
What Z.ai's open-weights frontier model actually feels like when you put it in an agent and let it run for a month.
Day 3. The GLM 5.1 agent finished a refactor I'd expected to take most of the afternoon.
Not "drafted it." Finished it. Tests green. PR posted. The kind of result I'd been getting from Claude Opus on a good day, at roughly a third of the cost.
I'd had the agent running on GLM 5.1 for about 72 hours at that point, pointed at a real internal codebase, handling real tasks. And I did the thing I always do when a new model surprises me: I assumed it was luck. Ran the same brief again with a different project. Same quality output. Ran it a third time. Fine.
I've been running it for thirty days now. This is the honest review.
What GLM 5.1 actually is
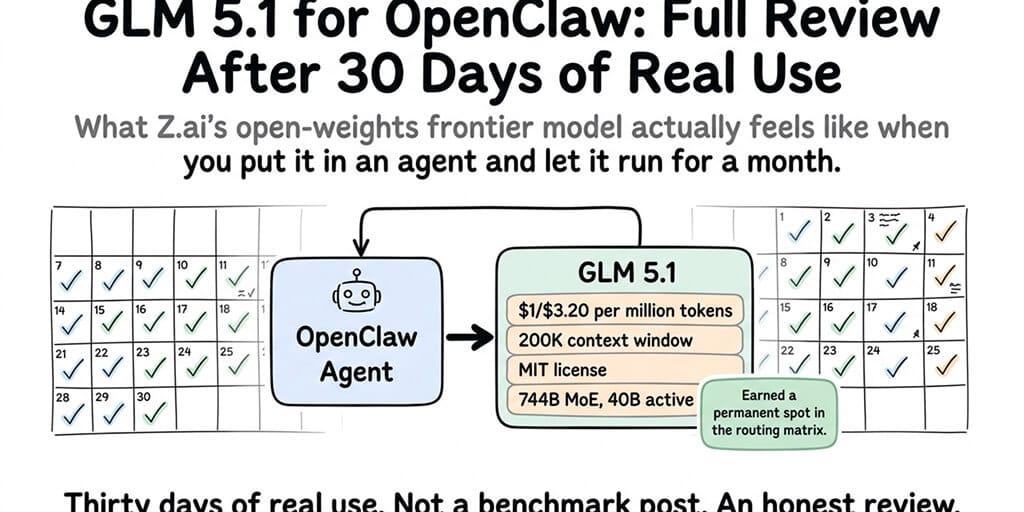
Quick recap for anyone who hasn't been following. GLM 5.1 is Z.ai's (formerly Zhipu AI) latest flagship model. API launched March 27, 2026. Open weights dropped April 7 on Hugging Face under MIT license. 744 billion parameters in a Mixture-of-Experts architecture, 40 billion active per token. 200K context window. Trained entirely on Huawei Ascend 910B chips with zero Nvidia hardware.
The number that got everyone's attention: 58.4 on SWE-Bench Pro, officially ahead of Claude Opus 4.6 at 57.3 on that specific benchmark.
The number that matters for OpenClaw specifically: $1 per million input tokens, $3.20 per million output. That's roughly 3x cheaper than Claude Sonnet 4.6 at $3/$15 and about 5x cheaper than Opus.
For most of the last year, running a serious OpenClaw agent meant either paying Anthropic prices or accepting a meaningful capability downgrade. GLM 5.1 is the first time that tradeoff has a third option.
Day 1 through Day 7: the setup
The first week was almost entirely setup and calibration, not judgment.
