Eight thinking levels. Different defaults per provider. Cost that can triple without warning. Here's the complete reference that doesn't exist anywhere else.
A user in the OpenClaw Discord was confused about thinking mode. His agent used Claude Sonnet and suddenly felt "more thoughtful" on hard tasks but slower on simple ones. He hadn't changed any settings.
OpenClaw v2026.3.1 changed the default thinking level for Claude 4.6 models to "adaptive" without any notification in the chat.
His simple FAQ bot was now pausing to reason before answering "What are your business hours?" That pause cost tokens. Those tokens cost money. He didn't know why.
This is the reference post for OpenClaw thinking mode. What the eight levels are, how they differ across providers, what they cost, and when to turn each one on or off.
What thinking mode actually does (the 30-second version)
Thinking mode controls how much the model reasons before responding. When enabled, the model generates an internal reasoning chain (thinking tokens) before producing the visible response. You pay for thinking tokens. The user doesn't see them by default.
More thinking = better accuracy on complex tasks (multi-step reasoning, coding, research). More thinking = wasted time and money on simple tasks (FAQ, greetings, scheduling).
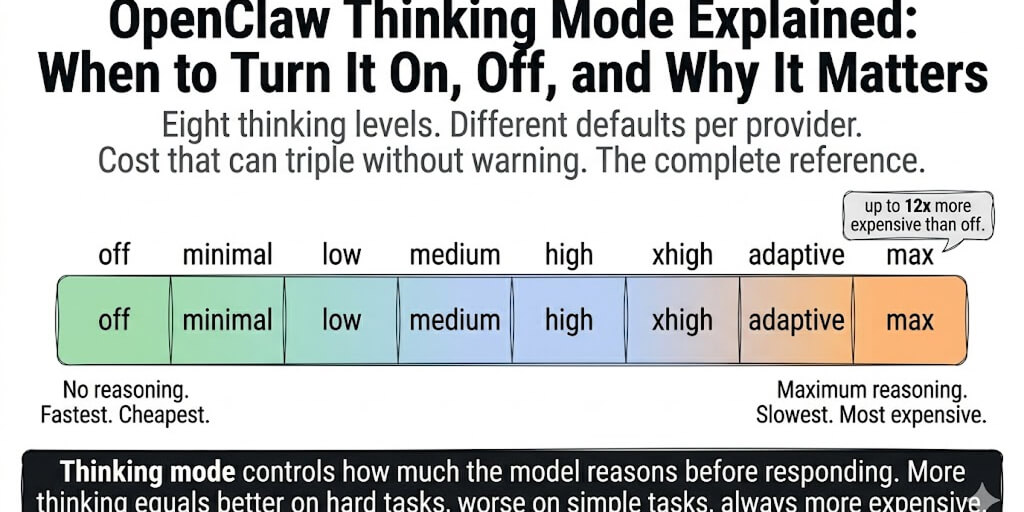
The eight levels: off, minimal, low, medium, high, xhigh, adaptive, max.
The hierarchy: Per-message directive > Session override > Per-agent default > Global default > Provider fallback.
That means you can set a global default of "low," override a specific agent to "high," and still push individual messages to "max" with /think max inline.
The key insight: Thinking mode is not on/off. It's a spectrum. The right level depends on the task, the model, and whether you're willing to trade speed and cost for accuracy. Most agents should run at "low" or "adaptive," not "high" or "max."
The eight levels (and what each one actually does)
- off: No reasoning. Fastest response. Cheapest. Use for heartbeats, simple Q&A, FAQ bots, and any task where the answer is straightforward. The model generates responses without an internal reasoning chain.
- minimal / low: Light reasoning. Slightly slower. Slightly more expensive. The sweet spot for conversational agents handling routine tasks with occasional complexity. Low is the default for non-Claude reasoning-capable models.
- medium: Moderate reasoning. Noticeably slower on simple tasks. Better on multi-step instructions. The former default before adaptive was introduced.
- high: Heavy reasoning. The model pauses visibly. Good for research, analysis, and coding tasks. Expensive on long conversations.
