

Both pricing pages are confusing on purpose. Here's the side-by-side comparison with hidden costs, real-world scenarios, and the strategy most developers miss.
I spent two hours last Tuesday going back and forth between OpenAI's pricing page and Anthropic's pricing page trying to answer a simple question: which one is cheaper for the agent I'm building?
Two hours. Because neither page makes it easy.
OpenAI has GPT-5.5, GPT-5.4, GPT-5.4 Nano, GPT-4.1, GPT-4.1 Nano, GPT-4.1 Mini, o3, o4-mini, and a dozen legacy models still listed. Anthropic has three model families with extended thinking pricing that differs from standard pricing. Both have prompt caching, batch discounts, and rate limit tiers that change the math entirely.
The answer to "which is cheaper, OpenAI vs Anthropic pricing?" is: it depends on exactly what you're building, how much you cache, and whether you optimize at all. But nobody has time for "it depends." So here's the actual breakdown. (For rates across every major provider, not just these two, see our complete LLM pricing guide.)
Last updated: May 29, 2026.
The side-by-side that matters: standard API pricing
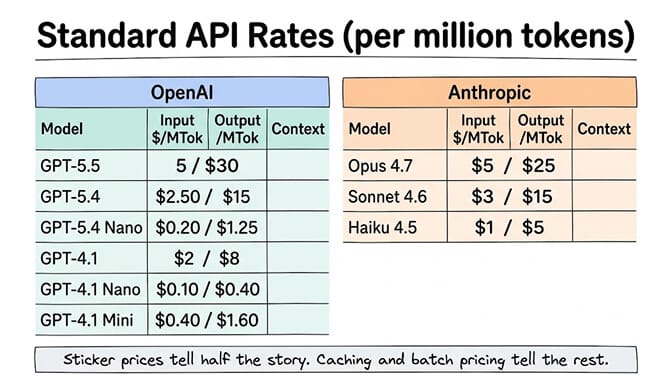
All prices per million tokens (MTok). Standard direct API rates.
OpenAI flagship: GPT-5.5 at $5.00 input / $30.00 output. 1,050,000-token context. Cached input: $0.50 (90% off).
Anthropic flagship: Claude Opus 4.7 at $5.00 input / $25.00 output. 1,000,000-token context. Cached input: $0.50 (90% off).
Verdict at the top: Same input price. Anthropic is $5/MTok cheaper on output. That matters because output tokens usually cost 3 to 5x more than input in practice. For a workload generating lots of output (reports, code, long responses), Opus 4.7 is meaningfully cheaper than GPT-5.5.
OpenAI mid-tier: GPT-5.4 at $2.50/$15.00. GPT-4.1 at $2.00/$8.00.
Anthropic mid-tier: Claude Sonnet 4.6 at $3.00/$15.00.
Verdict at mid-tier: GPT-5.4 is $0.50 cheaper on input than Sonnet with identical output pricing. GPT-4.1 is significantly cheaper at $2/$8 but is a previous-generation model. For most production workloads, Sonnet 4.6 and GPT-5.4 are close enough that the quality difference matters more than the price difference.
OpenAI budget: GPT-5.4 Nano at $0.20/$1.25. GPT-4.1 Nano at $0.10/$0.40. GPT-4.1 Mini at $0.40/$1.60.
Anthropic budget: Claude Haiku 4.5 at $1.00/$5.00.
Verdict at budget tier: OpenAI wins decisively. GPT-4.1 Nano at $0.10/$0.40 is 10x cheaper than Haiku on input and 12.5x cheaper on output. Anthropic has no ultra-budget model. If you need the cheapest possible option from these two providers, OpenAI's Nano models are in a different price bracket entirely. (To see how both stack up against budget challengers like DeepSeek, see our cheapest AI providers guide.)
At sticker price, OpenAI is cheaper across most comparable tiers. Anthropic closes the gap (and sometimes wins) through flat-rate long context and better coding benchmarks.
