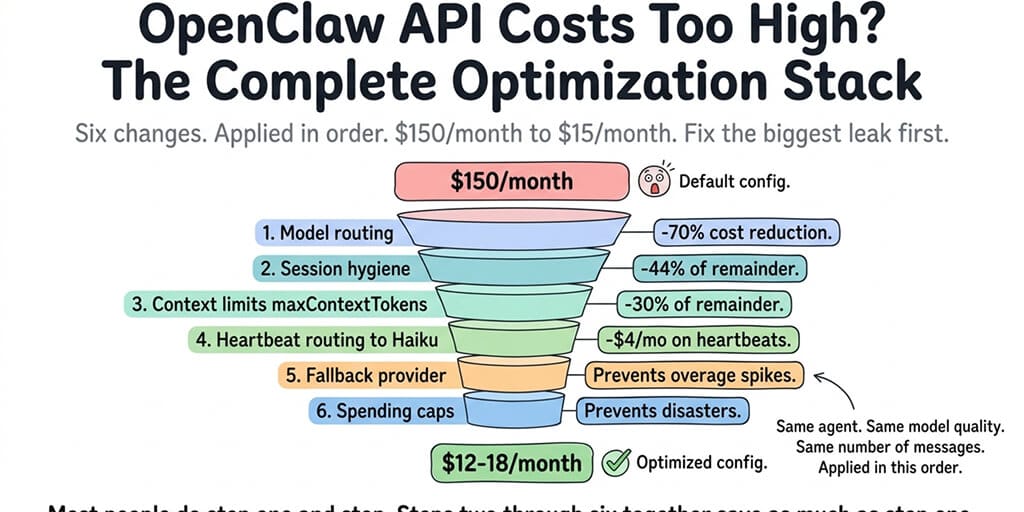
Six changes. Applied in order. $150/month to $15/month. Here's the full stack, ranked by impact, so you fix the biggest leak first.
A founder in our community messaged me last week with a screenshot of his Anthropic dashboard. $312 in API costs. In two weeks. For one agent.
He was running Claude Opus on every request, including 48 daily heartbeats. His conversations ran 60-80 messages without session resets. He had no spending caps. No model routing. No context limits. Default everything.
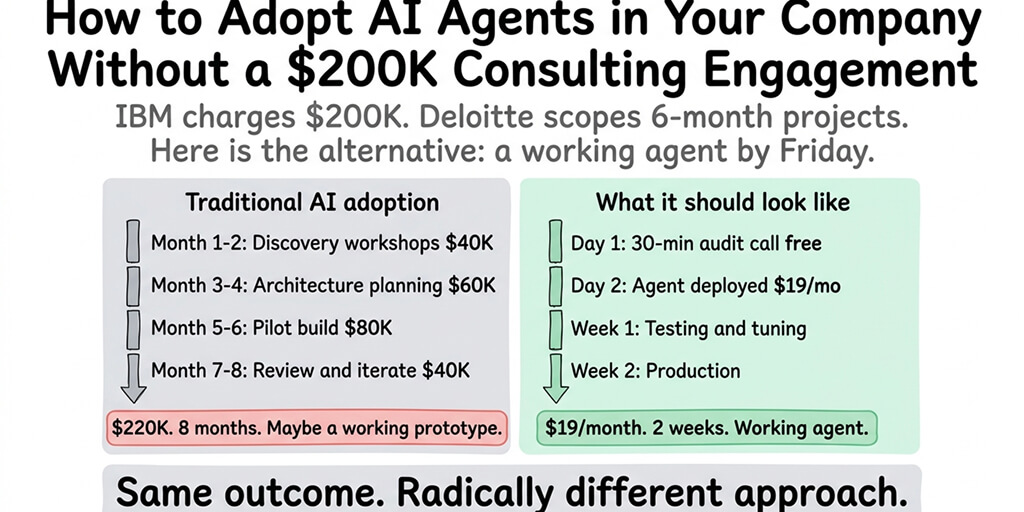
We walked through six changes over a 30-minute call. His projected monthly cost dropped to $18. Same agent. Same tasks. Same customer satisfaction. He just stopped paying for things he didn't need.
This is the complete OpenClaw API cost optimization stack, in priority order. Fix the biggest leak first. Each step builds on the previous one. Most people only do step one and leave 40-50% of savings on the table.
Why OpenClaw costs more than you expect
Here's the thing most people miss about OpenClaw API costs. You're not paying per message. You're paying per token. And a single OpenClaw message generates far more tokens than a single ChatGPT conversation.
When you message your agent, the API request includes your SOUL.md (system prompt), the full conversation history (every previous message and response), any tool call results, and your new message. By message 30, a single request can contain 25,000-35,000 input tokens.
