

We had an agent managing email triage. Read incoming emails, classify urgency, look up the sender in HubSpot, draft a response, and flag anything it couldn't handle.
On Claude Sonnet, it worked. Consistently. For weeks. The classification was accurate, the drafted responses matched our tone guide, and the agent followed the rules we set. "Never promise a refund without human approval." It followed that rule every single time.
Then we tested the same workflow on GPT-4o. Faster responses. Slightly cheaper per token. But on day three, the agent promised a refund to a customer without flagging it. The system prompt said not to. The model just... didn't follow it.
Not because GPT-4o is a bad model. It's excellent. But Claude vs GPT-4o isn't a question about which model is smarter. It's about which model does what your agent tells it to do, consistently, under pressure, when the context window is full and the instructions are buried 80,000 tokens deep.
Here's what we've learned after running both in production.
Instruction following is the only benchmark that matters for agents
Benchmark scores are useful for comparing models in general. For agents specifically, they're almost irrelevant.
An agent doesn't need to write the best poem or solve the hardest math problem. It needs to follow a system prompt reliably. It needs to call the right tool with the right arguments. It needs to know when to stop, when to ask for help, and when to proceed.
Independent testing backs this up. Atlas Whoff ran Claude Sonnet and GPT-4o on a 5-agent business system for 30 days. The results were striking.
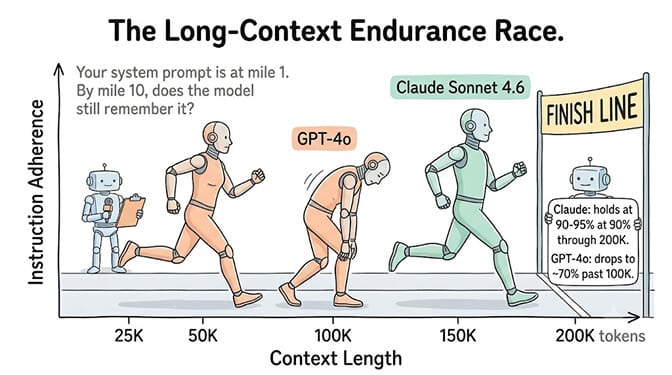
Claude maintained instruction following at 150,000+ tokens. GPT-4o degraded significantly past 100,000 tokens. For agents that accumulate context over long conversations (which is most agents in production), this difference is the difference between reliable and unreliable.
Claude's tool call hallucination rate was 3%. GPT-4o's was 7%. That might sound close. But when your agent is making 200 tool calls a day, the difference between 6 hallucinated calls and 14 hallucinated calls is real. Each hallucinated tool call is a failed action, a wrong API call, or a confused user.
In blind human evaluations conducted by independent research groups in Q1 2026, Claude-generated content was preferred 47% of the time versus 29% for GPT-5.4 and 24% for Gemini. The gap was largest in instruction following, tone consistency, and structural coherence. (For how the newest flagships stack up, see our GPT-5.5 vs Claude vs DeepSeek breakdown.)
Where Claude wins for agent workloads
Claude's strengths map directly to what makes agents work well in production.
Long-context reliability
Claude Sonnet 4.6 has a 200K token context window (1M for Opus). More importantly, it maintains attention quality across the full window. GPT-4o's 128K window is smaller, and independent tests show "lost-in-the-middle" effects where the model drops relevant context from earlier in the prompt as it approaches capacity.
For agents that handle multi-turn conversations, accumulate tool results, and carry system instructions... this matters enormously. Your system prompt is at the beginning. Your latest user message is at the end. Everything in between is context the model needs to attend to. If the model starts ignoring the system prompt once context exceeds 100K tokens, your agent stops following its own rules. (This is the same dynamic we covered in why your agent forgets.)
Coding and technical tasks
In a 30-day independent test by Ryz Labs, Claude reached approximately 95% functional accuracy on coding tasks compared to about 85% for ChatGPT. Claude Sonnet 4.6 scored 79.6% on SWE-bench Verified. GitHub Copilot, Cursor, and Claude Code are all either built on Claude or heavily benchmark against it for coding tasks.
For agents that write code, modify configurations, generate SQL queries, or interact with APIs programmatically, Claude's coding accuracy translates to fewer broken tool calls and less manual cleanup.
