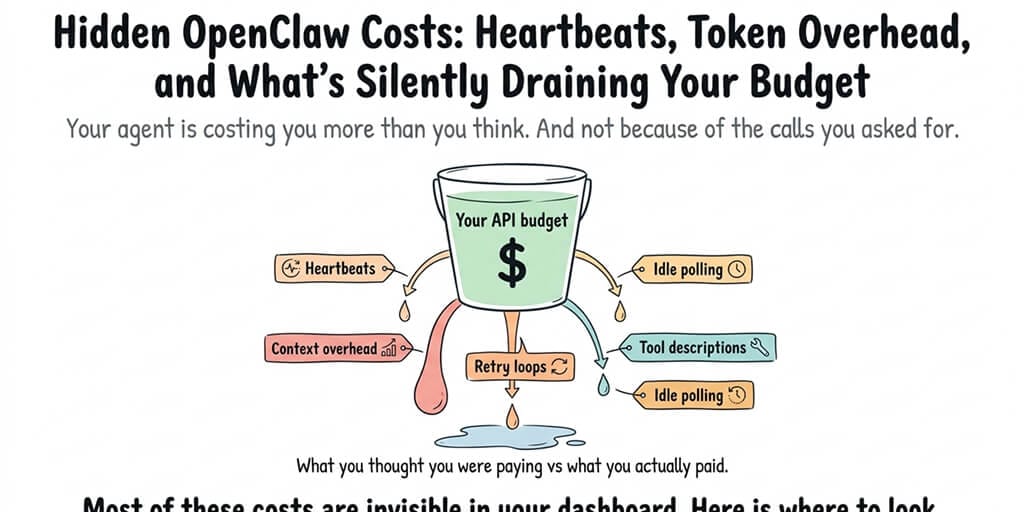
Your agent is costing you more than you think, and not because of the calls you asked for.
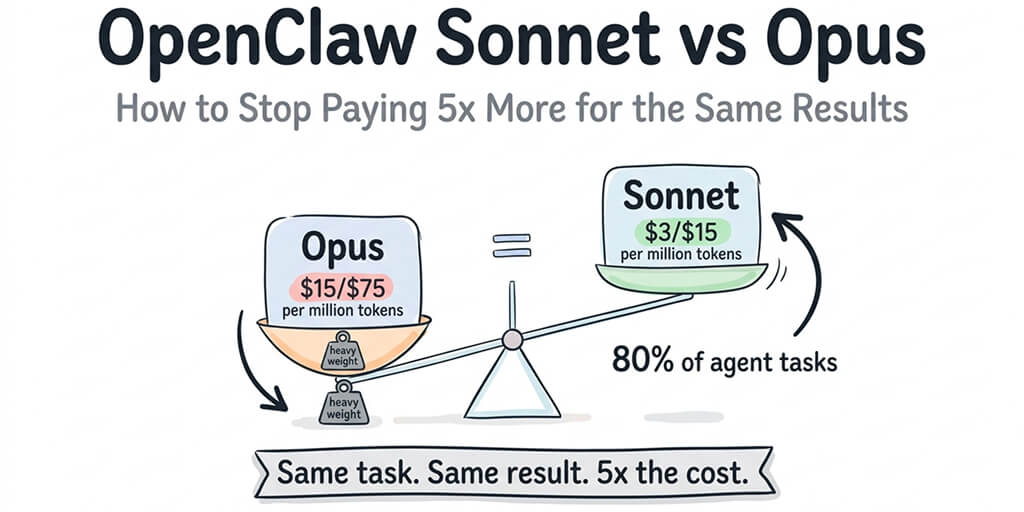
$178 in a week.
That's what a guy on Medium spent on AI agent API calls before his post went viral with the title "I Spent $178 on AI Agents in a Week." His actual agent work wasn't the problem. The problem was everything else happening in the background while the agent was technically doing nothing.
I've seen teams spend 3x that and not realize until the billing email hit. Not because their agent was busy. Because their agent was breathing.
That's what this post is about. Hidden OpenClaw costs. The heartbeats, the context overhead, the loops that never quite die, the tool descriptions that silently re-send themselves a hundred times a day. The stuff nobody warns you about until you're looking at a $600 Anthropic bill wondering what you actually bought.
The five places your money is actually going
Most people think of agent cost as "the tokens my agent used on real work." That's maybe half of it. Often less.
Here's what the other half looks like.
