

Groq runs 4-12x faster than OpenAI. But it only serves open-source models. Here's when that tradeoff makes sense for agents.
I timed it. Literally pulled out a stopwatch.
Our test agent was classifying support tickets. Same prompt, same input, same output length. The only variable was the inference provider.
OpenAI's GPT-5.4: 12.5 seconds for a 1,000-token response.
Groq running Llama 3.3 70B: 2.5 seconds. Same response quality. Same tool-call structure. Five times faster.
For a single API call, the speed difference is nice. For an AI agent that chains 10-15 tool calls per task, each requiring a model inference step, the difference is the gap between a 3-minute workflow and a 30-second one. That's not a benchmarking curiosity. That's a fundamentally different user experience.
But here's the part that every Groq vs OpenAI comparison glosses over: Groq only runs open-source models. No GPT-5.5. No Claude. No Gemini. If your agent needs a proprietary frontier model, Groq isn't an alternative to OpenAI. It's a complement.
Let me break down exactly where Groq wins, where OpenAI wins, and how the math works for real agent workloads.
What Groq actually is (and isn't)
Groq is an inference hardware company. They built custom chips called LPUs (Language Processing Units) designed specifically to run LLMs fast. Not "fast" in the marketing sense. 300 to 960 tokens per second depending on the model, verified by Artificial Analysis. That's 4-12x faster than GPU-based inference from OpenAI.
What Groq is not: a model provider. Groq doesn't make AI models. They run other people's models on their hardware. Specifically, they run open-source models: Llama 3.3 70B, Llama 3.1 8B, gpt-oss-120B, gpt-oss-20B, Qwen3 32B, Kimi K2, and a handful of others.
This means you can't run GPT-5.5, Claude Opus 4.8, or Gemini 3.5 Flash on Groq. Those are proprietary models locked to their respective providers. If your agent workload requires a specific proprietary model, Groq is out of the conversation for that particular task.
But if your workload can run on open-source models (and an increasing number can), Groq's speed advantage is enormous and its pricing is aggressive.

The speed numbers that matter for agents
Here's why Groq's speed is especially relevant for AI agents rather than single API calls.
A typical agent task involves multiple inference steps. The agent receives a request, reasons about it, decides which tool to call, formats the tool parameters, waits for the tool response, reasons about the result, decides the next step, and repeats. Each reasoning step is a model inference call.
A 10-step agent workflow on OpenAI at ~80 tokens per second and a 500-token response per step: roughly 62 seconds of inference time.
The same workflow on Groq at ~400 tokens per second: roughly 12.5 seconds.
That's 50 seconds saved per task. On an agent handling 100 tasks per day, you're saving 83 minutes of total inference latency daily. For customer-facing agents where a user is waiting, this is the difference between "this is fast" and "this feels broken."
Artificial Analysis benchmarks confirm: Groq's fastest model (gpt-oss-20B) runs at 964 tokens per second with a 0.73-second time to first token. For comparison, OpenAI's GPT-5.4 runs around 80 TPS. That's a 12x throughput difference.
For the full breakdown of how model routing reduces AI agent costs, the routing principle applies perfectly here: fast, cheap models for speed-sensitive tasks, frontier models for quality-sensitive tasks.
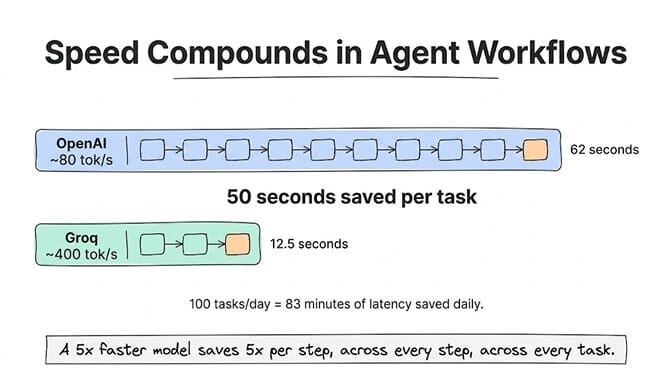
Speed compounds in agent workflows. A 5x faster model doesn't just save 5x time per call. It saves 5x time per step, across 10-15 steps per task, across hundreds of tasks per day.
The cost comparison: Groq is absurdly cheap (for what it offers)
Let's put real numbers on a month of agent workloads. I'll compare Groq's best open-source option (Llama 3.3 70B at $0.59/$0.79) against OpenAI's comparable tier (GPT-5.4 Nano at $0.10/$0.40) and OpenAI's frontier (GPT-5.5 at $5/$30).
