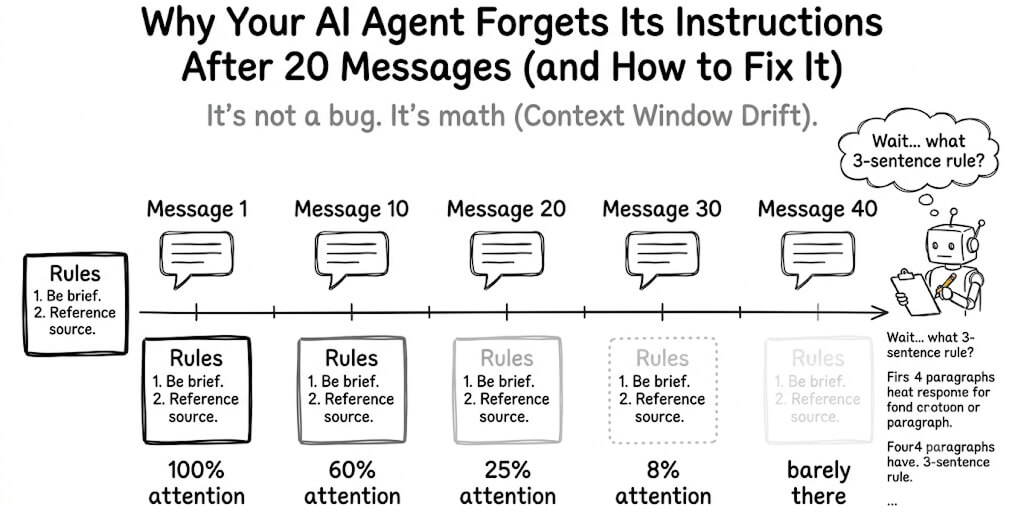
I spent a Saturday afternoon setting up Hermes Agent. Install script ran clean. No errors. I typed hermes into my terminal and got nothing. Literally nothing. "Command not found."
Three hours later, after bouncing between GitHub issues, Discord messages, and half a dozen blog posts that each covered one specific error, I had it running. The fix for my problem was one line: source ~/.bashrc.
One line. Three hours.
That's the thing about Hermes Agent not working. The errors themselves are usually simple. The pain is figuring out which error you're dealing with because the symptoms overlap and the documentation is scattered across multiple sources.
This is the consolidated guide I wish existed when I started. Every common Hermes error, organized by the layer where it actually breaks. Install first, then provider, then tools, then gateways. Debug in that order and you'll save hours.
Start here: hermes doctor --fix
Before digging into individual errors, run this:
hermes doctor --fix
According to Hermes's own documentation, this catches about 80% of common issues. It checks dependencies, validates your PATH, verifies API keys, confirms model availability, and auto-fixes what it can.
If hermes doctor --fix solves your problem, you're done. Close this tab.
If it doesn't, or if you can't even run that command, keep reading.

Layer 1: Install and PATH errors (the "command not found" problems)
"command not found" after install
The install script finishes without errors. You type hermes. Nothing.
The fix: Your shell configuration wasn't reloaded after installation. The Hermes binary lives in ~/.hermes/bin/ but your current terminal session doesn't know about it yet.
source ~/.bashrc
Or for Zsh users:
source ~/.zshrc
If that doesn't work, add the path manually:
export PATH="$HOME/.hermes/bin:$PATH"
echo 'export PATH="$HOME/.hermes/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc
Then verify with hermes --version. This is the single most common Hermes Agent error. It's not broken. Your shell just doesn't know where to find it.
Installation script times out or hangs
The curl | bash install hangs or the script downloads but fails mid-install.
The fix: Network restrictions are blocking GitHub access. This is common in corporate networks and certain regions. Two options:
Use a mirror proxy:
git config --global url."https://mirror.ghproxy.com/https://github.com".insteadOf "https://github.com"
Or download the install script manually, inspect it, and run it locally.
Python version conflict
Hermes requires Python 3.11 or higher. If you're running 3.9 or 3.10, the agent won't start or will throw import errors.
The good news: Hermes uses uv for isolated environment management, so this rarely becomes a blocking issue. But if it does, check your version:
python3 --version
If you're below 3.11, install the correct version alongside your existing one. Don't replace your system Python. Use pyenv or your distro's package manager to install 3.11+ as a secondary version.
Windows? Use WSL2.
Native Windows is not supported. As of June 2026, official Hermes install paths support Linux, macOS, and WSL2 only. Android has a Termux path, but Windows PowerShell or CMD will not work.
If you're on Windows, install WSL2 first, then run the Hermes install script inside the WSL2 terminal. This adds 10-15 minutes to your setup but it's the only supported path.
Layer 2: API key and provider errors
API key not recognized
You've set your key but Hermes returns authentication errors or empty responses.
Check three things:
Wrong key format. OpenAI keys start with sk-. Anthropic keys start with sk-ant-. If you copied the key wrong or have trailing whitespace, it won't work.
Expired or revoked key. Log into your provider dashboard and verify the key is still active.
Exhausted quota. A valid key with no remaining credits produces the same error as an invalid key. Check your billing page.
If the key checks out but Hermes still rejects it, the problem is usually how Hermes resolves credentials, not the key itself. Our Hermes auth error fixes walk through key drift, the wizard skipping the prompt, and four other causes.
Your key lives in ~/.hermes/.env. Open it and verify:
cat ~/.hermes/.env
After fixing the key, restart Hermes. It doesn't hot-reload env changes.
HTTP 400 errors from the model provider
This usually means you're sending a malformed request to the API. Common causes: requesting a model that doesn't exist on your plan, sending tool schemas in a format the provider doesn't support, or exceeding the provider's context length.
For specific Hermes 400 error debugging, we have a dedicated walkthrough that covers each provider's error codes. For Grok-specific connection issues — "user not found," the streaming 400, or silently dropped messages — see our Grok on Hermes setup and fixes guide.