Heartbeats. Your agent needs to know it's alive, connected, and ready. Some deployments do this with actual model calls on a schedule. Even tiny calls, multiplied by "every 30 seconds, forever, in the background," add up to real money.
Context overhead. Every time your agent responds to a new message, it re-sends its system prompt, its tool definitions, its memory snippets, and often its recent conversation history. A chatty conversation with 30 turns means the context gets rebuilt 30 times.
Tool descriptions. Every tool your agent has access to gets described in the prompt. A Slack tool is maybe 200 tokens. A GitHub tool is 400. If you've installed 15 skills and your agent sees them all on every call, that's thousands of tokens of "here's what you can do" re-sent on every single turn.
Retry loops. Your agent tried something. It didn't work. It tried again with a slight variation. Then again. Then again. Somewhere around try 12 you realize the loop never had a kill switch, and you've just paid for 40 calls of the agent arguing with itself.
Idle polling. Your agent is "waiting" for something. In most implementations, waiting isn't free. It's a regular check, a status call, a refresh of state. Not a lot per check. A lot of checks.
Five leaks. Any one of them can double your bill. Together they quietly eat half of most production agent budgets.
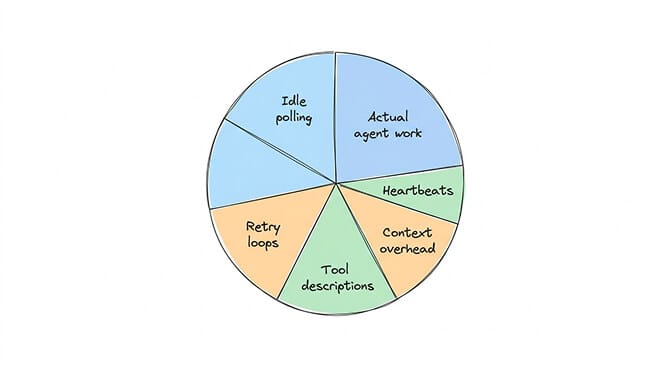
The heartbeat trap
Let me spend a minute on heartbeats because this one bit me personally.
The concept is reasonable. Your agent needs to know it's connected to its chat platform, its memory store, its skill registry. It needs to respond to inbound messages quickly, which means it needs to be warm. It needs to signal liveness so supervisors can detect when it's dead.
All fine. Until you realize how it's implemented.
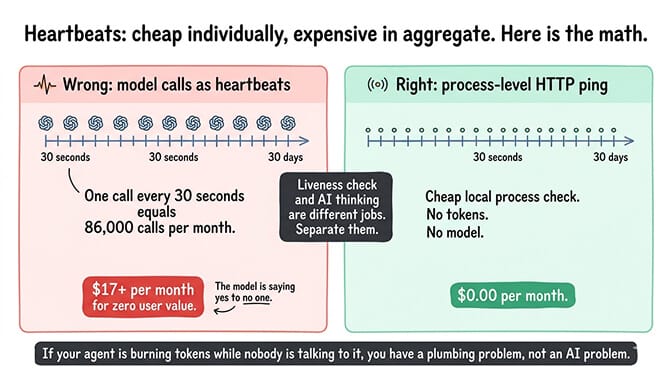
Some setups send actual model calls as heartbeats. Tiny prompts like "are you ready?" and the model replies "yes." Cheap individually. Expensive in aggregate. At one call every 30 seconds for a month of uptime, you're looking at roughly 86,000 calls. Even at $0.0002 per call, that's a real line item for a feature that produced zero value for your user.
The fix is to separate "am I alive" from "am I thinking." Liveness can be a cheap HTTP ping to a local process. Thinking should be reserved for actual user-initiated work.
If your agent is burning tokens while nobody's talking to it, you've got a plumbing problem, not an AI problem.
Most production-ready setups already handle this correctly. A lot of hand-rolled self-hosted deployments do not.
The token overhead nobody teaches you about
The second big leak is context overhead, and this one compounds in a way that surprises people the first time they see it.
