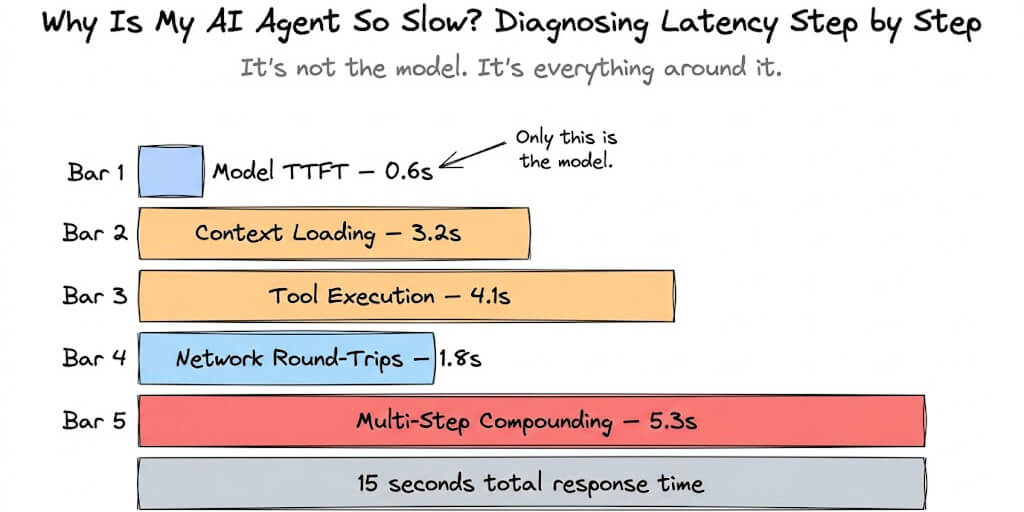
The agent starts generating. Mid-sentence, it stops. Response truncated (finish_reason='length') - the model hit max output tokens. The output is useless. The conversation is broken. Here are five causes from real GitHub issues and a copy-paste fix for each. If you want to paste your exact error string and see what it means first, try our response-truncated error decoder.
This is the same error whether you see it as finish_reason='length', "response truncated due to output length limit," or "model hit max output tokens" - Hermes and the underlying provider just phrase it differently. As of June 2026, this bug still persists in some configurations (see GitHub issue #26425, opened in May 2026, reporting truncation even after the earlier fixes were merged). This post is kept current as new reports land.
A Chinese user posted on X during Labor Day weekend: "My Hermes keeps throwing 'Response truncated due to output length limit.' I've given up on it. Let it starve."
That's the vibe. The error is maddening because it looks like a simple limit you should be able to increase. But max_tokens in config.yaml had no effect until recently. The compression system has a math bug that prevents it from firing. And the hardcoded output limits can drain your OpenRouter credits before the model generates a single token.
GitHub issue #7237 documents the core complaint: "This truncates the output mid-stream, breaks the conversation flow, and prevents users from receiving complete, usable answers."
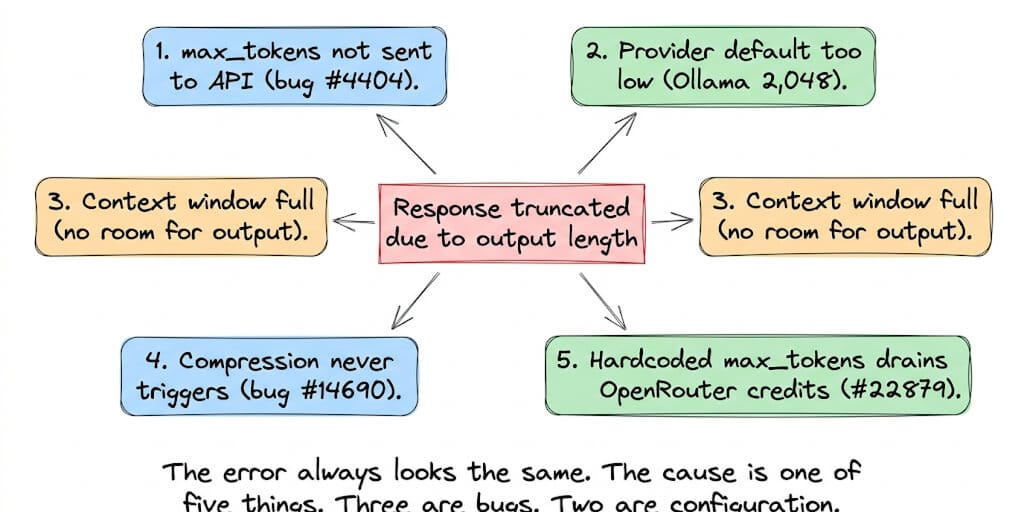
Here are five causes, ranked by how often they're the actual problem.