Scenario: Support agent processing 3M input + 1M output tokens per day
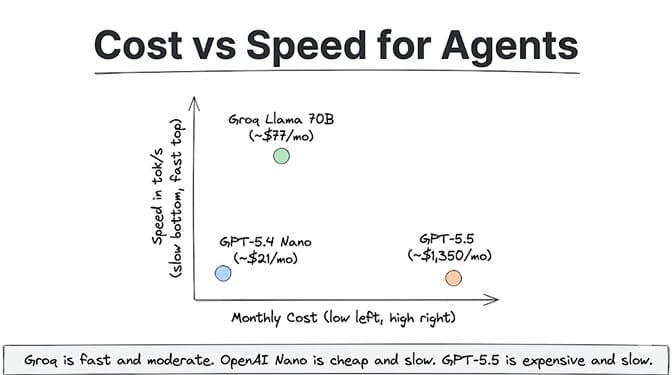
Groq (Llama 3.3 70B): (3 x $0.59) + (1 x $0.79) = $1.77 + $0.79 = $2.56/day = $76.80/month.
OpenAI (GPT-5.4 Nano): (3 x $0.10) + (1 x $0.40) = $0.30 + $0.40 = $0.70/day = $21/month.
OpenAI (GPT-5.5): (3 x $5) + (1 x $30) = $15 + $30 = $45/day = $1,350/month.
Here's the surprise. GPT-5.4 Nano is actually cheaper than Groq's Llama 3.3 70B on a per-token basis. OpenAI's small models are extremely competitive on price.
But here's the catch: GPT-5.4 Nano runs at ~80 tokens per second. Llama 3.3 70B on Groq runs at 394 tokens per second. The Groq version costs 3.6x more per token but responds 5x faster.
For a backend batch processing agent where nobody's waiting, GPT-5.4 Nano wins on cost. For a customer-facing chat agent where response time matters, Groq's speed premium is worth every penny.
And if you compare Groq against OpenAI's frontier tier (GPT-5.5), the math flips entirely. Groq's Llama 3.3 70B at $76.80/month delivers GPT-4o-level quality at 18x less cost than GPT-5.5 at $1,350/month. It's not the same quality class, but for many agent tasks, it's sufficient.
The model quality gap: honest assessment
This is where the comparison gets honest.
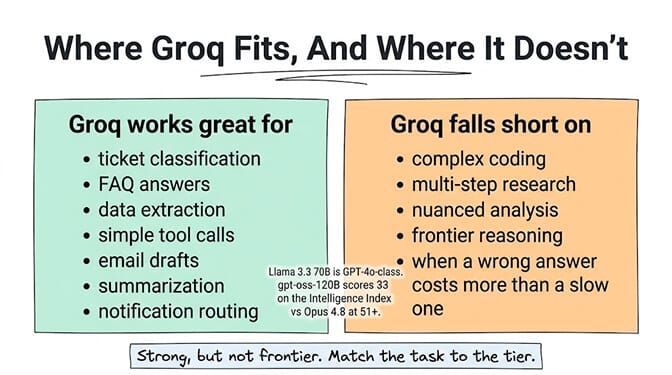
Llama 3.3 70B on Groq is a strong model. It delivers GPT-4o-level quality on most standard tasks: text generation, classification, summarization, simple tool calling. For the majority of agent workloads, it's more than sufficient.
But it's not GPT-5.5 quality. It's not Opus 4.8 quality. On complex multi-step reasoning, nuanced code generation, and hard analytical tasks, the frontier models pull ahead meaningfully. (For how those frontier options compare on quality and price, see our GPT-5.5 vs Claude vs DeepSeek breakdown.)
Groq's gpt-oss-120B model closes some of that gap. It scores 33 on Artificial Analysis's Intelligence Index (compared to Opus 4.8's 51+). Better than the smaller models, but still a tier below the frontier.
Here's the practical framework:
Groq works great for: support ticket classification, FAQ answering, data extraction, simple tool calling, email drafting, content summarization, notification routing, calendar management.
Groq falls short on: complex coding tasks, multi-step research synthesis, nuanced business analysis, tasks requiring frontier-level reasoning, anything where a wrong answer costs more than a slow answer.
Groq's free tier is the best testing deal in inference
If you haven't tried Groq, the free tier is genuinely worth testing. No credit card required. Access to every model. 14,400 requests per day on Llama 3.1 8B. 30 requests per minute across the board.
For prototyping agent workflows, the free tier is ideal. You can build and test an entire agent pipeline without spending a dollar on inference.
The rate limits matter for production (30 RPM caps at one request per 2 seconds steady state), but for development and testing, it's the most generous free LLM API tier available in 2026.
This is where a BYOK agent platform makes the testing phase painless. On BetterClaw, you connect a Groq API key for development (free tier, fast iteration). When you're ready for production, you swap in your OpenAI or Anthropic key for the workloads that need frontier quality, and keep Groq for the speed-sensitive tasks. Same agent, same visual builder, different models per task. Free plan with 1 agent and 500 credits a month. $49/month on Pro. Zero inference markup.
The agent architecture that uses both
Here's the setup that actually makes sense for most teams:
Route by task type, not by provider loyalty.
Speed-critical, user-facing tasks: Groq (Llama 3.3 70B at 394 tok/s). Customer chat responses, real-time classification, instant notifications. The user is waiting. Speed matters more than peak quality.