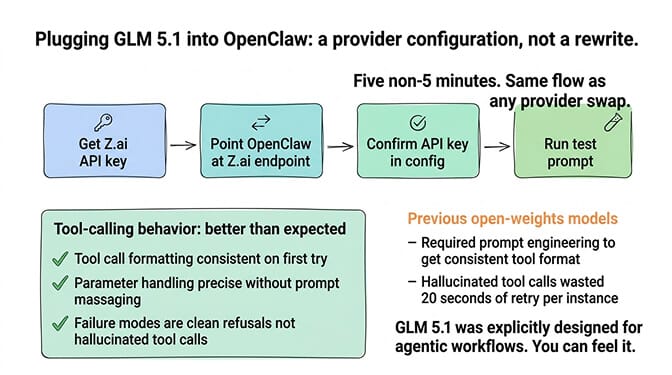
Plugging GLM 5.1 into an OpenClaw agent is a provider configuration, not a rewrite. If you've swapped models before, this is the same flow. If you haven't, it's roughly five minutes of work to point your agent at Z.ai's endpoint and confirm the API key.
The thing I didn't expect: the tool-calling behavior needed less massaging than I anticipated. GLM 5.1 was explicitly designed for agentic workflows, and you can feel it. Tool call formatting is consistent. Parameter handling is precise. The failure modes when it can't do something are clean refusals, not hallucinated tool calls that waste 20 seconds of retry.
Compared to earlier open-weights models I'd tried in agents, this felt like a different category of experience.
Day 8 through Day 14: where it actually shines
The second week is where I stopped evaluating and started using.
Three workload categories where GLM 5.1 consistently delivered.
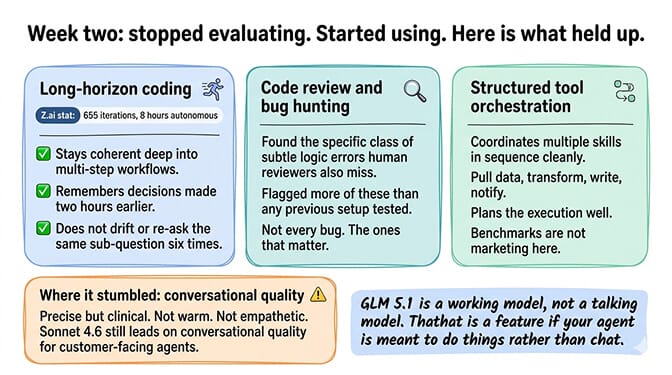
Long-horizon coding tasks. Z.ai demonstrated the model running for eight hours straight on a single task, completing 655 iterations autonomously. That's marketing. What I can confirm: in my actual use, GLM 5.1 stays coherent deep into multi-step workflows in a way most models don't. It remembers what it decided two hours ago. It doesn't drift. It doesn't re-ask the same sub-question six times.
Code review and bug hunting. Pointed at a real repo with real bugs, the agent found issues at a rate that genuinely surprised me. Not every bug. But the specific class of subtle logic errors that human reviewers also miss, GLM 5.1 flagged more of than previous setups I'd tested.
Structured tool orchestration. The agentic benchmarks aren't marketing. When an OpenClaw agent needs to coordinate several skills in sequence (pull data from one source, transform it, write it to another, notify someone), GLM 5.1 plans the sequence well and executes cleanly.
Where it stumbled in those two weeks: casual conversational quality. If you want your agent to sound warm, empathetic, or naturally conversational with end users, Sonnet 4.6 is still ahead. GLM 5.1 is precise but a bit clinical. For internal tools, this doesn't matter. For customer-facing agents, it might.
GLM 5.1 is a working model, not a talking model. That's a feature, not a bug, if your agent is meant to do things rather than chat.
Day 15 through Day 21: the cost story
This is the part everyone actually wants to know.
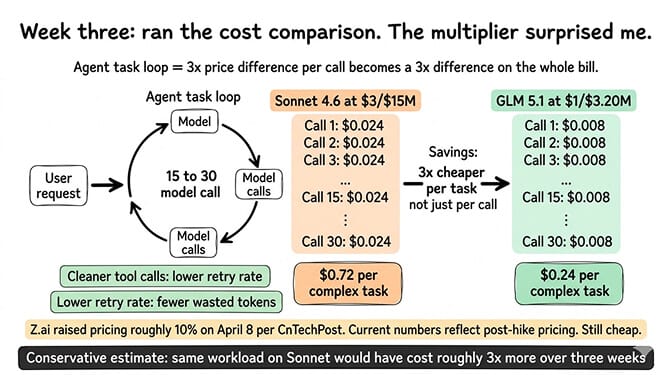
Three weeks in, I ran a rough comparison against what the same workload would have cost me on Sonnet 4.6. Conservative estimate: running the same agent on Sonnet would have cost me about three times more over that period.