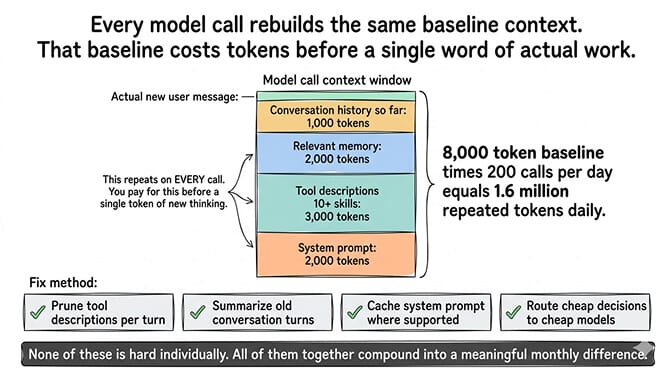
Every model call has a context window. Everything you put in it costs tokens. On every call, your agent's context gets rebuilt with roughly the same baseline stuff: the system prompt, the tool descriptions, the relevant memory, the conversation so far. If that baseline is 8,000 tokens (which is modest for a real agent with 10+ skills), and your agent does 200 calls a day, you're paying for 1.6 million tokens of repeated context before a single token of actual new thinking happens.
The 136K token overhead problem is the same phenomenon at the session level. The longer a conversation runs, the more tokens each new turn costs, because the whole conversation gets re-sent.
The fix isn't one thing. It's a stack of small things.
Pruning tool descriptions so the agent only sees tools relevant to the current turn. Summarizing old conversation turns into compact memory notes instead of re-sending the full history. Caching the system prompt on the provider side where that's supported. Routing cheap decisions to a cheap model and expensive decisions to an expensive one.
None of these is hard individually. All of them together compound into a meaningful difference in monthly bill.
The retry loop that ate $40
Retry loops are where hidden costs become actively embarrassing.
Here's the pattern. Your agent tries to do a thing. The tool call fails, maybe because an API key expired, maybe because a service was rate-limited, maybe because the model produced a malformed argument. The agent sees the error. The agent decides to try again. Same result. Tries again. Same result.
If there's no upper bound on retries, and no escalation path to a human, your agent will happily burn through your budget over the course of an hour and accomplish exactly nothing. I've seen a documented case of a misconfigured agent burning $40 of calls overnight because it was retrying the same broken action 400 times.
The fix is a retry budget, not a retry disabling. You want some retry behavior because transient failures are real. What you don't want is unlimited retries with no cost ceiling.
Three retries with exponential backoff. Then escalate to a human. Or pause. Either beats the agent spiraling.
If you don't want to hand-wire retry budgets, context pruning, heartbeat separation, and token overhead monitoring yourself, BetterClaw has cost controls built into every managed agent, including auto-pause on spend anomalies. $49/month for Pro, BYOK, and you stop having to audit your own bills to spot leaks.
The skill description tax
The fourth leak is specific to the OpenClaw way of doing things, and it's worth calling out because it's counterintuitive.
OpenClaw's power comes from skills. You install a GitHub skill, a Slack skill, a Notion skill, a payments skill, a memory skill, and suddenly your agent can do a lot. That's the point.
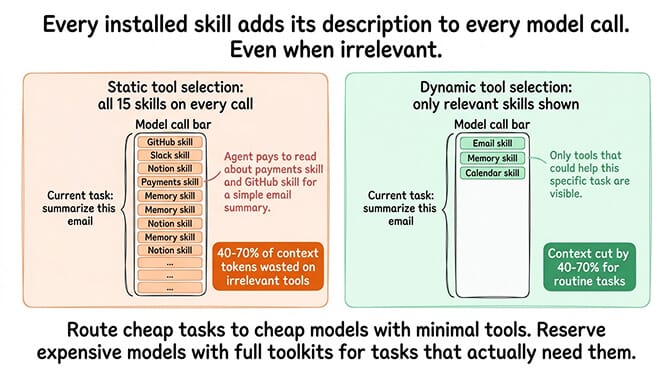
The tax: every one of those skills has a description the model needs to see in order to know what to call. When your agent has 15 skills installed, every single model call includes ~15 skill descriptions in its context, whether the current task needs them or not.
For a simple "summarize this email" request, your agent doesn't need the payments skill. It doesn't need the GitHub skill. But it's paying for the tokens to read about them anyway.
The best setups use dynamic tool selection: only show the model the skills that might be relevant to the current task. For teams running lots of skills, this alone can cut context overhead by 40% to 70%.
If you're building out your skill set and want to keep costs sane, the smart model routing approach pairs well with tool pruning. Route cheap tasks to cheap models with minimal tools. Reserve the expensive model with the full toolkit for the rare tasks that actually need it.
The self-hosting cost math that nobody runs
Self-hosting OpenClaw looks cheap on paper. Your VPS is $10 a month. You BYOK on APIs. Done, right?