Quality-critical, background tasks: OpenAI (GPT-5.5) or Anthropic (Opus 4.8). Complex analysis, code generation, research synthesis. Nobody's watching the clock. Quality matters more than speed.
High-volume, cost-sensitive tasks: OpenAI (GPT-5.4 Nano at $0.10/$0.40) or DeepSeek V4 Pro ($0.435/$0.87). Batch processing, data extraction, log analysis. Volume is high. Neither speed nor frontier quality is the priority. Cost is.
This multi-provider routing is exactly what BYOK platforms are built for. You connect keys from Groq, OpenAI, Anthropic, and DeepSeek. Each agent (or each task within an agent) routes to the optimal provider. (If you'd rather aggregate them behind one key, our OpenRouter vs direct API comparison weighs that tradeoff.) Your support chat agent uses Groq for instant responses. Your coding agent uses Opus 4.8 for accuracy. Your data pipeline uses DeepSeek for cost.
For a deeper look at how to choose the right model for each task, the decision framework maps well to this multi-provider approach.
The NVIDIA question hanging over everything
I should mention this because it affects Groq's future pricing: NVIDIA's $20 billion deal with Groq, announced in late 2025, reshaped the company's trajectory. The deal brings NVIDIA's distribution and manufacturing muscle to Groq's LPU architecture.
What this might mean: more LPU capacity, potentially lower prices, potentially more model support. What it definitely means: Groq isn't going away. The $20B investment is a strong signal that LPU-based inference is here to stay as a category.
For agent builders, the practical implication is that Groq's speed advantage is likely to persist and potentially grow, while GPU-based providers continue competing on price. The optimal strategy remains the same: use the fastest provider for latency-sensitive tasks and the cheapest provider for volume tasks.
The decision in plain language
If you're building AI agents and evaluating Groq vs OpenAI, here's the honest summary:
Choose Groq when: response speed is your primary concern, your workload runs well on Llama 3.3 70B or similar open-source models, you want the free tier for development, or you need sub-3-second responses for customer-facing agents.
Choose OpenAI when: you need GPT-5.5 quality specifically, your workload requires frontier-level reasoning, you need the largest ecosystem of tools and integrations built for the OpenAI API format, or cost matters more than speed (GPT-5.4 Nano is cheaper per token than Groq's 70B models).
Choose both when: you're serious about cost and performance optimization. Most production agent systems in 2026 use 2-3 providers. Groq for speed. OpenAI or Anthropic for quality. DeepSeek for cost. The platforms that make this easy are the ones worth using.
If any of this resonated, give BetterClaw a look. Free plan with 1 agent and 500 credits a month. $49/month for Pro. Connect Groq, OpenAI, Anthropic, DeepSeek, or any of 28+ providers. Zero inference markup. We handle the routing and the infrastructure. You handle building the agent that actually solves the problem.
Frequently Asked Questions
What is Groq and how is it different from OpenAI for AI agents?
Groq is an inference hardware company that runs open-source LLMs on custom LPU chips at 300-960 tokens per second, which is 4-12x faster than GPU-based providers like OpenAI. The key difference: Groq only runs open-source models (Llama, gpt-oss, Qwen, Kimi K2). OpenAI runs its proprietary GPT models. For agents, Groq offers speed at the cost of model selection, while OpenAI offers model quality at the cost of latency.
How does Groq speed compare to OpenAI API for agent workloads?
Groq's Llama 3.3 70B runs at 394 tokens per second versus OpenAI's GPT-5.4 at roughly 80 tokens per second. For a 10-step agent workflow with 500-token responses per step, Groq completes in about 12.5 seconds versus OpenAI's 62 seconds. The speed difference compounds across multi-step workflows, making Groq significantly faster for customer-facing agents where users are waiting.
Is Groq cheaper than OpenAI for AI agents?
It depends on which models you're comparing. Groq's Llama 3.3 70B ($0.59/$0.79 per MTok) is more expensive per token than OpenAI's GPT-5.4 Nano ($0.10/$0.40) but 18x cheaper than GPT-5.5 ($5/$30). Groq wins on speed per dollar. OpenAI's small models win on absolute cost. For agents processing 3M input + 1M output tokens daily: Groq costs ~$77/month, GPT-5.4 Nano costs ~$21/month, GPT-5.5 costs ~$1,350/month.
Does Groq have a free API tier for testing AI agents?
Yes. Groq offers a free tier with no credit card required that provides access to every supported model. Rate limits are 30 requests per minute and 14,400 requests per day on Llama 3.1 8B. The free tier is genuinely useful for prototyping agent workflows. For production traffic, the Developer tier (add a credit card) provides 10x higher rate limits at the same per-token pricing.
Can I use Groq and OpenAI together in the same AI agent?
Yes. BYOK (Bring Your Own Key) agent platforms like BetterClaw let you connect API keys from multiple providers and route different tasks to different models. A common setup: Groq for speed-sensitive, user-facing tasks and OpenAI or Anthropic for quality-sensitive background tasks. This multi-provider approach optimizes both cost and performance without locking you into a single inference provider.