Cause 1: max_tokens from config.yaml never reaches the API (confirmed bug)
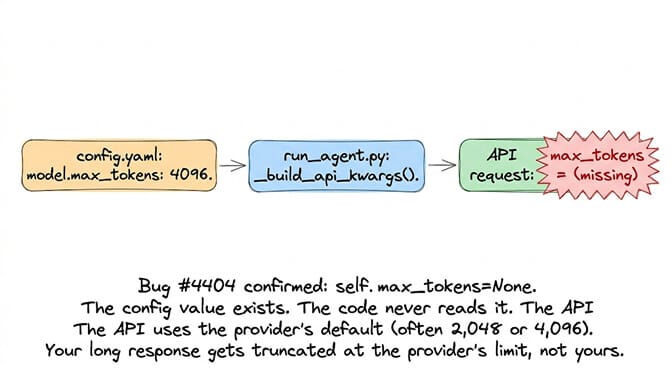
GitHub issue #4404: "model.max_tokens in config.yaml has no effect. The setting is never passed to AIAgent."
What happens: You set model.max_tokens: 8192 in your config. The agent ignores it. The API request goes out without max_tokens. The provider uses its default (often 2,048 or 4,096). Your response gets truncated at a limit you didn't set.
The bug confirmed: A developer patched the code to log what _build_api_kwargs() actually sends. Result: self.max_tokens=None. The config value exists but the code path from config.yaml → AIAgent → API request is broken.
The fix: A community PR exists on fix/model-max-tokens-config branch. If you're on v0.13.0+, check if the fix is merged. If not, the workaround: set HERMES_MAX_TOKENS=8192 as an environment variable in ~/.hermes/.env. The env var path works even when the config path doesn't.
The frustrating truth: The most common cause of truncation is a config value that looks correct but is silently ignored. Always verify with hermes chat -q "write a 500-word essay" --verbose and check the API request logs for the actual max_tokens value sent.
Cause 2: Provider default output limit is too low (especially Ollama)
What happens with Ollama: The default context window is 2,048 tokens. Not 8,192. Not the model's maximum. Two thousand and forty-eight. A 500-word response easily exceeds this.
The fix for Ollama: Create a Modelfile that sets the correct limits:
FROM hermes3:8b
PARAMETER num_ctx 8192
PARAMETER num_predict 1024
num_ctx is the total context window. num_predict is the max output tokens. Without these, Ollama defaults to 2,048 total, leaving almost no room for output after the system prompt and conversation history consume their share.
For the complete model configuration guide, our best practices post covers per-model output limit configuration.
Cause 3: Context window full (no room left for output)
Here's where most people get it wrong.
The context window is shared between input and output. If your model has a 64K context window and your conversation history + system prompt + tool definitions consume 60K tokens, only 4K tokens remain for the response. The model starts generating, hits the ceiling at 4K, and truncates.
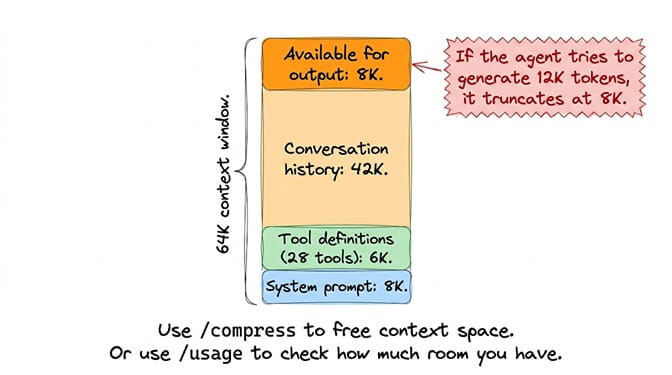
The fix: Run /usage in your chat to see current context consumption. If you're above 70%, run /compress to summarize the conversation history and free space. Or start a new session with hermes chat --new.
The official FAQ confirms: "Use /compress regularly during long sessions. It summarizes the conversation history and reduces token usage significantly while preserving context."
Cause 4: Compression never triggers (the math bug)
GitHub issue #14690 (P1, open): "Context auto-compression never triggers when context_length equals MINIMUM_CONTEXT_LENGTH (64000)."
The bug: The compression threshold calculation uses 64,000 as an absolute floor. If your model's context is 64K (common for local models with parallel slots), the threshold becomes 100% of the context window. Compression can't trigger because the API errors out before the threshold is reached.
The math: threshold_tokens = max(int(64000 * 0.7), 64000) = max(44800, 64000) = 64000. Threshold = 100%. Compression never fires. Context grows until the API rejects the request. Response gets truncated.
The fix: Set model.context_length in config.yaml to a value above 64,000 (e.g., 128000) so the threshold calculation produces a meaningful percentage. Or manually run /compress before the context fills.