The multiplier compounds because OpenClaw agents don't make one model call per request. They loop. A single complex task might trigger 15 to 30 internal calls. A 3x price difference per call turns into a 3x price difference on the whole bill.
That's before you factor in any context overhead reduction from sharper tool-call behavior. Cleaner tool calls mean fewer retries. Fewer retries mean fewer wasted tokens. My total retry rate on GLM 5.1 was noticeably lower than what I was seeing on older open-weights models I'd tested.
There's a caveat worth naming. Z.ai raised GLM pricing roughly 10% on April 8, per reporting from CnTechPost. The pricing I quoted at the top is the current post-hike pricing. The trend line is: still cheap, but not going to stay 5x cheaper than Opus forever.
Day 22 through Day 30: where it breaks down
Not everything was clean. Three honest problems from the last week.
Speed. GLM 5.1 runs at around 44 tokens per second through Z.ai's API. That's slow by 2026 standards. Sonnet 4.6 runs around 54. For interactive use, you feel the difference. For background agent work running overnight, you don't care.
Peak reasoning on the hardest problems. Claude Opus 4.6 still wins on the most complex multi-step reasoning tasks. If your agent regularly needs to work through the kind of problem where Opus was the previous bar, GLM 5.1 is close but not quite there. The broader coding composite has Opus at 57.5 vs GLM's 54.9. That gap shows up in specific workloads.
Geopolitical overhead. Running an agent on a model trained entirely on Huawei Ascend chips, from a company on the US Entity List, matters for some deployments and doesn't for others. If your product serves enterprise customers with compliance requirements, check before you commit. If you're building solo, it's probably fine.
None of these broke the review. All of them are things I'd want to know before deploying GLM 5.1 for a specific use case.

The thing that surprised me most
Here's the weird part. The feature I ended up caring about most wasn't the price or the benchmarks.
It was the MIT license.
For thirty days I ran GLM 5.1 through the Z.ai API. But the open weights being available under a permissive license changes the strategic math for anyone building a real business on top of agents. You're not locked into one provider's pricing, rate limits, or terms of service. If Z.ai triples its prices next year, you can self-host. If they change their content policies in ways that break your product, you can self-host. If they have an outage, you have options.
Most teams won't actually self-host. Running a 744B MoE model at production quality takes serious infrastructure. But the option to self-host is a different kind of relationship with your model provider than you get with Anthropic or OpenAI.
If you've been managing model flexibility through multi-provider routing in OpenClaw, GLM 5.1 slots in cleanly as the cost-efficient heavy-lifting option in your routing matrix. Sonnet 4.6 for anything customer-facing. GLM 5.1 for long-running technical work. You pay for reliability where it shows to users and cost-efficiency where it doesn't.
If you want to run GLM 5.1 inside OpenClaw without building the provider integration, routing logic, and credential management yourself, BetterClaw supports 28+ model providers including GLM, Claude, and MiniMax with per-skill model selection. $49/month for Pro, BYOK.
Should you self-host GLM 5.1?
The MIT license makes self-hosting technically possible. The math tells you whether it's practical.
For small volumes (under a few hundred million tokens a month), the Z.ai API at $1/$3.20 is cheaper than running your own hardware once you factor in GPU costs, ops time, and model update cycles. For large volumes, the break-even flips somewhere around 500M to 1B tokens monthly.
The hidden cost of self-hosting a 744B MoE is operational, not just hardware. You're running vLLM or SGLang. You're managing quantization tradeoffs between FP8 and full precision. You're dealing with model update cycles when Z.ai ships GLM 5.2 next quarter and you have to decide whether to upgrade your production deployment.
This is the same trap self-hosted OpenClaw deployments fall into at the framework level. Self-hosting a piece of your stack looks cheap on paper and turns into a second job in practice.