The hidden costs that change the math
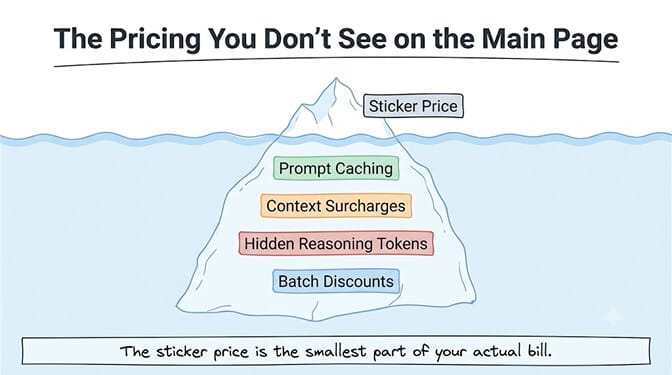
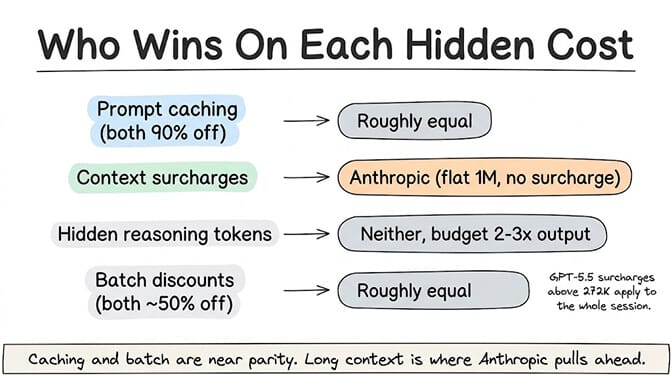
Prompt caching: both offer 90% off, but the mechanics differ
OpenAI: Automatic caching. If you send the same prompt prefix repeatedly, cached tokens are charged at 10% of the standard input rate. GPT-5.5 cached input: $0.50/MTok (vs. $5.00 standard). No opt-in required.
Anthropic: Explicit caching. You mark specific content blocks as cacheable with a cache_control parameter. Cached tokens: 10% of standard input. Opus 4.7 cached: $0.50/MTok. Sonnet 4.6 cached: $0.30/MTok. There's a one-time write cost of 25% above standard for the initial cache creation.
Who wins: For agents with repetitive system prompts (most agents), both save ~90% on input. Anthropic's explicit approach gives you more control. OpenAI's automatic approach requires zero code changes. In practice, the savings are nearly identical for cache-heavy workloads.
Context window surcharges: Anthropic's biggest advantage
OpenAI (GPT-5.5): Flat pricing up to 272,000 tokens. Above 272K, a surcharge applies to the entire session (not just the overage). This means a 300K-token conversation costs significantly more per token than a 270K-token conversation.
Anthropic (Opus 4.7 and Sonnet 4.6): Flat pricing across the full 1,000,000-token context window. No surcharges at any length.
Who wins: Anthropic, clearly. If your agent processes long documents, maintains extended conversation histories, or loads large codebases into context, Anthropic's flat-rate pricing is a significant advantage. A 500K-token context on Anthropic costs exactly what the rate card says. The same context on GPT-5.5 costs more.
Hidden reasoning tokens: the cost you never see
OpenAI (GPT-5.5): Generates internal reasoning tokens that are billed as output ($30/MTok) but don't appear in the response. A 500-token reply can cost you 2,000+ tokens because of hidden reasoning. You pay for thinking you never see.
Anthropic (Opus 4.7): Extended thinking tokens are billed as output ($25/MTok) but hidden by default. You can opt in to see them. The new Opus 4.7 tokenizer also generates up to 35% more tokens for the same text compared to previous versions.
Who wins: Neither. Both charge for hidden reasoning. The key difference is Anthropic lets you opt in to visibility. On both platforms, your actual bill will be higher than the token count in your response suggests. Budget 2 to 3x the visible output tokens.
Batch discounts: OpenAI's exclusive advantage
OpenAI: 50% off on all models through the Batch API. 24-hour SLA for results. GPT-5.5 batch: $2.50/$15.00. GPT-5.4 batch: $1.25/$7.50.
Anthropic: Batches API available with similar pricing reductions. Both now offer batch processing, making this closer to parity than it was six months ago.
Who wins: Roughly equal now. Both offer significant batch discounts for async workloads. If your agent can tolerate 24-hour turnaround on non-urgent tasks, batch processing cuts costs by ~50% on either provider.
