OpenClaw is usually slow because of context bloat — as your conversation grows, every message sends more input tokens to the API, increasing processing time. By message 40, a session can contain 25,000+ tokens. Type /new directly in your agent chat to reset the conversation buffer and response times drop back to message-1 speeds instantly. This is the cause 80% of the time. The other four causes are below, ranked by likelihood.
Is your OpenClaw slow from the very first message? Skip Cause 1 (context bloat) — that only explains progressive slowdown. Jump straight to Cause 2 (slow model tier), Cause 3 (rate limiting), Cause 4 (Docker / Ollama overhead on the local machine), or Cause 5 (a skill stuck in a retry loop).
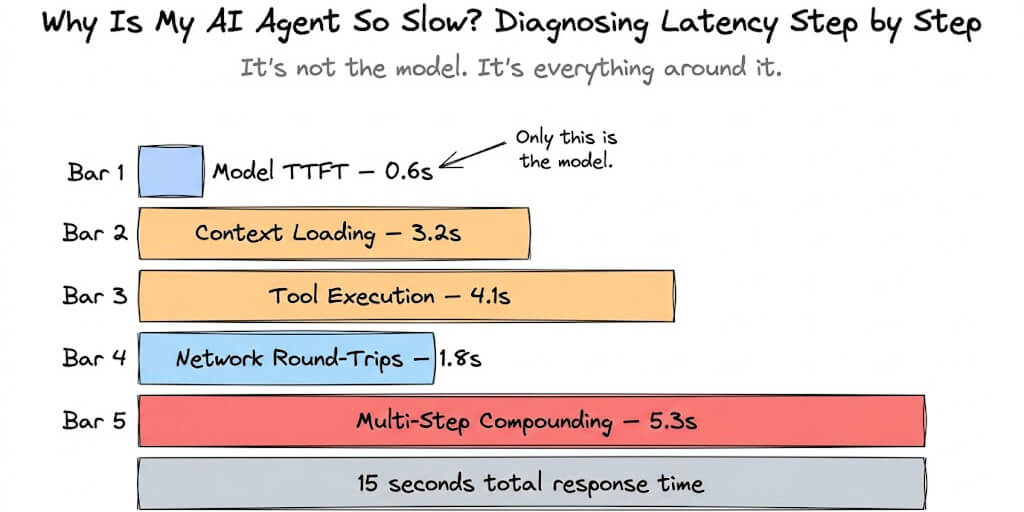
My agent took 14 seconds to respond to "What time is it?"
Not a complex research task. Not a multi-tool workflow. A question that should take under two seconds. Fourteen seconds. I watched the spinner and thought, something is very wrong here.
Turns out nothing was wrong with the agent's logic. The problem was the context. By message 40 in the session, every request was sending 28,000 input tokens to the API. The model was processing my entire conversation history, SOUL.md, tool results, and memory injections just to tell me the time. This is the most common reason OpenClaw feels slow — and it has nothing to do with your internet connection, your server, or the model itself.
Cause 1: Context bloat (this is almost always it)
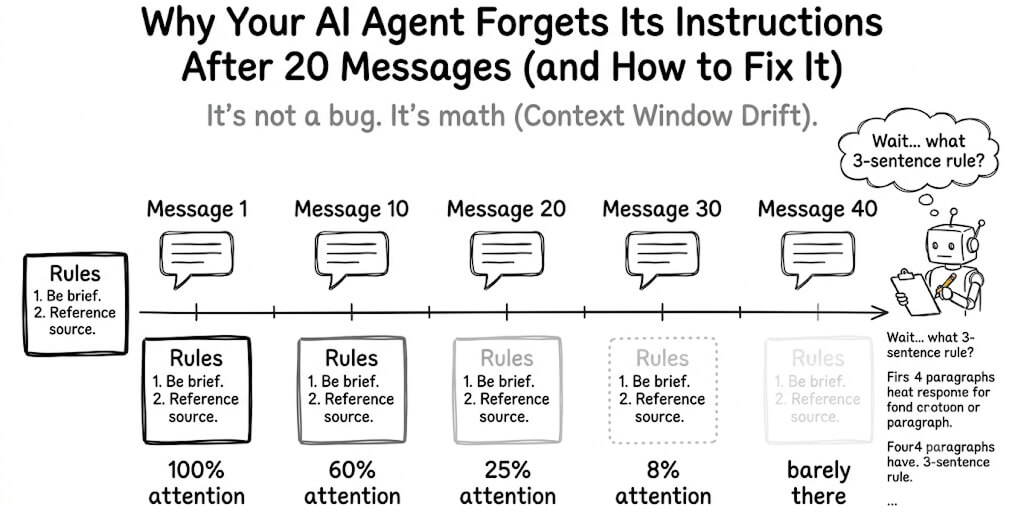
Every message you send to your OpenClaw agent includes the full conversation history as input tokens. Message 1 sends maybe 2,000 tokens. Message 20 sends 12,000. Message 40 sends 25,000-30,000. Each additional message makes every subsequent request larger and slower.
The model doesn't get faster at reading. It processes input tokens sequentially. More input tokens means more processing time before it can start generating a response. A 28,000-token input takes noticeably longer than a 3,000-token input, even on the fastest models.
The fix
Use /new every 20-25 messages to reset the conversation buffer (type /new directly in your agent chat — it's a chat command, not a config flag, and it leaves your persistent memory in MEMORY.md and memory-wiki untouched). Only the conversation buffer resets. Response time drops back to message-1 speeds immediately.
Also cap the context window in your config so it can't grow this large in the first place:
agent:
maxContextTokens: 6000 # adjust 4000-8000; lower = faster but more aggressive compaction
This forces compaction earlier and keeps per-request input volume bounded.
For the detailed breakdown of how session length drives both cost and latency, our OpenClaw API cost and latency optimization guide covers the token accumulation math.
If your agent was fast when you started the session and got progressively slower, context bloat is the cause. Use /new. It takes two seconds and fixes the problem immediately.