If debugging config values that are silently ignored, Ollama defaults that nobody documents, context window math bugs, and compression thresholds that never trigger sounds like more framework internals than agent building, BetterClaw's smart context management handles all of this at the platform level. No max_tokens configuration. No compression commands. No context math. The platform manages output limits and context automatically. Free tier with 1 agent and BYOK. $19/month per agent for Pro.
Cause 5: Hardcoded max_tokens reserves too many credits on OpenRouter
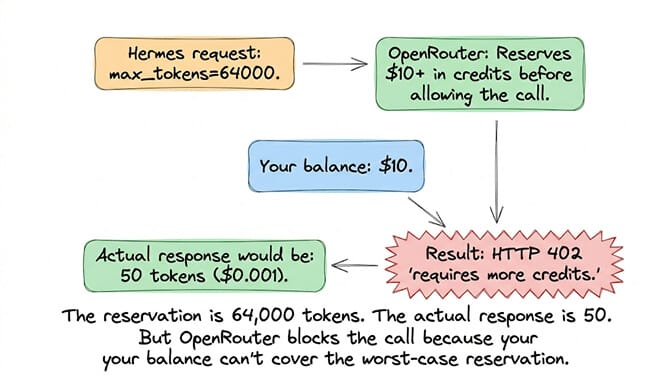
GitHub issue #22879: "Hermes hardcodes max_tokens to each model's maximum output (e.g., 64000 for Claude Sonnet/Haiku 4.5). OpenRouter reserves the full max_tokens as collateral before allowing the call."
What happens: You have $10 in OpenRouter credits. Hermes requests max_tokens=64000. OpenRouter reserves $10+ worth of credits upfront. Your balance can't cover the reservation. OpenRouter returns HTTP 402 ("requires more credits"). The actual response would be 50-500 tokens. The reservation is 64,000. (If the reservation pushes you into a 400 instead, our Hermes Agent error 400 guide covers the credit and payload causes too.)
The fix: This is tagged as a feature request (#22879). Until it's resolved, add more credits to your OpenRouter account (enough to cover the worst-case reservation), or switch to a direct provider (Anthropic direct doesn't pre-reserve credits).
"Response Remained Truncated After 3 Continuation Attempts"
If you see error: response remained truncated after 3 continuation attempts, this is the follow-up error, not a separate problem. When Hermes hits the output limit mid-stream, it automatically retries the generation up to three times, asking the model to continue where it left off. If every attempt hits the same ceiling, Hermes gives up and surfaces this message.
In other words: the underlying cause is identical to the five above - the model keeps running out of room. The retries fail because they inherit the same broken max_tokens value (Cause 1) or the same too-low provider default (Cause 2). Each continuation attempt adds the partial output back into the context, so the window fills even faster, which can also trigger Cause 3.
The fix: Don't chase the "3 continuation attempts" message itself - fix the root limit. Set HERMES_MAX_TOKENS=8192 in ~/.hermes/.env (Cause 1), raise your Ollama num_predict (Cause 2), or run /compress to free context (Cause 3). Once the per-call output ceiling is correct, the retries succeed on the first pass and the message disappears.
What Response truncated (finish_reason='length') and its variants mean
Hermes, your model, and your provider all describe this failure differently. If you searched any of the strings below, you're in the right place - each maps to one of the five causes above:
response truncated (finish_reason='length')- the raw provider signal. The model hit itsmax_tokensceiling. Start with Cause 1 (config bug) and Cause 2 (provider default).response truncated due to output length limit- Hermes's wrapper for the samefinish_reason='length'. Same fixes.Hermes model hit max output tokens- a plain-language variant. Cause 1 or Cause 2.max_tokens=none truncation requested-max_tokensnever reached the API request (it'sNone). This is Cause 1 (#4404) exactly. SetHERMES_MAX_TOKENSas an env var.response remained truncated after 3 continuation attempts- the retry-exhausted follow-up error covered in the section above. Fix the root limit (Cause 1/2/3).
All five are the same underlying condition: the model ran out of output room. The fix depends on why it ran out, not on which string you saw.
The diagnostic checklist
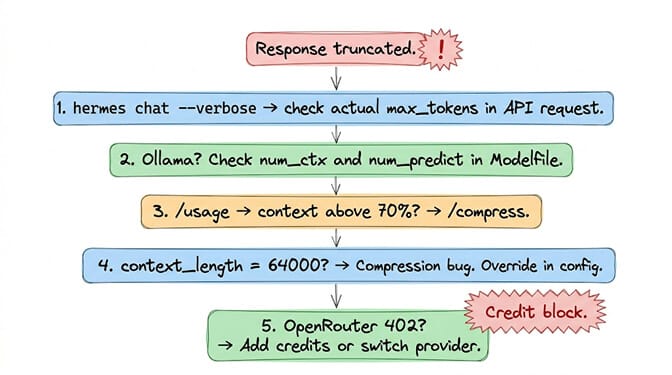
Step 1: Check the API request for the actual max_tokens value:
hermes chat -q "write a 500-word essay" --verbose
Step 2: Run /usage in an active chat to see how much context is consumed. If above 70%, run /compress:
/usage
Step 3: Check your Ollama Modelfile. Is num_ctx set? Is num_predict set? Defaults are too low.