Constitutional discipline
Claude is built with Constitutional AI, which means it's trained to follow rules even when a user tries to get it to break them. For agents, this translates to better adherence to system prompts, safety constraints, and operational boundaries.
When you tell Claude "never share pricing information without checking the latest database first," it follows that instruction more consistently than GPT-4o does. That's not a subjective opinion. It's what production deployment data shows.

Where GPT-4o wins for agent workloads
GPT-4o isn't just a viable alternative. In several areas, it's the better choice.
Multimodal in a single call
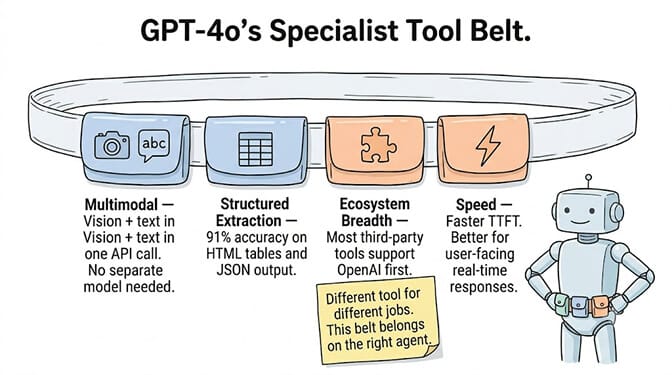
If your agent needs to process images alongside text (reading screenshots, analyzing product photos, reviewing UI mockups, processing mixed-media documents), GPT-4o handles all of this in one API call. No separate vision model needed.
Claude handles images too, but GPT-4o's native multimodal architecture was designed for this from the ground up. For agents that handle visual inputs as part of their workflow, GPT-4o has a genuine edge.
Structured data extraction
GPT-4o produced 91% accurate structured data from HTML tables in production testing. When your agent's job is parsing invoices, extracting data from web pages, or converting unstructured text into JSON... GPT-4o's structured output handling is strong.
Ecosystem breadth
GPT-4o has the largest integration surface of any model. Most third-party tools, platforms, and frameworks have native OpenAI support. Some have added Anthropic support, but OpenAI was usually first. When you're building agents on niche platforms or using specialized tools, GPT-4o is more likely to be supported out of the box.
Speed
GPT models are consistently faster in time-to-first-token and generation throughput. For user-facing agents where perceived responsiveness matters, GPT-4o's speed advantage is noticeable. The difference is less important for background agents processing emails or data pipelines.
The pricing math for agent workloads
Agent workloads are token-intensive. Your agent sends the system prompt, conversation history, tool definitions, and previous tool results on every single request. This adds up fast.
Claude Sonnet 4.6: $3.00 per million input tokens, $15.00 per million output tokens. But Claude's prompt caching can reduce repeated context costs dramatically. In the Atlas Whoff 30-day test, prompt caching reduced orchestration costs from $50/day to $6/day for 200K-token contexts.
GPT-4o: Approximately $2.50 per million input tokens, $10.00 per million output tokens. Cheaper per token, especially on output.
GPT-5.4: $2.50 per million input tokens, $15-20 per million output tokens. Comparable to Claude Sonnet on output.
At first glance, GPT-4o is cheaper. But for long-context agent workloads where the same system prompt and tool definitions are sent with every request, Claude's prompt caching changes the economics significantly. If 80% of your input tokens are repeated context (which is typical for agents), caching cuts your effective input cost substantially.
The cheapest model isn't always the cheapest agent. Factor in context caching, hallucination cleanup costs, and the time spent debugging tool call failures when comparing total cost of ownership. (For the per-token breakdown across providers, see our OpenAI vs Anthropic pricing comparison.)

This is one of the reasons BetterClaw supports 28+ model providers with BYOK and zero inference markup. You bring your own API keys, pay providers directly, and switch models without rebuilding your agent. Run Claude for your reasoning-heavy classification agent and GPT-4o for your multimodal document processing agent. Same platform. Different models. Optimized for each task. Free plan with 1 agent and 500 credits a month. $49/month on Pro.
The smart answer: use both
The developers getting the best results in 2026 aren't picking one model. They're routing between models strategically.