Cause 2: You're on a model that's too slow for agent tasks
Not all models respond at the same speed. The current heavyweights (Claude Opus 4.7, GPT-5.5, Gemini 3.1 Pro) take significantly longer per response than their lighter siblings (Claude Haiku 4.5, GPT-5 Mini, Gemini 3 Flash). Sonnet 4.6 sits in the middle. Opus 4.7 now has a "fast mode" that closes some of the gap, but it's still slower than Haiku for routine tasks.
What "normal" response time looks like
Use these as rough baselines so you know whether you have a real problem:
| Tier | Typical models | Expected response time |
|---|---|---|
| Fast | Claude Haiku 4.5, GPT-5 Mini, Gemini 3 Flash, DeepSeek V4-Flash | 1-3 seconds |
| Mid | Claude Sonnet 4.6, GPT-5.3 Instant, Gemini 3 Flash thinking | 2-5 seconds |
| Heavyweight | Claude Opus 4.7, GPT-5.5, Gemini 3.1 Pro, DeepSeek V4-Pro | 4-10 seconds |
If your 14-second response is on Haiku, something is wrong. If it's on Opus 4.7 with extended thinking enabled, that's closer to expected behavior.
The fix
Switch your primary model to a faster tier. For most agent tasks (customer support, scheduling, Q&A, simple research), Haiku 4.5 or Flash provides the same quality at 2-3x the response speed. Keep the heavyweight model for the complex tasks that actually need it.
Model routing helps here. Route simple tasks to a fast model and complex tasks to a capable one. For the cheapest and fastest provider options, our provider guide covers speed alongside cost.

Cause 3: Provider rate limiting is throttling you
If you're hitting your model provider's rate limit (requests per minute or tokens per minute), the provider adds artificial delays to your responses. Instead of a 2-second response, you get a 10-second response because the provider is queuing your request.
How to identify it
Check your provider's usage dashboard for rate-limit metrics:
- Anthropic console → Settings → Usage → Rate Limits. If your RPM or ITPM column is consistently at 100% during slow periods, you're throttled.
- OpenAI platform → Settings → Limits. Watch the "current usage" gauge against your tier's per-minute caps.
- Google AI Studio → API key → quota. The "Requests per minute" graph should show clear ceilings if you're being throttled.
The response time spikes will correlate with high-usage periods.
The fix
Configure a fallback provider. When your primary hits rate limits, the fallback handles requests at full speed. DeepSeek V4-Flash or Gemini 3 Flash as a fallback means rate limits on one provider don't slow down your agent. For the rate limit troubleshooting guide, the rate-limit post covers the three types of rate limits and how to identify which one you're hitting.

Cause 4: Docker or Ollama overhead on the local machine
If you're running OpenClaw locally with Docker-sandboxed execution or using Ollama for local models, the host machine's resources matter.
Docker overhead
Every sandboxed skill execution spins up a container. On machines with limited RAM (4GB or less), container startup adds 2-5 seconds per tool call. If your agent calls three tools per response, that's 6-15 seconds of container overhead alone.
Ollama overhead
Local model inference speed depends entirely on your hardware. On a CPU-only 8GB machine, a 7B model realistically runs at 1-5 tokens per second — slow enough that the agent feels frozen. With an 8GB consumer GPU you can get into the 30+ tokens-per-second range. A 32B model needs significantly more memory and on most laptops won't run at usable speed at all. For the local model hardware requirements, the hardware guide covers the specific RAM and GPU requirements per model size.
The fix for Docker
If you're on a low-memory machine, disable sandboxed execution for trusted skills (understanding the security trade-off) or upgrade to a machine with 8GB+ RAM.
The fix for Ollama
Use a smaller model (qwen3:8b instead of a 32B variant) or switch to a cloud API provider. The API call adds network latency (200-500ms) but the model processes far faster on cloud GPUs than on most local hardware.