Three real-world scenarios: actual monthly cost compared
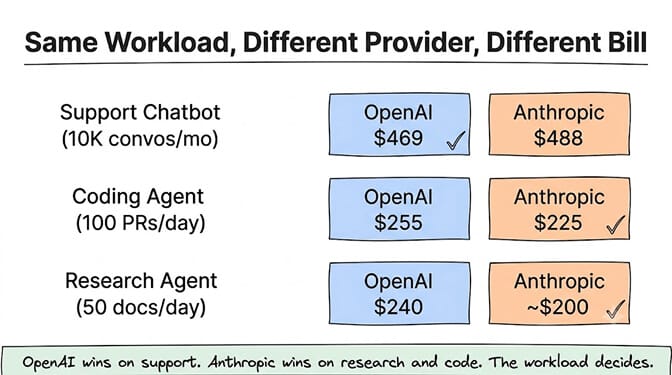
Scenario 1: Customer support chatbot (10,000 conversations/month)
Average conversation: 5 messages. Input per conversation: ~7,500 tokens (question + context + history). Output per conversation: ~2,500 tokens (reply).
Monthly totals: 75M input tokens. 25M output tokens.
- On GPT-5.4 ($2.50/$15): $187.50 input + $375 output = $562/month. With 50% cache hit rate on system prompt: $469/month.
- On Sonnet 4.6 ($3/$15): $225 input + $375 output = $600/month. With 50% cache hit rate: $488/month.
Winner: OpenAI by ~$20/month. GPT-5.4's cheaper input rate wins on high-volume, input-heavy workloads. The gap narrows with caching.
Scenario 2: Coding agent reviewing 100 PRs per day
Average PR: 5,000 tokens of code input. 2,000 tokens of review output. Monthly: 15M input, 6M output.
- On GPT-5.5 ($5/$30): $75 + $180 = $255/month.
- On Opus 4.7 ($5/$25): $75 + $150 = $225/month.
Winner: Anthropic by $30/month. Same input cost, but Opus's cheaper output rate saves on output-heavy tasks. Plus Opus leads SWE-Bench at 87.6%, so you get better code reviews for less money. Double win.
Scenario 3: Research agent processing 50 long documents per day
Average document: 25,000 tokens. Summary output: 3,000 tokens. Monthly: 37.5M input, 4.5M output. Long documents mean context windows above 272K regularly.
- On GPT-5.5 (with surcharges above 272K): Effective input rate increases. Estimated: $240/month including surcharges.
- On Opus 4.7 (flat pricing, no surcharges): $187.50 + $112.50 = $300/month. But wait. With Anthropic's prompt caching on repeated document structures: closer to $200/month.
Winner: Anthropic. Flat-rate long context is the deciding factor for research workloads. No surcharge surprises.
This is the spot where most developers realize something: the answer isn't OpenAI OR Anthropic. It's OpenAI AND Anthropic. Use GPT-5.4 for high-volume support tasks. Use Opus for code and research. Use GPT-4.1 Nano for simple classification.
BetterClaw supports BYOK across both providers (plus 26 others) with zero inference markup. Paste your OpenAI key for one task type. Your Anthropic key for another. Switch models without rebuilding anything. Free plan available, $49/month on Pro.
The tier strategy that saves the most money
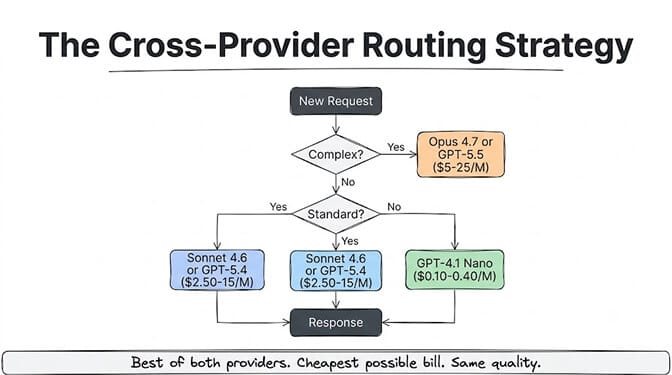
Don't pick one provider. Pick models from both based on what each does best.
Simple tasks (50% of requests): GPT-4.1 Nano at $0.10/$0.40. Anthropic has nothing this cheap. OpenAI owns the budget tier.
Standard tasks (30% of requests): GPT-5.4 at $2.50/$15 or Sonnet 4.6 at $3/$15. Close enough. Pick based on whether you value OpenAI's slightly cheaper input or Anthropic's better coding quality.
Complex tasks (20% of requests): Claude Opus 4.7 at $5/$25 for code and research. GPT-5.5 at $5/$30 for multi-step tool orchestration. Opus is cheaper on output and better at code. GPT-5.5 has the wider tool ecosystem.
This cross-provider strategy typically costs 40 to 60% less than using either provider exclusively, because you're always picking the cheapest model that fits each task's needs. For a deeper look at how model routing works and why single-model setups are expensive, our routing guide covers the full strategy.
