

One costs $0.98 per million tokens. The other costs $3. Both support tool calling. Both work with BYOK. Here's when each one actually wins.
We'd been running Claude Sonnet 4.6 on everything. Support agent. Research agent. CRM updater. Email triage. All Sonnet. All day.
The API bill was $340 last month. Fine for the quality. But then someone on the team plugged GLM 5.1 into the same email triage agent as a test. Same prompt. Same tools. Same data.
The outputs were... basically the same. Not identical. But for classifying emails into five categories and extracting sender, subject, and urgency? The difference was invisible. The cost was $98 instead of $340.
That's the GLM 5.1 question in one scenario. For structured, high-volume agent tasks, is the 3x price difference between GLM 5.1 vs Claude Sonnet 4.6 justified? Sometimes yes. Sometimes no. Here's when each one wins.
The one-line verdict
GLM 5.1 is the better default for high-volume, cost-sensitive agent tasks (classification, extraction, CRM updates, routing). Sonnet 4.6 is the upgrade when you need precise instruction following, nuanced reasoning, or multimodal input. For most BYOK agent builders, start on GLM 5.1 and escalate to Sonnet when the task demands it. (Z.ai has since shipped a stronger version — our GLM 5.2 vs Sonnet 4.6 test covers the upgrade.)
Pricing side by side (the gap is real)
GLM 5.1: $0.98/M input, $3.08/M output via OpenRouter. Blended across 10 providers: $0.74 to $1.70/M. DeepInfra cached input: $0.205/M. Z.ai's own API offers a generous free tier for testing. (For an even cheaper Sonnet challenger, see our MiniMax M3 vs Claude Sonnet 4.6 comparison.)
Claude Sonnet 4.6: $3/M input, $15/M output via Anthropic API. Cached input: $0.30/M (90% discount on repeated prefixes).
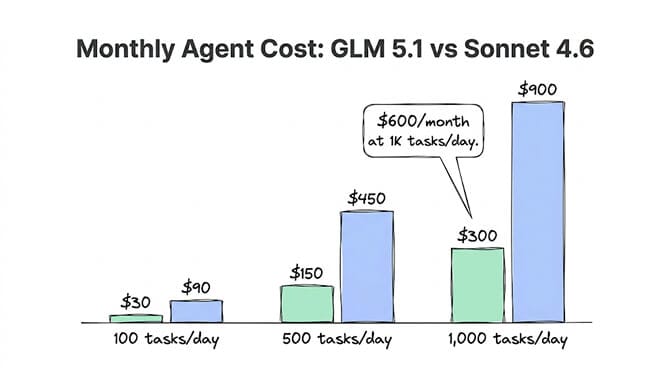
The math: GLM 5.1 is 3x cheaper on input and 5x cheaper on output. For an agent processing 1,000 tasks per day at 10,000 tokens per task, that's roughly $10/day on GLM 5.1 vs $30/day on Sonnet 4.6. Over a month: $300 vs $900.
With prompt caching, the gap narrows. Sonnet's 90% cache discount ($0.30/M) gets close to GLM 5.1's DeepInfra cached rate ($0.205/M) on repeated system prompts and tool definitions. But output tokens are never cached, and Sonnet's output at $15/M is nearly 5x GLM 5.1's $3.08/M. For agents that generate long responses, output cost dominates.
For high-volume agent workloads, GLM 5.1 saves $600+/month over Sonnet 4.6 on a typical 1,000-task/day agent. The quality gap on structured tasks (classification, extraction, routing) is negligible.
Speed: GLM 5.1 is faster on most providers
GLM 5.1 output speed ranges from 33.8 to 175.2 tokens per second across 10 benchmarked providers. The fastest (Fireworks) is 5.2x quicker than the slowest.
Sonnet 4.6 runs at approximately 50-80 tok/s depending on the provider and load.
For agents where response latency matters (real-time chat, customer-facing responses), GLM 5.1 on Fireworks or DeepInfra is noticeably faster. For scheduled background agents (email triage, CRM updates, report generation), speed differences don't matter.
Coding and tool-use performance (the agent-specific numbers)
This is where people get confused. Benchmark scores are published for Opus 4.6, not Sonnet 4.6. The comparison that matters for agent builders is Sonnet-tier vs GLM 5.1 on the tasks agents actually perform.
GLM 5.1 benchmarks:
SWE-Bench Pro: 58.4 (beating GPT-5.4's 57.7 and Claude Opus 4.6's 57.3). AIME 2026: 95.3. CyberGym: 68.7 (vs Opus 4.6's 66.6). Agentic index: 70.4. MCP-Atlas Public: 71.8. IFBench (instruction following): 0.763.