Cause 5: A skill is stuck in a retry loop
Sometimes the slowness isn't the model. It's a skill that's failing silently, retrying, failing again, and adding 5-10 seconds of loop time before the agent gives up and responds.
How to identify it
Check the gateway logs for repeated tool call errors. If you see the same skill being called and failing multiple times in sequence, the loop is adding latency to every response that triggers that skill.
The fix
Cap the retry count in your agent config:
agent:
maxIterations: 12 # 10-15 is the typical sweet spot
This caps retry attempts so a broken skill can't loop indefinitely. Identify the failing skill, check its configuration, and either fix or remove it. For the complete guide to diagnosing agent loops, the loop troubleshooting post covers the specific patterns.
If diagnosing context bloat, tuning model routing, managing rate limits, and monitoring skill loops feels like more performance engineering than you signed up for, BetterClaw includes smart context management that prevents the token bloat causing most slowness. $49/month for Pro, free tier with 1 agent and BYOK. The context management is handled automatically. Your agent stays fast because the context stays lean.

The diagnostic checklist (10 minutes)
When your OpenClaw agent is slow, check these five things in this order:
- Reset the session with
/new— if it was fast at the start of the session and got slower, that's context bloat. Fixed in 2 seconds. - Switch to a faster model tier (Haiku 4.5, GPT-5 Mini, Gemini 3 Flash) — fixed in 30 seconds.
- Add a fallback provider to bypass rate limits — check the provider dashboard first; fixed in ~5 minutes.
- Check Docker/Ollama RAM usage or switch to a cloud API — fixed in ~10 minutes on the local-hardware path.
- Cap
maxIterationsto 10-15 to stop skill retry loops — check gateway logs for repeated errors; fixed in ~10 minutes.
80% of the time, it's #1. Try /new before anything else.
The deeper issue behind most OpenClaw performance problems is the same: the default configuration doesn't optimize for speed. It optimizes for completeness. Every message sends the full conversation history. Every skill runs without iteration limits. Every heartbeat uses your primary model. The agent works, but it works slowly because the defaults are generous rather than efficient.
If you want an agent where the performance optimization is built into the platform instead of configured manually, give BetterClaw a try. Free tier with 1 agent and BYOK. $49/month for Pro. Smart context management keeps the context lean automatically. Your agent stays fast at message 1 and message 100. 60-second deploy. No performance tuning required.
Frequently Asked Questions
Why is my OpenClaw agent slow?
The most common cause (roughly 80% of cases) is context bloat: long conversations accumulate input tokens, making every subsequent request larger and slower. By message 40, a single request can contain 25,000-30,000 input tokens. The fix: use /new every 20-25 messages to reset the conversation buffer. If it was fast when you started and got slower over time, context bloat is almost certainly the cause.
How do I speed up OpenClaw response time?
Five fixes in order: reset the session with /new (context bloat), switch to a faster model tier like Haiku 4.5, GPT-5 Mini, or Gemini 3 Flash (model speed), add a fallback provider (rate limit throttling), upgrade hardware or switch to cloud API (Docker/Ollama overhead), and set maxIterations to 10-15 (skill retry loops). Try /new first. It fixes the problem 80% of the time in 2 seconds.
Does the model affect how fast OpenClaw responds?
Significantly. Claude Opus 4.7 takes noticeably longer per response than Haiku 4.5; Sonnet 4.6 sits in the middle. GPT-5.5 is slower than GPT-5 Mini. Gemini 3.1 Pro is slower than 3 Flash. For most agent tasks, faster models produce equivalent quality at 2-3x the response speed. Use model routing to send simple tasks to fast models and complex tasks to capable ones.
How much RAM does OpenClaw need to run fast?
For cloud API usage (no local models), OpenClaw runs fine on 2GB+ RAM. For Docker-sandboxed execution, 4GB minimum, 8GB recommended. For local models via Ollama, 16GB+ RAM for 7B-8B models, 32GB+ for 32B models. Insufficient RAM causes container startup delays (Docker) or extremely slow token generation (Ollama). Cloud APIs are faster than local models on most consumer hardware.
Does BetterClaw fix OpenClaw performance issues?
BetterClaw includes smart context management that prevents the token bloat causing most OpenClaw slowness. The context stays lean automatically without manual /new resets. The platform also handles model routing, rate limit management, and skill execution monitoring. Free tier with 1 agent and BYOK. $49/month for Pro. The performance optimization is built into the platform, not left to manual configuration.