Then the agent might call a tool. That's another API request. The tool returns results. The agent processes the results. That's another request. A single user message can trigger 3-10 API calls behind the scenes.
The viral "I Spent $178 on AI Agents in a Week" Medium post happened because of this multiplication effect. One message doesn't equal one API call. One message equals 3-10 API calls, each carrying the full conversation history as input.
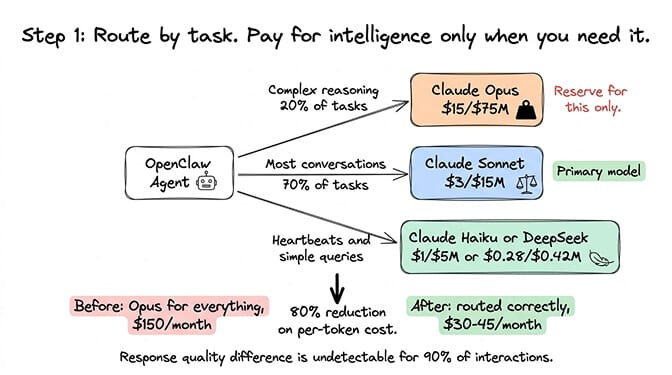
Step 1: Model routing (saves 70-80%)
This is the single highest-impact change. If you do nothing else, do this.
The problem: Most setups use one model for everything. If that model is Claude Opus ($15/$75 per million tokens), every heartbeat, every simple greeting, every "what time is it" query costs the same per token as a complex research task.
The fix: Set Claude Sonnet ($3/$15 per million tokens) as your primary model. Route heartbeats to Claude Haiku ($1/$5 per million tokens). Set DeepSeek ($0.28/$0.42 per million tokens) as your fallback.
The math: Switching from Opus to Sonnet for 90% of tasks cuts per-token costs by 80%. The response quality difference is undetectable for most interactions. Only complex multi-step reasoning tasks show a meaningful difference.
For the complete model-by-model comparison with per-task cost data, our model guide covers actual dollar figures across seven common agent tasks.
Step 2: Session hygiene (saves 40-50% of remaining cost)
This is where most people get it wrong. They do step one and think they're done. They're not.
The problem: Every message re-sends the entire conversation history as input tokens. Message 50 in a single session costs roughly 70x more in input tokens than message 1. Your per-message cost accelerates throughout every conversation.
The fix: Use /new every 20-25 messages to reset the conversation buffer. Use /btw for side questions that shouldn't inflate your main session. Your persistent memory (MEMORY.md) carries forward. The expensive conversation buffer resets.
The math: A 50-message session costs approximately $1.58 in input tokens on Sonnet. The same 50 messages split across five 10-message sessions costs approximately $0.38. That's a 76% reduction in input costs for identical content.
For the detailed breakdown of how session length multiplies your costs, our session optimization guide covers the token accumulation math.

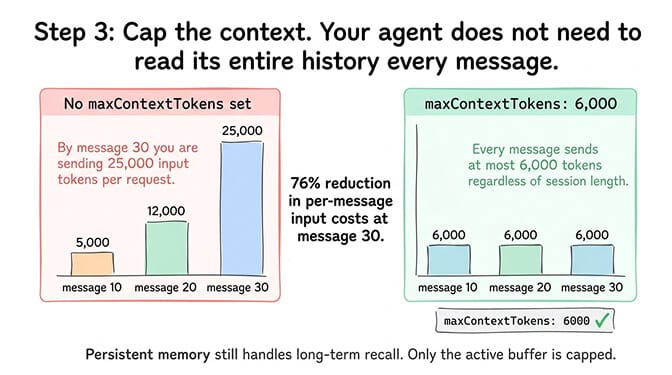
Step 3: Context window limits (saves 30-40% of input costs)
The problem: Without a cap, the conversation context grows until compaction kicks in. Compaction summarizes old messages but still leaves hundreds of tokens of summary. Without a hard limit, you're always sending more context than necessary.
The fix: Set maxContextTokens to 4,000-8,000 in your OpenClaw config. This forces the system to keep the context window lean. The agent still has access to persistent memory for long-term recall. The active conversation buffer stays bounded.
The math: A conversation without context limits might send 25,000 input tokens by message 30. With maxContextTokens set to 6,000, the same conversation sends at most 6,000 input tokens regardless of how long it runs. That's a 76% reduction in per-message input costs at message 30.
For the full explanation of how compaction and context limits interact, our memory guide covers the mechanics.