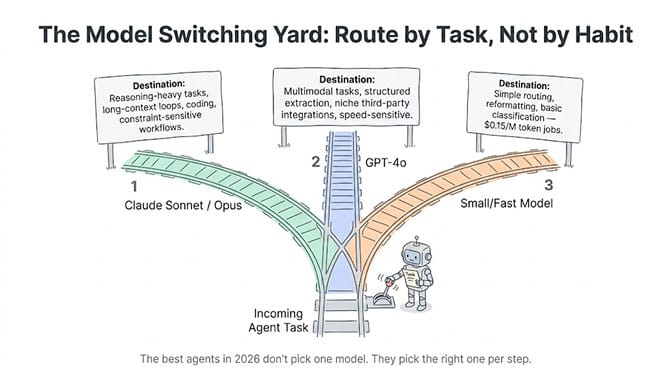
Use Claude for: reasoning-heavy steps. Complex classification. Long-context agent loops where instructions must hold. Coding tasks. Any step where following constraints precisely matters more than speed.
Use GPT-4o for: multimodal tasks (vision plus text). Structured data extraction. Simple classification where speed matters. Tasks with niche third-party integrations that only support OpenAI.
Use smaller models for: basic routing and classification. Simple reformatting. Any step where a $0.15/million-token model performs the same as a $3.00 model.
Model routing isn't complex to implement. Most AI agent platforms let you assign different models to different agents or tasks. On BetterClaw, you can run one agent on Claude Opus and another on GPT-4o, each optimized for their specific workflow. The platform handles provider switching, context management, and token cost tracking per agent.
The model is only part of the equation
Here's what a year of building agents has taught us: the model matters less than most people think. A great model with poor context management, no persistent memory, and no trust controls will still produce a mediocre agent.
The reverse is also true. A well-architected agent with smart context management, proper tool definitions, and clear trust levels will perform well on either Claude or GPT-4o.
The model is the brain. But the brain needs a body. Memory that persists across conversations. Trust levels that prevent unauthorized actions. Context management that prevents token bloat. Security that protects credentials and API keys.
If you're spending more time choosing between Claude and GPT-4o than building the actual agent, you might be solving the wrong problem. (If you do want a structured way to decide, here's our framework for choosing the right LLM for each task.)
Give BetterClaw a look. Both models supported. Free plan with 1 agent and 500 credits a month. $49/month for Pro for Pro. Deploy in 60 seconds. Switch models with a dropdown. We handle everything except the part that makes your agent uniquely useful.
Frequently Asked Questions
What is the difference between Claude and GPT-4o for AI agents?
Claude excels at instruction following, long-context reliability (maintains quality at 150K+ tokens where GPT-4o degrades past 100K), and coding accuracy (~95% vs ~85%). GPT-4o excels at multimodal tasks (native vision plus text), structured data extraction (91% accuracy), speed (faster time-to-first-token), and ecosystem breadth (more third-party integrations). For agents, Claude is generally better for reasoning-heavy, rule-following tasks. GPT-4o is better for multimodal and speed-sensitive tasks.
How does Claude compare to GPT-4o on tool calling accuracy?
In 30-day production testing, Claude showed a 3% tool call hallucination rate versus GPT-4o's 7%. This means Claude is roughly twice as reliable when calling external tools, APIs, and functions. For agents making hundreds of tool calls daily, this difference translates to significantly fewer failed actions and less manual intervention.
Which model is cheaper for AI agent workloads?
GPT-4o is cheaper per token ($2.50/$10 per million tokens vs Claude Sonnet 4.6 at $3/$15). However, Claude's prompt caching can reduce effective costs by 80-90% for repeated context, which is typical in agent workloads. In a 30-day test, prompt caching reduced Claude's daily orchestration cost from $50 to $6 for 200K-token contexts. Total cost depends on your workload's caching potential.
Should I use Claude or GPT-4o for my AI agent?
Use Claude when instruction following, constraint adherence, and long-context reliability are priorities (customer support agents, compliance-sensitive workflows, coding agents). Use GPT-4o when multimodal capability, structured extraction, or speed are priorities (document processing agents, image-aware agents, user-facing chatbots). The best approach in 2026 is model routing: use both strategically, assigning each to the tasks where it performs best.
Can I switch between Claude and GPT-4o without rebuilding my agent?
Yes, if your agent is built on a platform that supports multiple providers. On BetterClaw, switching models is a dropdown change. No code changes, no redeployment, no infrastructure work. BetterClaw supports 28+ model providers including OpenAI, Anthropic, Google Gemini, Mistral, DeepSeek, and more. BYOK means you pay providers directly with zero markup.



