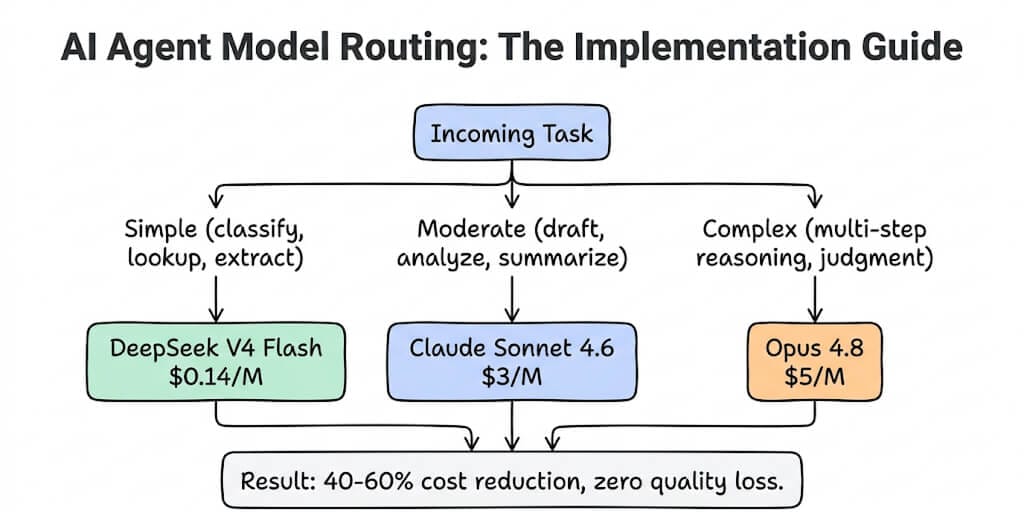
You're sending every email classification to Claude Opus at $5 per million tokens. The same email classification works identically on DeepSeek V4 Flash at $0.14. Here's the step-by-step setup that routes each task to the right model automatically.
Stop overpaying per task.
One agent, every model, one dropdown. Route each task to the right model with zero markup. Free forever, not a trial. Start free → No credit card · No Docker · No config files
Our support agent was running Claude Sonnet 4.6 on everything. Classification. Response drafting. Sentiment analysis. Escalation decisions. All Sonnet. All $3 per million input tokens.
Then we looked at the task distribution. 65% of what the agent did was classification and extraction. Is this a billing question or a technical question? Extract the order number. Pull the customer tier from CRM. Structured, simple, predictable tasks.
We swapped those tasks to DeepSeek V4 Flash at $0.14/M. Same accuracy on classification. Same extraction quality. The monthly bill dropped from $340 to $140. The 35% of tasks that genuinely needed Sonnet's instruction following and reasoning stayed on Sonnet. Zero quality loss on any individual task.
That's AI agent model routing. Not a concept. Not a theory. A specific implementation that saves 40-60% on your API bill without degrading output quality. The concept post on our blog explains why routing matters. This post shows you exactly how to build it.
The Three-Tier Model (Start Here)
Every agent task falls into one of three complexity tiers. The routing decision is: which tier does this task belong to?
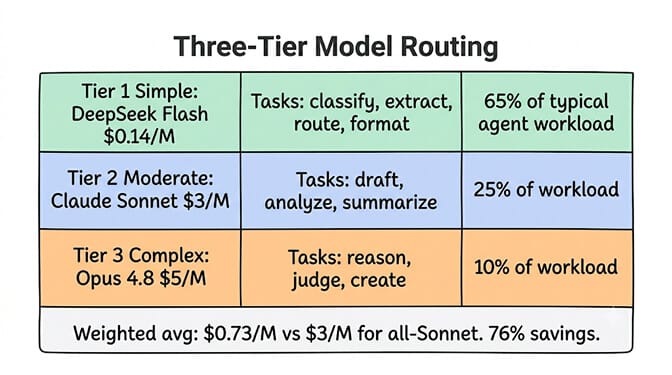
Tier 1: Simple tasks (route to cheapest model)
Classification, extraction, lookup, routing, formatting. The task has a well-defined input, a predictable output format, and doesn't require judgment or creativity.