Step 4: Check model.context_length in config.yaml. Is it 64,000? If so, the compression bug (#14690) applies.
The truncation error is Hermes's way of saying "the model ran out of room." But "ran out of room" has five different causes, and the error message doesn't tell you which one. Config values that are ignored. Provider defaults that are undocumented. Context that fills silently. Compression that can't fire. Credit reservations that block the call. Same error. Five different problems. If truncation turns out to be a symptom of a deeper config issue, our guide to Hermes Agent not working covers every layer where the agent can break.
If you want an agent where context management is handled automatically and you never see "response truncated," give BetterClaw a try. Free tier with 1 agent and BYOK. $19/month per agent for Pro. Smart context management. No truncation. No compression commands. The agent speaks. The response completes.
Frequently Asked Questions
What does "Response truncated due to output length limit" mean in Hermes?
It means the model's response was cut off before completion. The five causes: max_tokens config not being sent to the API (bug #4404), provider default output limit too low (Ollama defaults to 2,048), context window full with no room for output, compression math bug preventing auto-compression (#14690), or OpenRouter credit reservation blocking the call (#22879).
What does finish_reason 'length' mean in Hermes?
finish_reason='length' means the model stopped because it hit its maximum output token limit, not because it finished its answer. The response is cut off mid-stream. In Hermes this surfaces as "response truncated due to output length limit." The five causes: max_tokens config not reaching the API (bug #4404), a too-low provider default (Ollama defaults to 2,048), a full context window, the compression math bug (#14690), or an OpenRouter credit reservation blocking the call (#22879). Fix the underlying limit rather than the message.
Why does Hermes response remain truncated after 3 continuation attempts?
When Hermes hits the output limit, it automatically retries the generation up to three times to "continue" the response. If every retry hits the same ceiling, it surfaces response remained truncated after 3 continuation attempts. The retries fail because they inherit the same broken max_tokens value (bug #4404) or the same low provider default, and each attempt adds partial output back into the context, filling the window faster. Fix the root limit - set HERMES_MAX_TOKENS=8192 in ~/.hermes/.env, raise Ollama's num_predict, or run /compress - and the retries succeed on the first pass.
How do I set max_tokens to none in Hermes?
You usually don't want max_tokens=none - that's the cause of the problem, not the fix. When max_tokens is None, the request goes out without an explicit output ceiling, so the provider applies its own default (often 2,048 or 4,096) and truncates the response. This happens because of bug #4404, where model.max_tokens in config.yaml is silently dropped and self.max_tokens ends up None. Set an explicit value instead: HERMES_MAX_TOKENS=8192 in ~/.hermes/.env, which reaches the API even when the config path is broken. On OpenRouter, avoid an over-large value (Hermes hardcoding 64,000 triggers credit-reservation failures, #22879).
How do I increase the output length in Hermes Agent?
Set HERMES_MAX_TOKENS=8192 in ~/.hermes/.env (the config.yaml path may not work due to bug #4404). For Ollama, create a Modelfile with PARAMETER num_ctx 8192 and PARAMETER num_predict 1024. For cloud providers, verify the max_tokens value in verbose logs. Use /compress regularly to free context space during long sessions.
Why does /compress not work in Hermes?
If your model's context_length equals 64,000 (the MINIMUM_CONTEXT_LENGTH constant), auto-compression never triggers due to a math bug (#14690, P1, open). The threshold calculation produces 100% of the context window, which is unreachable. Fix: set model.context_length in config.yaml to a value above 64,000 (e.g., 128000) so the threshold calculation works correctly.
Why does Hermes use all my OpenRouter credits on one message?
Hermes hardcodes max_tokens to each model's maximum output (64,000 for Claude models). OpenRouter pre-reserves the full amount as credit collateral before allowing the call. Your $10 balance can't cover a 64K-token reservation even though the actual response would be 50 tokens. Fix: add more credits, or switch to a direct provider that doesn't pre-reserve. Issue #22879 tracks making this configurable.
Does BetterClaw have the same truncation problems?
No. BetterClaw's smart context management handles output limits, context compression, and provider-specific configurations at the platform level. There's no max_tokens to configure, no compression threshold bug, and no credit reservation mismatch. The platform manages the context window so responses complete without truncation. Free tier with 1 agent and BYOK. $19/month per agent for Pro.