- xhigh / max: Maximum reasoning budget. Use only for the hardest tasks (multi-step research, complex debugging, financial analysis). The model can take 30-90 seconds before starting to stream. Max maps differently across providers (see provider section below).
- adaptive: The model decides how much to think based on task complexity. Simple questions get fast answers. Complex questions get deep reasoning. Adaptive is the default for Claude 4.6 models since OpenClaw v2026.3.1.

For the complete cost optimization guide, our OpenClaw cost reduction guide covers how thinking mode interacts with token costs and heartbeat routing.
The provider mess (this is where it gets confusing)
Here's what nobody tells you about OpenClaw thinking mode.
Each provider maps the same /think levels differently. The same /think high command produces different behavior depending on whether you're using Anthropic, DeepSeek, Ollama, OpenAI, or OpenRouter.
- Anthropic (Claude 4.6, Opus 4.7): Full level support. Adaptive is the default for Claude 4.6. Opus 4.7 supports all levels including max. Thinking content is hidden by default on Opus 4.7 (you still pay for thinking tokens, you just don't see them unless you enable
/reasoning on). - DeepSeek V4 (direct):
/think xhighand/think maxboth map to DeepSeek'sreasoning_effort: "max". Lower levels map to "high." The level granularity is less fine-grained than Anthropic. - DeepSeek V4 (via OpenRouter): Slightly different. Stored max overrides fall back to xhigh due to an OpenRouter compatibility issue — the same bug from GitHub issue #77350 that we covered in the DeepSeek 503 post.
- Ollama: Supports low, medium, high, max. But max maps to Ollama's native "high" (Ollama's API only accepts low/medium/high). Known regression (issue #73366): After v2026.4.26, thinking is forced to false for all Ollama models regardless of configuration. If your Ollama agent stopped thinking after an update, this bug is why.
- Z.AI: Binary only. Any non-off level = on, mapped to low. No granularity.
- Moonshot: Binary. Off = disabled. Everything else = enabled. When thinking is active,
tool_choiceis restricted toautoornone.
The provider rule: Don't assume /think high means the same thing across providers. Check your provider's supported levels. OpenClaw normalizes the interface, but the backend behavior varies significantly.

The cost impact (the part that matters most)
Thinking tokens are real tokens. You pay for them.
A simple question with thinking off: ~200-400 output tokens. The same question with thinking on high: ~800-2,000 output tokens (200-400 visible + 400-1,600 thinking). The same question with thinking on max: ~2,000-5,000+ output tokens.
On Claude Opus 4.7 at $25/M output tokens: Thinking on max can cost 5-12x more per message than thinking off. Over 50 messages/day, that's the difference between $5/month and $40/month just from thinking mode.
On heartbeats specifically: If your heartbeat model runs with thinking enabled, every 55-minute heartbeat generates thinking tokens for a "check if anything needs doing" task. That's reasoning tokens spent on the simplest possible check. Always set heartbeats to thinking: off. The hidden heartbeat token overhead post covers the math.
If managing per-agent thinking levels, provider-specific mappings, and cost implications sounds like more configuration than you want, BetterClaw handles thinking mode optimization at the platform level. The platform routes thinking levels by task type automatically. No /think commands. No provider compatibility issues. No heartbeats burning thinking tokens. Free tier with 1 agent and BYOK. $19/month per agent for Pro.

The recommended config (for multi-agent setups)
For the best practices on agent configuration, our OpenClaw best practices guide covers the broader config patterns. Here's the thinking-specific recommendation:
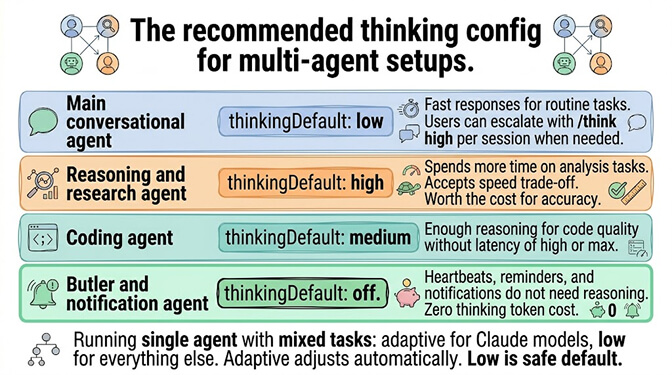
- Main conversational agent:
thinkingDefault: "low". Fast responses for routine tasks. Users can escalate with/think highwhen needed. - Reasoning/research agent:
thinkingDefault: "high". Spends more time on analysis. Accepts the speed trade-off. - Coding agent:
thinkingDefault: "medium". Enough reasoning for code quality without the latency of high/max. - Butler/notification agent:
thinkingDefault: "off". Heartbeats, reminders, and notifications don't need reasoning.