Examples: "Is this email a billing question or a technical question?" "Extract the sender name, date, and amount from this invoice." "Which team should handle this ticket?" "Format this data as a JSON object."
Recommended model: DeepSeek V4 Flash ($0.14/M input, $0.28/M output). Also works: GLM 5.1 ($0.98/M), Gemma 4 12B (free local).
Tier 2: Moderate tasks (route to mid-tier model)
Drafting, analysis, summarization, moderate reasoning. The task requires understanding context, following instructions with some nuance, and producing output that needs to be correct but not creatively brilliant.
Examples: "Draft a response to this customer complaint." "Summarize this 10-page document into 5 key points." "Analyze this sales data and identify the top 3 trends." "Write a Slack update about today's deployment."
Recommended model: Claude Sonnet 4.6 ($3/M input, $15/M output). Also works: GPT-5.5 ($5/M), MiniMax M3 ($0.60/M for budget mid-tier). Not sure where a task belongs? Our guide on how to choose an LLM for your task walks through the call.
Tier 3: Complex tasks (route to frontier model)
Multi-step reasoning, judgment calls, safety-critical decisions, creative work, ambiguous instructions. The task requires the model to plan, evaluate alternatives, and produce output where subtle quality differences matter.
Examples: "Should we escalate this customer to the VP of Sales based on the conversation history?" "Review this contract and flag any unusual clauses." "This code review has conflicting feedback. Synthesize a recommendation." "Write a personalized sales email based on this prospect's LinkedIn activity."
Recommended model: Claude Opus 4.8 ($5/M input, $25/M output). Also works: GPT-5.5 ($5/M), Claude Sonnet with extended thinking.
The Classifier Prompt (Paste This)
The routing decision itself is a Tier 1 task. Use your cheapest model to classify the incoming task, then route to the appropriate model.
Here's the classifier prompt:
You are a task complexity classifier. Given a task description,
classify it as one of three tiers:
TIER_1_SIMPLE: The task has a clear, well-defined input and
a predictable output format. Examples: classification, data
extraction, lookup, formatting, routing, yes/no questions,
simple math.
TIER_2_MODERATE: The task requires understanding context,
following nuanced instructions, or producing drafted content.
Examples: email drafting, document summarization, data analysis,
report writing, moderate reasoning.
TIER_3_COMPLEX: The task requires multi-step reasoning, judgment
calls, creative thinking, handling ambiguity, or safety-critical
decisions. Examples: contract review, strategic recommendations,
conflict resolution, code architecture decisions, personalized
creative content.
Respond with ONLY the tier label. No explanation.
Task: {task_description}
This classifier runs on DeepSeek V4 Flash at $0.14/M. It adds approximately 200 tokens (classifier prompt + response) per task. At 1,000 tasks/day, the classifier itself costs about $0.03/day. Negligible.
The Routing Logic (Implementation)
Here's the routing implementation in Python. Adapt the API calls to your framework:
import anthropic
import openai
# Model configuration
MODELS = {
"tier_1": {
"provider": "deepseek",
"model": "deepseek-v4-flash",
"cost_per_m_input": 0.14,
"cost_per_m_output": 0.28
},
"tier_2": {
"provider": "anthropic",
"model": "claude-sonnet-4-6-20260514",
"cost_per_m_input": 3.0,
"cost_per_m_output": 15.0
},
"tier_3": {
"provider": "anthropic",
"model": "claude-opus-4-8-20260601",
"cost_per_m_input": 5.0,
"cost_per_m_output": 25.0
}
}
def classify_task(task_description: str) -> str:
"""Classify task complexity using cheapest model."""
response = openai.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "system", "content": CLASSIFIER_PROMPT},
{"role": "user", "content": task_description}
],
max_tokens=10,
temperature=0
)
tier = response.choices[0].message.content.strip()
return tier if tier in MODELS else "tier_2" # default to mid
def route_and_execute(task_description: str, context: str) -> str:
"""Classify, route, and execute the task."""
tier = classify_task(task_description)
model_config = MODELS[tier]
if model_config["provider"] == "anthropic":
client = anthropic.Anthropic()
response = client.messages.create(
model=model_config["model"],
max_tokens=4096,
messages=[{"role": "user", "content": context}]
)
return response.content[0].text
else:
response = openai.chat.completions.create(
model=model_config["model"],
messages=[{"role": "user", "content": context}]
)
return response.choices[0].message.content
The fallback matters. If the classifier returns something unexpected, default to Tier 2. You'd rather overpay slightly on a simple task than underspend on a complex one.
