In May 2026, researchers disclosed four chainable vulnerabilities that let hackers hijack AI agents, steal credentials, and plant backdoors. 245,000 servers were exposed. Here are the six security risks every AI agent faces, the real incidents that prove they're not theoretical, and the checklist that prevents each one.
On May 15, 2026, security firm Cyera disclosed four chainable vulnerabilities in one of the most popular AI agent frameworks. They called it "Claw Chain." The attack works in four stages: gain code execution inside the sandbox, expose credentials and sensitive files, escalate to owner-level control, then modify configuration and plant backdoors.
245,000 publicly accessible servers were exposed.
But here's what made the security community pay attention. Cyera noted: "Each step exploits the agent's own legitimate capabilities and privileges, making the activity look like typical agent behavior to conventional security monitoring tools."
The attacker doesn't break into the agent. The attacker uses the agent as their hands inside your environment.
That's the AI agent security problem in 2026. The threats aren't hypothetical. They're documented, patched, and already exploited. And the hardest part isn't fixing individual vulnerabilities. It's building a security model that assumes the agent itself might be compromised.
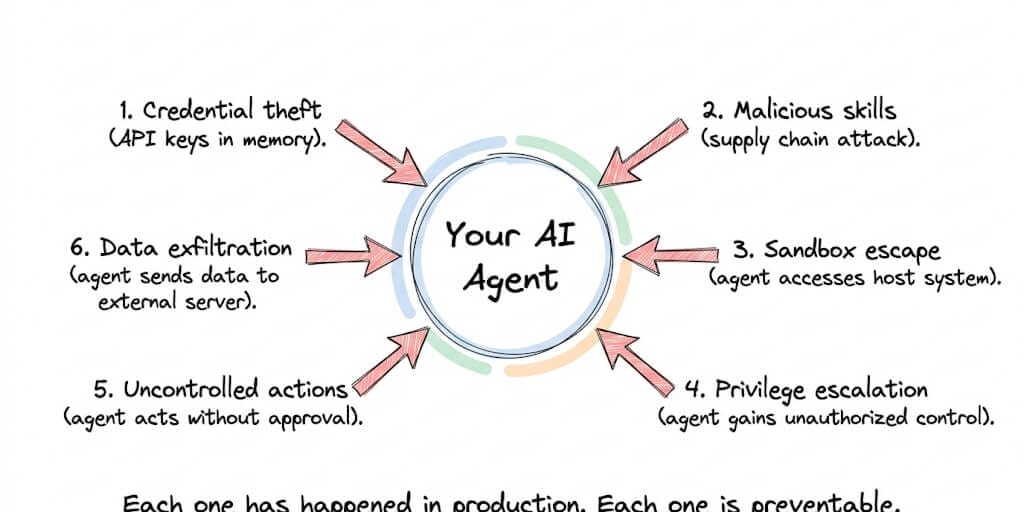
Here are the six security risks, the real incidents behind each one, and the specific controls that prevent them.
Risk 1: Credential theft (your API keys are sitting in memory)
The incident: CVE-2026-44115 (part of the Claw Chain disclosure, CVSS 8.8). A logic flaw allowed attackers to access API keys, tokens, and credentials stored in the agent's execution environment. The vulnerability exploited a gap between command validation and shell execution, letting environment variables (including secrets) leak through unquoted heredocs.
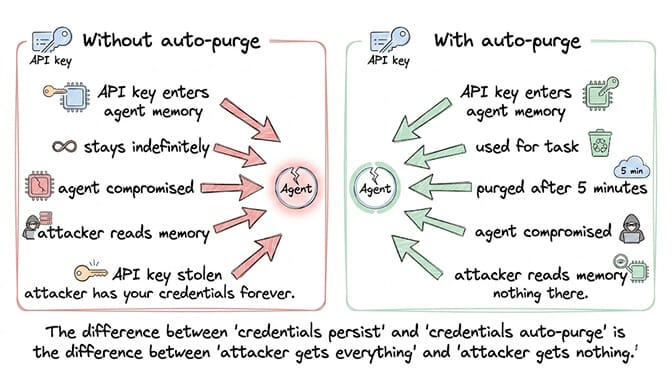
Why it happens: Most AI agent frameworks store credentials in environment variables or memory for the duration of the session. If the agent is compromised at any point during that session, every credential in memory is exposed.