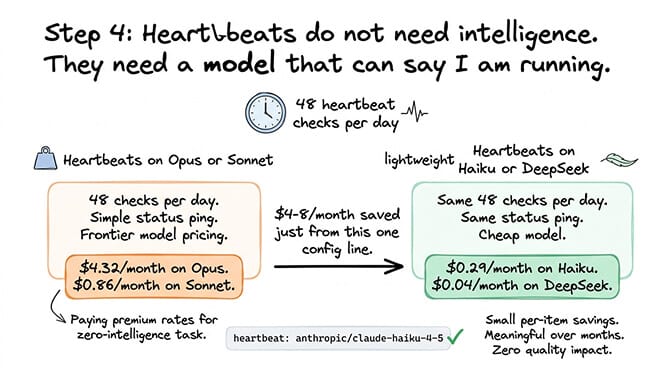
Step 4: Heartbeat model routing (saves $4-8/month)
The problem: OpenClaw sends approximately 48 heartbeat checks per day. These are simple "are you alive" status checks. If they run on your primary model (even Sonnet), they consume tokens unnecessarily.
The fix: Route heartbeats specifically to Haiku ($1/$5 per million tokens) or DeepSeek ($0.28/$0.42). Heartbeats don't need intelligence. They need a model that can say "I'm running."
The math: 48 heartbeats per day on Opus costs roughly $4.32/month. On Haiku, the same heartbeats cost roughly $0.29/month. Small per-item savings, but it adds up over months.
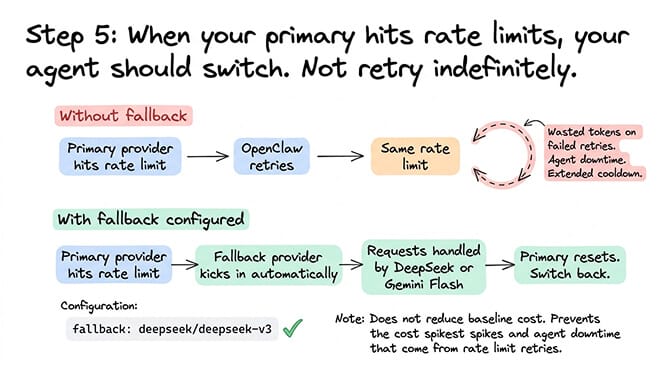
Step 5: Fallback provider (prevents overage, not a cost saver)
The problem: If your primary provider goes down or rate-limits you, OpenClaw retries. Retries during rate limits extend the cooldown and waste tokens. Without a fallback, your agent is stuck until the rate limit clears.
The fix: Configure a secondary provider (DeepSeek at $0.28/$0.42 or Gemini Flash with its free tier) as a fallback. When your primary hits a rate limit, the fallback handles requests until the limit resets. No failed retries. No wasted tokens. No agent downtime.
The math: This doesn't reduce your baseline cost. It prevents the cost spikes that come from rate limit retries and the agent downtime that comes from provider outages.
For the cheapest provider options including free tiers, our provider guide covers five options under $15/month.
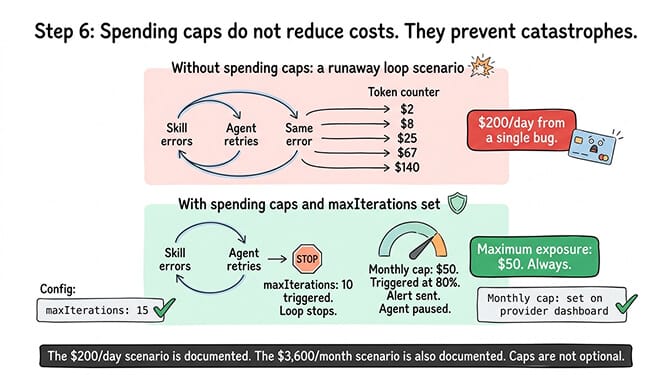
Step 6: Spending caps (prevents disasters, not a cost saver)
The problem: A runaway loop (skill errors, agent retries indefinitely) can burn through $50-100 in API credits in an hour. Without spending caps, the only limit is your credit card.
The fix: Set monthly spending caps on every provider dashboard at 2-3x your expected monthly usage. If you expect $20/month in API costs, cap at $50. Set maxIterations to 10-15 in your OpenClaw config to prevent infinite retry loops.
The math: This doesn't reduce normal costs. It prevents the catastrophic scenario where a bug turns your $20/month agent into a $200/day money pit.
If configuring model routing, session management, context limits, heartbeat routing, and spending caps sounds like a lot of optimization work, Better Claw includes pre-optimized cost settings as part of the platform. $19/month per agent, BYOK with 28+ providers. Model selection from a dashboard. Spending alerts built in. The optimization is done for you.
The complete before-and-after
Here's what happens when you apply all six steps to a moderate-usage agent (50 messages per day on Claude).