Layer 3: Tool-calling failures (the subtle ones)
This is where most people waste the most time. The agent starts, connects to the model, but tools don't work. No error messages. Just... nothing happens.

Empty tool_calls every time
Your agent is supposed to call a Python function or use a tool, but the tool_calls array comes back empty. Every single time.
The most likely cause: apply_chat_template was called without tools=tools. The model never sees the tool schema, so it can't emit a structured call. It's not refusing to use tools. It literally doesn't know they exist.
This is a code-level fix. Make sure your template application includes the tool definitions. If you're using someone else's wrapper or tutorial code, check their apply_chat_template call specifically.
JSON parse errors in the agentic loop
The model returns malformed JSON in one tool call, and the error cascades across subsequent turns. Turn 1 has a broken bracket. Turn 2 tries to parse Turn 1's output. Turn 3 is complete nonsense.
The fix: Implement graceful error handling that catches JSON parse failures on each turn independently. Don't let one bad response corrupt the entire conversation history. Strip the malformed turn and retry.
Hard limit: Hermes 3 8B struggles with more than 3 parallel tool schemas. For complex multi-tool agents, use Hermes 3 70B or move to hosted inference.
Local models can't use web tools
Ollama is running. Your local model works fine for reasoning. But web browsing, web search, and other internet-dependent tools silently fail.
This is a known limitation. Web tools only get enabled when the configured web backend passes certain checks that local models often fail. Cloud models (Anthropic, OpenRouter) work fine because they satisfy those backend checks natively.
The workaround: keep a cloud model configured as your "web access" provider and use local models for offline reasoning tasks. You can switch between them per conversation.
Layer 4: Context and memory problems
Context overflow (the 2,048 token trap)
This is the sneakiest Hermes Agent error. Hermes 3 8B defaults to 2,048 tokens in Ollama, which fills up in 2-3 tool turns. Your agent works perfectly for the first interaction, then suddenly stops making sense or returns empty responses.

The fix is increasing the context window in your Ollama configuration:
ollama run hermes3 --ctx-size 8192
Or set it in the Modelfile. But be aware: larger context means more VRAM usage. On 8GB cards, you're limited. On 16GB+, 8192 tokens is comfortable for most agent workloads.
If you're running complex multi-tool chains, this single setting is probably why your agent "randomly" stops working after a few turns. If the failure shows up specifically as a cut-off reply (finish_reason='length'), see our deep dive on Hermes response truncation and its 5 causes.
Memory not persisting between sessions
You told your Hermes agent something yesterday. Today it has no idea what you're talking about.
This usually means memory checkpointing isn't configured or the working directory changed between sessions. Hermes stores memory files relative to where it starts. If it launched from ~/projects/ yesterday and ~/ today, it's looking at different memory stores.
Fix: Always start Hermes from the same directory, or configure an absolute path for memory storage. And enforce checkpoints: finish one sub-goal, summarize, then continue to the next stage.
This is one of the places where the gap between self-hosted agents and managed platforms becomes real. On BetterClaw, persistent memory uses hybrid vector plus keyword search with automatic context management. No token bloat, no lost memories between sessions, no directory dependency. If you're spending more time debugging memory persistence than actually using your agent, that's a signal worth paying attention to. Free plan available, $49/month for Pro. BYOK with zero markup.
Layer 5: Gateway and platform errors
Telegram or Discord gateway crashes
Your agent works fine in CLI mode. You connect it to Telegram or Discord and it immediately crashes or behaves erratically.
Root cause: The gateway process was spawning inside the hermes-agent source directory, which loads development files like AGENTS.md and other data that shouldn't be in the runtime context. This was adding garbage to the agent's context and inflating token usage by 2-3x.