My recommendation: use GLM 5.1 via API for the first six months. If your usage actually grows past the break-even threshold and stays there, then evaluate self-hosting with real numbers.
The 30-day verdict
Thirty days in, GLM 5.1 has earned a permanent spot in my model routing matrix for OpenClaw.
Not as the default for everything. Sonnet 4.6 still handles customer-facing work. MiniMax M2.7 still handles high-volume cheap decisions. But for long-running coding work, technical document processing, and the kind of agent tasks that need to keep reasoning for hours without a human in the loop, GLM 5.1 has become my first choice.
Three months ago, I would have told you the best LLM for an OpenClaw agent was some flavor of Claude with a cost disclaimer attached. Today, that answer has genuinely changed. The open-source gap closed. The price/capability curve shifted. The routing math got more interesting.
If you've been paying Claude prices for every single agent call and wondering if there's a better way, there now is. If you want to try GLM 5.1 inside an OpenClaw agent without wrestling with provider setup, give Better Claw a try. $49/month for Pro, BYOK, GLM 5.1 and 27 other providers available, and your first deploy takes about 60 seconds. We handle the integration. You handle the decision of which model goes where.
Thirty days of real use doesn't make a model infallible. It makes it trustworthy enough to bet production work on. GLM 5.1 passed that bar for me. The next six months will tell us whether it holds up at scale or gets eaten by the next release from Anthropic, OpenAI, or Z.ai themselves.
Right now, though? It's the most interesting model to put inside an OpenClaw agent in 2026. And "most interesting" has earned its place in a year that's been anything but quiet.
Frequently Asked Questions
What is GLM 5.1 for OpenClaw?
GLM 5.1 is Z.ai's latest open-weights flagship model, a 744 billion parameter Mixture-of-Experts with 40 billion active parameters, released March 27, 2026 via API and open-sourced April 7 under MIT license. When used inside OpenClaw, it serves as the LLM that powers the agent's reasoning and tool-calling. Z.ai explicitly designed GLM 5.1 for agentic workflows, making it a natural fit for OpenClaw deployments focused on autonomous task execution.
How does GLM 5.1 compare to Claude Sonnet 4.6 for OpenClaw agents?
GLM 5.1 is roughly 3x cheaper on API at $1/$3.20 per million tokens vs Sonnet 4.6's $3/$15, and scores 58.4 on SWE-Bench Pro vs Sonnet's 79.6 on SWE-bench Verified (different benchmarks, not directly comparable). For heavy coding and long-running autonomous work, GLM 5.1 wins on cost-to-capability. For customer-facing conversational agents, Sonnet's conversational quality still leads. Most production setups use both, routing tasks based on type. See how Sonnet compares to other Claude models for agent work for more context.
How do I set up GLM 5.1 inside an OpenClaw agent?
At a high level: get a Z.ai API key, point your OpenClaw agent at the Z.ai endpoint with GLM 5.1 selected as the model, and verify the agent can call tools correctly with a test prompt. On managed platforms like BetterClaw, this is a dropdown selection. On self-hosted OpenClaw, you're editing configuration and managing credentials yourself. Check the current OpenClaw docs for exact configuration fields since provider support is evolving.
Is GLM 5.1 worth using over Claude to save money on OpenClaw API costs?
For coding-heavy, technical, or long-running agent workloads, yes. GLM 5.1 at ~3x cheaper and competitive capability on those specific tasks makes the math work. For customer-facing agents where conversational warmth matters, Sonnet 4.6 still earns its premium. Related reading: how to reduce OpenClaw API costs covers the full cost-optimization strategy including multi-model routing.
Is GLM 5.1 reliable enough for production OpenClaw agents?
For most internal and technical workloads, yes. I've been running it for 30 days in production-adjacent workloads and it holds up. The caveats: speed is slower than Sonnet (~44 tokens/sec vs ~54), peak reasoning on the hardest problems still lags Opus 4.6, and the model's training on US Entity List-sanctioned hardware matters for some enterprise compliance requirements. For the right use cases, it's genuinely production-ready.