Before optimization (default config):
Opus on everything. No session resets. No context limits. No heartbeat routing. 50 messages per day in one continuous session.
Monthly API cost: approximately $140-180.
After optimization (all six steps):
Sonnet primary, Haiku heartbeats, DeepSeek fallback. /new every 20 messages. maxContextTokens set to 6,000. maxIterations at 12. Spending cap at $50.
Monthly API cost: approximately $12-18.
Savings: $125-165/month. Same agent. Same quality. Same customer satisfaction.
The order matters. Step 1 (model routing) captures the biggest savings. Step 2 (session hygiene) captures the next biggest chunk. Steps 3-6 capture the remaining margin and add safety nets. If you're only going to do two things, do steps 1 and 2.
Six changes. Applied in priority order. $150/month to $15/month. The agent doesn't change. The configuration does.
The one cost you can't optimize away
Here's the honest truth about OpenClaw API costs.
You can optimize the model, the session length, the context window, the heartbeats, the fallback, and the spending caps. You can get a moderate-usage agent down to $12-18/month in API costs.
You cannot optimize the fundamental cost of running an AI agent: the model needs tokens to think, and tokens cost money. If your agent handles 200 messages per day instead of 50, costs scale proportionally. If your tasks require Opus-level reasoning (complex multi-step research, nuanced creative work), Sonnet won't suffice and the per-token cost stays higher.
The goal isn't to spend $0 on API costs. The goal is to spend the minimum necessary for the quality your use case requires. For 80% of agent tasks (customer support, scheduling, Q&A, simple research), Sonnet with session hygiene is indistinguishable from Opus at 5x the price.
The managed vs self-hosted comparison covers how these cost decisions play out across different deployment approaches.
Know which tasks need expensive models. Route everything else to cheap ones. Reset sessions regularly. Cap your spending. That's the whole strategy.
If you want these optimizations pre-configured so you focus on what your agent does instead of what it costs, give Better Claw a try. $19/month per agent, BYOK with 28+ providers. Model routing from a dropdown. Session management built in. Spending alerts included. 60-second deploy. The cost optimization stack is part of the platform because we got tired of watching people spend $150/month on agents that should cost $18.
Frequently Asked Questions
Why are my OpenClaw API costs so high?
The three biggest cost drivers are: using an expensive model (Opus) for all tasks instead of routing by complexity, running long sessions without resets (message 50 costs 70x more in input tokens than message 1), and not setting context window limits (conversation history grows unbounded). Applying model routing and session hygiene alone typically reduces costs by 85-90%.
How much should OpenClaw cost per month?
A well-optimized moderate-usage agent (50 messages/day) costs $12-18/month in API fees on Claude Sonnet with model routing, session hygiene, and context limits. Add $12-29/month for hosting (VPS or managed platform). Total: $24-47/month. The viral "$178 in one week" story happened because of default settings (Opus, no routing, no session resets, no spending caps). Proper configuration prevents this entirely.
What's the cheapest model that works with OpenClaw?
DeepSeek at $0.28/$0.42 per million tokens is the cheapest cloud model with working tool calling. Gemini Flash has a free tier. Claude Haiku at $1/$5 is excellent for heartbeats and simple tasks. For primary agent conversations, Claude Sonnet at $3/$15 provides the best balance of quality and cost. Most optimized setups combine Sonnet (conversations) + Haiku (heartbeats) + DeepSeek (fallback).
How do I reduce OpenClaw costs without losing quality?
Six changes in priority order: switch primary model to Sonnet (80% cost reduction, minimal quality loss), use /new every 20-25 messages (44% input cost reduction), set maxContextTokens to 4K-8K (bounds per-message cost), route heartbeats to Haiku ($4+/month saved), configure a fallback provider (prevents rate limit waste), and set spending caps (prevents disasters). Steps 1 and 2 alone capture 85% of possible savings.
Does BetterClaw help reduce API costs?
BetterClaw ($19/month per agent, BYOK) includes model selection from a dashboard (easy routing), health monitoring with auto-pause (catches runaway loops before they drain credits), and spending alerts. The platform doesn't reduce your per-token API costs (those are set by your model provider), but it makes the optimization settings accessible without editing config files and catches anomalies that cause cost spikes.
Related Reading
- OpenClaw API Costs: What You'll Actually Pay — Base cost breakdown by model and provider
- OpenClaw Session Length Is Costing You Money — The hidden cost driver most people miss (Step 2 deep dive)
- OpenClaw Model Comparison — Per-task cost data across 4 LLMs (Step 1 deep dive)
- OpenClaw Model Routing Guide — Copy-paste config for Sonnet + Haiku + DeepSeek routing
- Cheapest OpenClaw AI Providers — Five providers under $15/month including free tiers