Here's the weird part. Most of the hidden costs above are implementation choices, and self-hosted setups tend to make the expensive choices by default.
Default heartbeat interval too aggressive? You pay. Default tool selection shows all skills on every call? You pay. No retry budget, no loop limits, no anomaly pause? You pay. No monitoring to catch any of this until the bill arrives? You pay for a whole month before you notice.
I've watched founders save $15/month on infrastructure and lose $200/month to token leaks they couldn't see. There's a good breakdown in how hosting costs actually compare across providers if you want to run the full math.
The honest version: self-hosted OpenClaw can be cheaper than managed. It's cheaper only if you've done the hard work of configuring all five leak points correctly, set up cost monitoring, and are willing to audit your spend regularly.
If you haven't done that work, managed is almost always cheaper once you include the leaks. That's why BetterClaw pricing sits at $49/month for Pro instead of trying to compete with raw VPS costs. You're not paying for a server. You're paying for the configuration that keeps your API bill from doubling silently.
What to audit tomorrow morning
If you're running agents in production and haven't looked at this stuff, here's the list. Ten minutes of auditing saves real money.
Check your heartbeat behavior. See if it's using model calls or process-level pings. If model calls, figure out the frequency and the cost per month.
Count your installed skills. Compare against skills actually used in the last 30 days. Uninstall dead weight.
Look at your longest conversation sessions. If they're running over 100 turns without memory compaction, your context overhead is eating you alive. Related reading: how to reduce OpenClaw API costs walks through the compaction strategy.
Search your logs for retry patterns. Any action that retried more than 5 times in a session is a bug, not a strategy.
Set a daily spend alert at your provider. If you're spending more tomorrow than you spent today, you want to know before the week ends.
One last thing
The framing shift that matters most: agent cost is not "model calls." Agent cost is "all the plumbing between you and the thing you actually wanted."
Most of the cost lives in the plumbing. Most of the savings live there too. The teams that figure this out early are the ones whose agents stay profitable as they scale. The teams that don't are the ones quietly switching off agents in Q3 because the API bill stopped making sense.
If you've been watching your agent costs creep up and can't figure out where the money is going, give BetterClaw a try. $49/month for Pro, BYOK, with auto-pause on spend anomalies, dynamic tool selection, heartbeat separation, and cost monitoring baked in. First deploy takes about 60 seconds. We handle the plumbing. You keep the savings.
Agents are going to get more capable, more persistent, and more numerous. The operators who stay sane in that world are the ones who treat token overhead the same way good cloud operators treat idle EC2 instances. Unacceptable by default. Reviewed every month. Killed when they stop earning their keep.
Frequently Asked Questions
What are hidden OpenClaw costs?
Hidden OpenClaw costs are the API charges your agent accumulates on things other than actual user-requested work. The five main categories are heartbeats, context overhead, tool descriptions, retry loops, and idle polling. Together, these often account for 30% to 60% of an agent's monthly API spend, depending on how the agent is configured.
How do OpenClaw hidden costs compare to visible token costs?
Visible token costs are the model calls your agent makes in response to a user request. Hidden costs are everything else: liveness checks, re-sent context, repeated tool descriptions, and stuck retry loops. Visible costs scale with user activity. Hidden costs scale with uptime, number of installed skills, and how carefully the agent is configured. Many teams find hidden costs exceed visible costs before they realize it.
How do I reduce OpenClaw token overhead in my agent?
Start with four changes: prune installed skills you don't use, enable dynamic tool selection so only relevant skills get included per call, compact long conversation histories into summaries, and cache your system prompt where your model provider supports it. The combination typically cuts token overhead by 40% to 70% without changing what the agent can actually do.
Is running OpenClaw really worth it once you include hidden costs?
Yes, if you configure it properly. OpenClaw itself is free and extremely capable. The question is whether you want to do the configuration work yourself or pay a managed platform like BetterClaw at $49/month for Pro to handle it for you. For most production use cases, paying for managed configuration is cheaper than paying for hidden leaks.
Are these hidden costs a problem on managed platforms too?
They can be, but less so. Managed platforms that are purpose-built for OpenClaw (with heartbeat separation, tool pruning, retry budgets, and anomaly auto-pause) address most of the leaks by default. The leaks show up hardest in hand-rolled self-hosted setups where the defaults were never tuned. Always check whether your managed platform specifically addresses agent cost leaks, not just infrastructure costs.