The Cost Math (Why This Works)
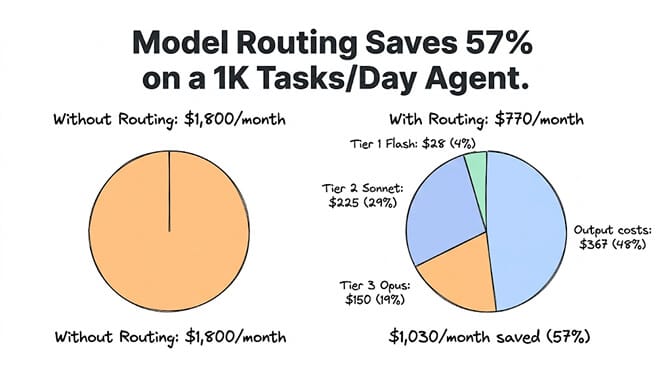
Here's the math for a typical agent processing 1,000 tasks per day.
Without routing (all Sonnet 4.6):
1,000 tasks x 10,000 tokens avg x $3/M input = $30/day input. Plus output: 1,000 x 2,000 tokens x $15/M = $30/day output. Total: $60/day, $1,800/month.
With three-tier routing:
- Tier 1 (65% = 650 tasks): 650 x 10K x $0.14/M = $0.91/day
- Tier 2 (25% = 250 tasks): 250 x 10K x $3/M = $7.50/day
- Tier 3 (10% = 100 tasks): 100 x 10K x $5/M = $5.00/day
- Classifier overhead: 1,000 x 200 tokens x $0.14/M = $0.03/day
- Output (weighted): ~$12/day
- Total: ~$25/day, $770/month.
Savings: $1,030/month. 57% reduction. Same output quality on every individual task because each task runs on a model capable of handling it.
Model routing isn't about using worse models. It's about not using expensive models on tasks that don't need them. 65% of typical agent tasks are Tier 1. Those tasks cost 21x less on Flash than on Sonnet, with identical results.
Four Gotchas That Break Routing in Production
Gotcha 1: The classifier misclassifies
Your classifier will get some tasks wrong. A complex task gets routed to Flash. Flash produces a bad result. The user sees low quality.
Fix: Log every classification decision. Review misclassifications weekly. Add misclassified examples to the classifier prompt as few-shot examples. Over time, the classifier gets more accurate for your specific workload.
Gotcha 2: Context size varies wildly
The cost math assumes 10,000 tokens per task. But some tasks have 500 tokens and others have 50,000. A 50K-token Tier 1 task on Flash still costs almost nothing ($0.007). A 50K-token Tier 3 task on Opus costs $0.25. If you have many large-context tasks, add a context-size multiplier to your routing logic.
Gotcha 3: Latency differences between providers
DeepSeek V4 Flash and Claude Opus have different latency profiles. If your agent chains a Tier 1 classification into a Tier 2 draft, the total latency includes two model calls across two providers. For latency-sensitive agents, consider using models from the same provider for sequential calls.
Gotcha 4: Prompt caching breaks across providers
Anthropic's 90% cache discount applies when the same prefix is sent repeatedly to Claude models. But if your Tier 1 tasks go to DeepSeek and your Tier 2 tasks go to Claude, you lose the caching benefit on the Claude calls because they're intermittent. If your workload is Anthropic-heavy, routing within the Anthropic family (Haiku for Tier 1, Sonnet for Tier 2, Opus for Tier 3) preserves caching.