The verdict: when to pick which provider
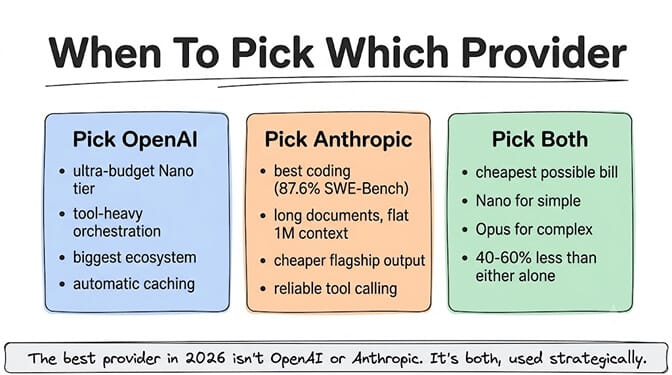
Pick OpenAI when: You need ultra-budget models (Nano tier, $0.10/M). You're building tool-heavy agents with complex orchestration. You want the largest developer ecosystem and community support. You need batch processing for async workloads. You value automatic prompt caching without code changes.
Pick Anthropic when: You need the best coding agent (Opus 4.7, 87.6% SWE-Bench). You process long documents regularly (flat-rate 1M context). You want cheaper output tokens at the flagship tier ($25 vs $30). You need the most reliable tool calling for agent workflows (community consensus).
Pick both when: You want the cheapest possible bill. The cross-provider routing strategy, mixing OpenAI Nano for simple tasks with Anthropic Opus for complex ones, delivers better quality and lower cost than either provider alone. If you're weighing a third provider, our GPT-5.5 vs Claude vs DeepSeek breakdown adds the budget frontier option to the mix.
If you're building agents and want to use both providers without managing multiple API integrations, give BetterClaw a look. BYOK across both OpenAI and Anthropic (plus 26 other providers) with zero markup. Assign different models to different tasks through the visual builder. Smart context management keeps token costs down. Per-agent cost caps prevent surprises. Free plan with 1 agent and 500 credits a month. $49/month for Pro.
The best provider in 2026 isn't OpenAI or Anthropic. It's both, used strategically.
Frequently Asked Questions
Is OpenAI or Anthropic cheaper for API usage?
It depends on the tier and workload. At budget level, OpenAI is dramatically cheaper: GPT-4.1 Nano costs $0.10/$0.40 per MTok vs. Claude Haiku at $1/$5. At flagship level, Anthropic is slightly cheaper on output: Opus 4.7 charges $25/MTok output vs. GPT-5.5's $30. For most production workloads using mid-tier models, the difference is under 10%. The biggest savings come from using both providers strategically.
How does Claude Opus 4.7 pricing compare to GPT-5.5?
Both charge $5/MTok for input. Opus 4.7 charges $25/MTok for output vs. GPT-5.5's $30/MTok, making Opus 17% cheaper on output. Opus also offers flat-rate pricing across its full 1M-token context window, while GPT-5.5 applies surcharges above 272K tokens. Both offer ~90% discounts on cached input. For output-heavy workloads (code generation, long-form writing), Opus is the cheaper option.
What hidden costs should I watch for with OpenAI and Anthropic APIs?
Three big ones. First, hidden reasoning tokens: both GPT-5.5 and Opus 4.7 generate internal reasoning billed as output but invisible in responses. Budget 2 to 3x the visible output. Second, context surcharges: GPT-5.5 charges more above 272K tokens (applied to the whole session). Anthropic doesn't. Third, Opus 4.7's new tokenizer generates up to 35% more tokens for the same text. Your per-request cost can be higher even though the per-token rate didn't change.
Can I use both OpenAI and Anthropic in the same AI agent?
Yes. Platforms like BetterClaw support BYOK across both providers (plus 26 others). You paste API keys from each, assign models to different task types, and the platform routes requests accordingly. This cross-provider approach typically saves 40 to 60% compared to using either provider exclusively, because you always use the cheapest model that fits each task.
Which provider is better for building AI agents in 2026?
Anthropic's Claude models are the community favorite for agent tasks because of superior tool-calling reliability and prompt injection resistance. Opus 4.7 leads coding benchmarks (87.6% SWE-Bench). OpenAI has the broader ecosystem, better budget options, and wider third-party support. The best agent setups use both: Anthropic for complex reasoning and code, OpenAI's Nano models for cheap simple tasks.



