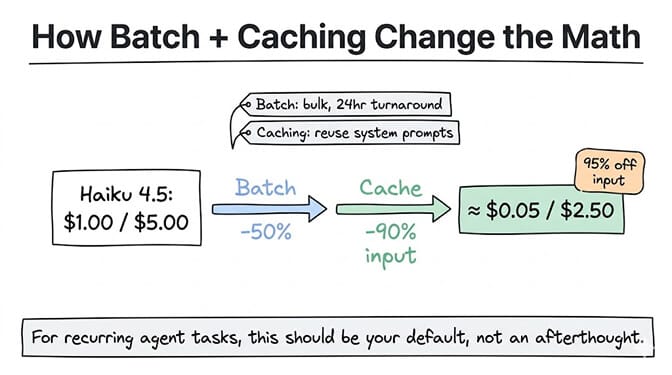
How batch and caching change the math
Both OpenAI and Anthropic offer two major discounts:
Batch processing (50% off): Send requests in bulk with 24-hour turnaround instead of real-time. Perfect for content generation, data labeling, nightly reports, and any non-interactive workload.
Prompt caching (90% off cached input): Store frequently reused content (system prompts, tool definitions, long documents) so subsequent calls read from cache. Anthropic and OpenAI both offer this. Google's cached input discount is the most aggressive at 90% on Gemini models.
These discounts stack. A cached batch request on Claude Haiku 4.5 drops from $1.00/$5.00 to roughly $0.05/$2.50 per MTok. That's a 95% reduction on input cost.
For AI agents running recurring tasks, batch and caching should be your default assumption, not an optimization for later.
The verdict: what to pick for what
If you need the best coding agent: Claude Opus 4.7 ($5/$25) or DeepSeek V4 Pro ($0.435/$0.87). Opus leads benchmarks. DeepSeek is 11x cheaper with competitive quality. (We compare them head to head in our GPT-5.5 vs Claude vs DeepSeek breakdown.)
If you need the best general agent: Claude Sonnet 4.6 ($3/$15) or GPT-5.4 ($2.50/$15). Both are excellent production-grade models at similar prices.
If you need the cheapest agent that actually works: DeepSeek V4 Flash ($0.14/$0.28) or Grok 4.3 ($0.20/$0.60). DeepSeek wins on price. Grok wins on context window (2M tokens).
If you need zero API cost: Gemini 2.0 Flash has a free tier of 1,000 requests/day. Grok is free through SuperGrok subscription. Open-weight models via Ollama cost $0/token (you pay hosting).
If you need data sovereignty in the EU: Mistral Small 4 ($0.10/$0.30). GDPR-compliant, EU-based, fastest output speed.
If you need the biggest context window: Grok 4.3 at 2,000,000 tokens. Nothing else comes close at $0.20/M input.
The real takeaway
LLM pricing in 2026 is a commodity race with more spread than people realize. The same task that costs $600/month on GPT-5.5 costs $8/month on DeepSeek V4 Flash. Both are real production models. Both support tool calling, JSON output, and agent workflows.
The teams that are winning on AI costs aren't using one model. They're using three or four, matched to the right task at the right price point.
If any of this resonated, give BetterClaw a look. We support BYOK across all 28+ of these providers with zero inference markup. You pay providers directly. Switch models with one click. Smart context management prevents token bloat. Per-agent cost caps stop runaway spending. Free plan with 1 agent and 500 credits a month. $49/month on Pro. Your first deploy takes about 60 seconds.
The model matters. The markup on top of it shouldn't.
Frequently Asked Questions
How much does LLM pricing cost per million tokens in 2026?
LLM pricing in 2026 ranges from $0.035 per million input tokens (Amazon Nova Micro) to $5.00 per million input tokens (GPT-5.5 and Claude Opus 4.7). Output tokens are always more expensive, typically 3-5x the input rate. The cheapest frontier-capable model is DeepSeek V4 Flash at $0.14/$0.28 per million tokens. Most production workloads use the $1-3/M tier (Claude Sonnet 4.6, GPT-5.4, Gemini 3.5 Flash).
How does OpenAI API pricing compare to Anthropic Claude pricing?
GPT-5.5 ($5/$30 per MTok) costs more than Claude Opus 4.7 ($5/$25 per MTok) on output tokens. GPT-5.4 ($2.50/$15) is slightly cheaper than Claude Sonnet 4.6 ($3/$15) on input but identical on output. At the budget end, GPT-5.4 Nano ($0.20/$1.25) is cheaper than Claude Haiku 4.5 ($1/$5). Both offer 50% batch discounts and 90% prompt caching discounts. Anthropic includes 1M context at flat pricing on Opus and Sonnet; OpenAI charges surcharges above 272K tokens on GPT-5.5.
How do I reduce my LLM API costs without switching models?
Three levers work immediately: prompt caching (90% off on repeated system prompts and documents), batch processing (50% off for non-real-time workloads), and context management (trim conversation history to avoid re-sending thousands of tokens per request). Platforms like BetterClaw handle context management automatically with smart trimming. The biggest lever, though, is model routing: use a cheap model for simple tasks and an expensive model only when quality demands it.
What is the cheapest LLM for running an AI agent?
DeepSeek V4 Flash at $0.14 input / $0.28 output per million tokens is the cheapest model capable of running production agent workflows (tool calling, JSON output, multi-step reasoning). Google Gemini 2.0 Flash offers a free tier of 1,000 requests/day. Grok 4.3 is free through a SuperGrok subscription ($30/month flat). For self-hosted options, open-weight models like Llama 4 and Qwen 3 cost $0/token but require GPU infrastructure.
Why do AI agents cost more than regular chatbot usage?
AI agents generate significantly more tokens than single-turn chat. Every tool call (file read, API call, web search) creates a round-trip that re-sends the full conversation context. A 5-step agent workflow with a 30K-token system prompt can consume 4-8x the tokens of a simple Q&A exchange. This is why context management matters: platforms like BetterClaw use smart context trimming to prevent token bloat, and per-agent cost caps to stop runaway spending.