The No-Code Version (Skip the Python)
All of this — the classifier, the routing logic, the model switching, the fallback handling — is infrastructure work. If you're building agents for your business (not building an agent framework), the routing logic is plumbing you maintain but never want to think about.
On BetterClaw, model selection is a dropdown in the visual builder. 28+ providers available via BYOK. Switch from DeepSeek Flash to Claude Sonnet to Opus with one click. The platform handles the API integration, authentication, and error handling for each provider. Smart context management prevents token bloat regardless of which model you use. Free plan with 1 agent and 500 credits a month. $49/month on Pro. Zero inference markup.
For teams that want automatic routing without writing code, per-agent cost caps ensure your agent never exceeds your budget regardless of which model handles the task.
Beyond Three Tiers (Advanced Patterns)
Once basic routing works, two advanced patterns save even more:
Task-type routing. Instead of three generic tiers, route by specific task type. Email classification always goes to Flash. Email drafting always goes to Sonnet. Escalation decisions always go to Opus. This eliminates the classifier entirely for known task types. You only need the classifier for unknown or new task types.
Cascade routing. Start every task on Flash. If Flash's confidence score (or output quality signal) is below a threshold, re-run on Sonnet. If Sonnet's output is below threshold, escalate to Opus. This guarantees the cheapest possible model is tried first. The downside: failed attempts waste tokens. The upside: for workloads where 80%+ of tasks are simple, the waste on the 20% is less than routing everything to mid-tier.
Gartner projects 40% of enterprise applications will embed AI agents by end of 2026. At scale, the difference between $0.14/M and $3/M per task is the difference between a sustainable agent deployment and an unsustainable one. Model routing isn't optimization. It's a requirement.
Build the router. Match the model to the task. Pay for what you need.
Give BetterClaw a look if you want model routing without managing infrastructure. Free plan with 1 agent and 500 credits a month. $49/month for Pro. 28+ providers via BYOK with zero markup. We handle the plumbing. You handle the agent logic.
Frequently Asked Questions
What is AI agent model routing?
Model routing is the practice of sending different agent tasks to different AI models based on task complexity. Simple tasks (classification, extraction) go to cheap, fast models like DeepSeek V4 Flash ($0.14/M). Moderate tasks (drafting, analysis) go to mid-tier models like Claude Sonnet ($3/M). Complex tasks (reasoning, judgment) go to frontier models like Opus 4.8 ($5/M). This reduces costs by 40-60% without degrading output quality on any individual task.
How much does model routing save on AI agent costs?
For a typical agent processing 1,000 tasks per day, routing saves approximately 57% compared to running everything on a mid-tier model. In dollar terms: $1,800/month (all Sonnet) drops to $770/month (routed). The savings come from the fact that 65% of typical agent tasks are simple enough for a $0.14/M model, which is 21x cheaper than Sonnet's $3/M.
How do I classify tasks for model routing?
Use your cheapest model (DeepSeek V4 Flash) to run a classifier prompt that categorizes each incoming task as simple, moderate, or complex. The classifier adds approximately 200 tokens per task (~$0.03/day at 1,000 tasks). Default to mid-tier if the classifier returns an unexpected result. Log all classifications and review weekly to improve accuracy over time with few-shot examples.
Can I do model routing without code on BetterClaw?
Yes. BetterClaw supports 28+ model providers via BYOK. You select your model from a dropdown in the visual builder. Switching from DeepSeek to Claude to Opus requires no code change. Per-agent cost caps act as automatic budget enforcement. Smart context management prevents token bloat regardless of which model handles the task. Free plan available with 1 agent and 500 credits a month.
Does model routing affect output quality?
Not when implemented correctly. Each task runs on a model that's capable of handling it. Simple tasks (classification, extraction) produce identical results on Flash vs Sonnet. The quality difference between models only appears on complex, nuanced tasks, which routing sends to the frontier model anyway. The key: validate your classifier's accuracy. Misclassified complex tasks sent to cheap models will produce lower-quality output.
Route without the plumbing.
Pick any model from a dropdown, set a per-agent cost cap, deploy in 60 seconds. BYOK with zero markup. Free forever, not a trial. Start free →