Claude Sonnet 4.6 strengths:
Tool calling with only 3% hallucination rate (the lowest measured among frontier models). Strong at maintaining instruction adherence over long conversations. Multimodal input (text + image) while GLM 5.1 is text-only. Better at nuanced, subjective tasks (tone calibration, complex reasoning, ambiguous instructions).
Here's the honest assessment.
For structured agent tasks (classify this email, extract these fields, update this CRM record, route this ticket), GLM 5.1 performs comparably to Sonnet 4.6 at one-third the cost. The tasks are well-defined, the output format is predictable, and the model's job is execution, not judgment.
For judgment-heavy tasks (should we escalate this customer complaint? is this code review comment actually a bug or a style preference? does this email need a sensitive response?), Sonnet 4.6's instruction following and reasoning quality justifies the premium. The difference shows up on edge cases, not averages.
Context window: nearly identical
GLM 5.1: 202,752 tokens (~203K). Claude Sonnet 4.6: 200,000 tokens (200K). For practical purposes, the same. Both handle large documents, long conversation histories, and multi-tool agent contexts without truncation.
GLM 5.1's unique feature: up to 131K output tokens. Sonnet 4.6 caps at 8,192 by default (configurable higher with extended thinking). If your agent needs to generate very long outputs (detailed reports, extensive code, comprehensive summaries), GLM 5.1's output limit gives more room.
Which model wins for which agent task
Here's the breakdown we use internally. Not benchmarks. Actual production experience across 50+ companies on BetterClaw.
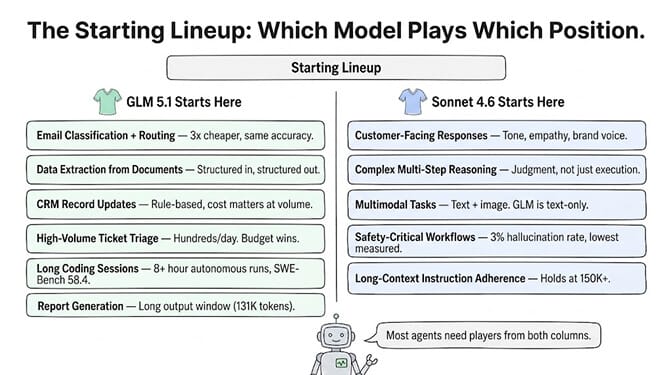
GLM 5.1 wins on:
Email classification and routing. The task is structured, the categories are defined, and GLM 5.1 handles it at 3x less cost with equivalent accuracy.
Data extraction from documents. Pull vendor name, amount, date from invoices. Pull contact info from business cards. Structured input, structured output.
CRM record updates. Read a conversation summary, update the correct HubSpot fields. Rule-based with mild reasoning.
High-volume ticket triage. Classify, assign priority, route. Hundreds or thousands per day. Cost matters here.
Long-horizon coding sessions. GLM 5.1 is specifically designed for 8+ hour sustained autonomous coding. If your agent writes and iterates on code, GLM 5.1's SWE-Bench Pro 58.4 is competitive with frontier models at a fraction of the cost. (We ran it for a month — see our 30-day GLM 5.1 review.)
Sonnet 4.6 wins on:
Customer-facing responses where tone matters. Sonnet's instruction following produces more natural, empathetic, brand-consistent output. Worth the premium for external communications.
Complex multi-step reasoning. When the agent needs to plan, evaluate alternatives, and make judgment calls (not just execute a defined workflow), Sonnet's reasoning is measurably better.
Multimodal tasks. If your agent needs to read images (screenshots, documents as images, product photos), GLM 5.1 can't do this at all. It's text-only. Sonnet 4.6 handles text + image natively.
Safety-critical workflows. Sonnet 4.6's 3% tool-call hallucination rate is the lowest measured. For agents handling financial data, medical information, or legal documents, lower hallucination matters more than lower cost.
If you're running agents on BetterClaw and want to use both models in the same workflow (GLM 5.1 for triage, Sonnet for customer responses), the visual builder supports 28+ providers via BYOK. Switch models with a dropdown. No code change. Free plan with 1 agent and 500 credits a month. $49/month on Pro. Zero inference markup on either model.
The real answer for BYOK agent builders
Here's what we recommend.