If running a single agent with mixed tasks: thinkingDefault: "adaptive" (Claude only) or "low" (other models). Adaptive adjusts automatically. Low is a safe default that doesn't waste tokens on simple tasks.
Thinking vs reasoning (the confusion that costs people money)
One more thing. Thinking level and reasoning visibility are separate settings.
Thinking level (/think) controls how much the model reasons internally. This affects quality and cost.
Reasoning visibility (/reasoning) controls whether you see the thinking blocks. Options: on, off, stream (Telegram only). This affects what shows up in your chat.
You can have thinking on high (model reasons deeply, you pay for it) with reasoning off (you don't see the thinking blocks). You're still paying for the thinking tokens. You just can't see them.
The common mistake: Users set /reasoning off thinking they've disabled thinking. They haven't. They've hidden the display. The model still reasons. The bill still reflects it. To actually stop the model from reasoning, use /think off.
If you want thinking mode managed without the provider differences, known regressions, and display/cost confusion, give BetterClaw a try. Free tier. $19/month Pro. 28+ providers. Thinking optimization is automatic. No /think commands needed. The platform matches reasoning depth to task complexity. You get the quality where it matters and the speed where it doesn't.
Frequently Asked Questions
What is OpenClaw thinking mode?
Thinking mode controls how much internal reasoning the model does before producing a visible response. Eight levels from off (no reasoning, fastest, cheapest) to max (maximum reasoning, slowest, most expensive). The model generates "thinking tokens" that you pay for but don't see by default. More thinking = better on complex tasks, wasted on simple ones.
What is the default thinking level in OpenClaw?
Adaptive for Claude 4.6 models (since v2026.3.1), low for other reasoning-capable models, and off for non-reasoning models. You can override at four levels: per-message directive, session override, per-agent config, or global config. Per-message directives always take priority.
How much does thinking mode cost in OpenClaw?
Thinking on max can cost 5-12x more per message than thinking off because the model generates extensive internal reasoning chains. On Opus 4.7 at $25/M output tokens, 50 messages/day at max thinking can cost $40/month versus $5/month with thinking off. Always disable thinking for heartbeats and simple tasks to avoid unnecessary costs.
Why does my OpenClaw agent feel slower after updating?
If you updated to v2026.3.1 or later, Claude 4.6 models now default to adaptive thinking (previously off or low). Adaptive makes simple tasks feel slower because the model pauses to assess complexity before responding. Fix: set thinkingDefault to "low" or "off" for agents handling primarily simple tasks. Or use /think off per session.
Does thinking mode work the same across all providers?
No. Each provider maps thinking levels differently. Anthropic supports all eight levels. DeepSeek maps xhigh and max to the same backend value. Ollama supports four levels and has a known regression (issue #73366) forcing thinking to false. Z.AI and Moonshot are binary (on/off only). OpenClaw normalizes the chat commands, but backend behavior varies.
Related Reading
- How to Reduce OpenClaw Costs — Thinking mode, model routing, and the other levers that move the bill
- Hidden OpenClaw Costs: Heartbeats and Token Overhead — Why heartbeats with thinking on burn money silently
- OpenClaw DeepSeek 503 Errors — Including the OpenRouter
reasoning_effortcompatibility bug - OpenClaw Model Comparison — Which models support which thinking levels reliably
- OpenClaw Best Practices — Multi-agent config patterns including thinking defaults
- OpenClaw Agent Hallucinating? 5 Fixes That Actually Work — When more thinking actually reduces hallucination, and when it doesn't