The fix: Make sure your gateway starts from your home directory ($HOME), not from the Hermes source folder. This was patched in a recent update, so update first:
hermes update
If you're still seeing bloat after updating, check your working directory before launching the gateway. cd ~ first.
Token cost explosion on Telegram
You're watching your API costs and notice Telegram conversations are 2-3x more expensive than the same conversation in CLI mode.
Same root cause as above. Telegram's message format, combined with the gateway loading extra context, inflates every message. Update Hermes, ensure you're launching from $HOME, and monitor token usage for a few conversations to confirm the fix.
Tirith security module blocking everything
Hermes has a built-in security module called Tirith. It's supposed to catch risky commands and ask for approval before executing them. But some users report it blocking commands outright with no approval prompt.
For example, curl | sh patterns get hard-blocked. No option to proceed. The community has requested an interactive approval flow, but for now the workaround is splitting your commands:
curl https://example.com/script.sh -o script.sh
bash script.sh
Run the download and execution as separate steps, or use the terminal directly for commands Tirith won't approve through the gateway.
The cold start tax (and when to care about it)
One more thing that isn't technically an "error" but catches people off guard: Hermes 3 8B on Ollama takes 3-5 seconds to first token on a cold start. If you're used to cloud API response times (sub-second), this feels broken.
It's not broken. It's loading the model into VRAM. After the first response, subsequent queries are fast. If the cold start matters (for real-time applications, customer-facing agents, or high-frequency scheduling), either keep the model warm with periodic pings or use a cloud provider for latency-sensitive workflows.
For comparison, Hermes 3 8B outperforms Llama 3 8B Instruct by roughly 17 percentage points on tool-call success in local testing. The model is good. The infrastructure around it just needs tuning.
The honest question: is the debugging worth your time?
Every error on this page is fixable. None of them are deal-breakers. But they add up.
PATH configuration. Python version management. Ollama context tuning. Gateway working directories. Memory persistence debugging. Token cost monitoring. WSL2 setup on Windows.

If you're a developer who enjoys tinkering with infrastructure and wants full control over every layer of your agent stack, Hermes is genuinely good. Zero CVEs. 95,000+ GitHub stars in under two months. Strong self-learning capabilities. The framework itself is solid. We compared the two head to head in BetterClaw vs Hermes if you want the full breakdown.
But if you're looking at this list and thinking I just want my agent to work, that's a valid reaction. It's why managed platforms exist.
BetterClaw handles all five debug layers out of the box. No PATH issues because there's nothing to install. No API key files because OAuth handles it. No context overflow because smart context management is built in. No gateway configuration because 15+ chat platforms connect with one click. Free plan with 1 agent and 500 credits a month. $49/month for Pro. Deploy in 60 seconds. Your call.
The best tool isn't the one with the most GitHub stars. It's the one that gets out of your way and lets you build the thing you actually care about.
Frequently Asked Questions
What does "Hermes Agent not working" usually mean?
The most common cause is a PATH configuration issue after installation. Your shell doesn't know where the Hermes binary is located. Running source ~/.bashrc (or ~/.zshrc for Zsh) fixes this in most cases. If that doesn't work, run hermes doctor --fix which catches about 80% of common issues automatically.
How does Hermes Agent compare to OpenClaw for reliability?
Hermes has zero reported CVEs as of June 2026 and ships with container hardening and namespace isolation enabled by default. OpenClaw has a larger ecosystem (230K+ stars, 5,700+ skills on ClawHub) but has had multiple security advisories including CVE-2026-25253 (CVSS 8.8). For stability, Hermes is currently the more conservative choice. For integrations and skill variety, OpenClaw has a wider range. We cover the tradeoffs in detail in OpenClaw vs Hermes.
How do I fix Hermes Agent tool-calling failures?
First, verify apply_chat_template includes tools=tools so the model sees the tool schemas. Second, check that you're not exceeding 3 parallel tool schemas on Hermes 3 8B (use 70B for complex multi-tool setups). Third, implement JSON parse error handling per turn to prevent cascading failures. Run hermes tools list to confirm your tools are properly registered.
Is Hermes Agent free to use?
Hermes itself is free and open-source (MIT license). But running it requires your own hardware or a VPS ($5-50/month), plus API costs for your LLM provider. Total cost depends on usage but typically runs $20-100/month including infrastructure. BetterClaw offers a free plan at $0/month with BYOK, or $49/month for Pro with managed infrastructure and no setup required.
Can Hermes Agent run on Windows?
Not natively. As of June 2026, Hermes officially supports Linux, macOS, and WSL2 only. Windows users need to install WSL2 (Windows Subsystem for Linux) first, then run the Hermes install script inside the WSL2 terminal. This adds about 10-15 minutes to initial setup but works reliably once configured. Android users can use Termux.