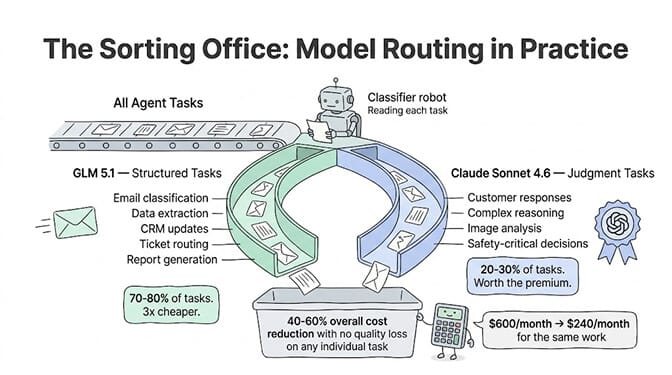
Set GLM 5.1 as your default. For the 70-80% of agent tasks that are structured, repetitive, and well-defined, GLM 5.1 delivers equivalent quality at one-third the cost. Email triage, data extraction, CRM updates, ticket routing, report generation.
Escalate to Sonnet 4.6 when the task demands it. Customer-facing communication, complex reasoning, image input, safety-critical decisions. These justify the 3x premium.
Use model routing to automate the choice. Classify the incoming task, pick the model. Simple tasks go to GLM 5.1. Complex tasks go to Sonnet. This model routing pattern cuts costs by 40-60% without quality loss on any individual task.
Gartner projects 40% of enterprise applications will embed AI agents by end of 2026. The teams that run every task through a frontier model will overpay. The teams that route intelligently will build more agents, cover more workflows, and keep their API bills sustainable.
GLM 5.1 isn't better than Sonnet 4.6. Sonnet 4.6 isn't better than GLM 5.1. They're better at different things. Use both.
Give BetterClaw a look if you want both models available from the same dashboard. Switch between GLM 5.1 and Sonnet 4.6 (and 26 other providers) with a dropdown. Free plan with 1 agent and 500 credits a month. $49/month for Pro. BYOK with zero markup. You bring the API key. We bring the infrastructure.
Frequently Asked Questions
How does GLM 5.1 compare to Claude Sonnet 4.6 for AI agents?
GLM 5.1 ($0.98/M input) is 3x cheaper than Sonnet 4.6 ($3/M input) and performs comparably on structured agent tasks like email classification, data extraction, and CRM updates. Sonnet 4.6 wins on nuanced instruction following, customer-facing tone, multimodal input (GLM 5.1 is text-only), and safety-critical workflows with its industry-low 3% tool-call hallucination rate. For BYOK agent builders, the optimal approach is to use GLM 5.1 as the default for high-volume tasks and escalate to Sonnet 4.6 for judgment-heavy work.
Is GLM 5.1 free to use?
Z.ai (formerly Zhipu AI) offers a generous free tier on their direct API for testing and development. For production use, GLM 5.1 costs $0.98/M input and $3.08/M output on OpenRouter, with blended pricing as low as $0.74/M across 10 providers. DeepInfra offers cached input at $0.205/M. The model weights are available on HuggingFace under MIT license, so self-hosting is possible with appropriate hardware (minimum 1x NVIDIA HGX B200).
Which is faster: GLM 5.1 or Claude Sonnet 4.6?
GLM 5.1 is generally faster. Output speed ranges from 33.8 to 175.2 tokens per second across 10 benchmarked providers, with Fireworks being the fastest at 175.2 tok/s. Claude Sonnet 4.6 runs at approximately 50-80 tok/s depending on provider and load. For latency-sensitive agent tasks (real-time chat, customer-facing responses), GLM 5.1 on a fast provider like Fireworks or DeepInfra delivers noticeably faster responses.
How much can I save by switching from Sonnet 4.6 to GLM 5.1?
For a typical agent processing 1,000 tasks per day at 10,000 tokens per task: GLM 5.1 costs approximately $300/month vs Sonnet 4.6 at approximately $900/month. That's $600/month savings per agent. The savings scale linearly with volume. For 5 agents at similar volume, switching structured tasks to GLM 5.1 saves $3,000/month. The key: switch only the tasks where GLM 5.1 matches quality (classification, extraction, routing), not the tasks where Sonnet's precision matters (customer communication, complex reasoning).
Can GLM 5.1 handle tool calling and function calling for agents?
Yes. All 10 benchmarked API providers support function calling with GLM 5.1, and 9 of 10 support JSON mode. The model scored 70.4 on the agentic index and 71.8 on MCP-Atlas Public, confirming strong tool-use performance. For sustained agentic work, GLM 5.1 is specifically designed for 8+ hour autonomous runs with thousands of tool calls. It maintains performance across long sessions better than models designed for single-turn interactions.