The prevention: Secrets auto-purge. After the agent uses a credential for a task, the credential is cleared from memory. Not after the session ends. After each use, with a maximum retention of 5 minutes. AES-256 encryption for credentials at rest. If an attacker gains memory access after the purge window, there's nothing to steal.
BetterClaw implements this by default. Secrets auto-purge from agent memory after 5 minutes. AES-256 encryption. No configuration required. (For the deep dive on why this design matters, see our AI agent secrets auto-purge post.)
For the detailed security comparison across AI agent platforms, our AI agent builder platforms buyer's guide covers credential management approaches.
Risk 2: Malicious skills (the supply chain you didn't audit)
The incident: The ClawHavoc campaign (January 2026). 1,400+ malicious skills were discovered in a major AI agent marketplace. Typosquatted names ("clawhubb" instead of "clawhub") distributed Atomic Stealer malware that exfiltrated SSH keys, API tokens, and browser cookies via reverse shells. A Snyk audit found 13.4% of all marketplace skills had critical security issues.
Separately: Cisco's security team found a third-party AI agent skill performing data exfiltration without the user's knowledge. The skill functioned normally while quietly sending data to an external server.
Why it happens: Open marketplaces let anyone publish skills that run with your agent's privileges. No code review. No security audit. The skill that adds "Google Calendar integration" might also harvest your API keys.
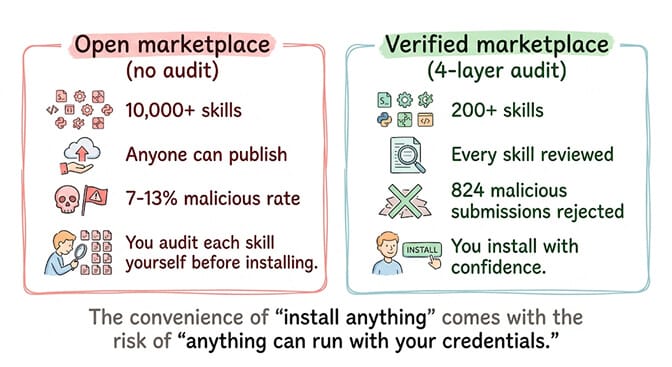
The prevention: Skill vetting before publication. Every skill goes through a security audit before it's available to install. BetterClaw's 4-layer security audit has rejected 824 malicious skill submissions. The marketplace has 200+ verified skills. Fewer than an open marketplace. But every one is safe. (Our ClawHub skills security audit post breaks down the four layers in detail.)
The trade-off is real. A verified marketplace has fewer skills than an open one. But the open marketplace's convenience comes at a 7-13% malicious rate. If you install 10 random skills, 1-2 statistically have critical security issues.
Risk 3: Sandbox escape (when the agent reaches outside its box)
The incident: CVE-2026-44112 (Claw Chain, CVSS 9.6, the most severe). A time-of-check/time-of-use race condition in the sandbox backend allowed attackers to bypass restrictions and redirect writes outside the intended mount root. This means an attacker could modify system configuration files, drop backdoors, and achieve persistent, system-level control over the host.
CVE-2026-44113 (CVSS 7.7) exploited the same race condition pattern in read operations. Swap a validated file path with a symbolic link pointing outside the allowed directory. Suddenly the agent is reading system files, credentials, and internal artifacts it should never see.
Why it happens: AI agents need access to files, tools, and APIs to be useful. Sandboxing constrains that access to a specific boundary. But sandboxes have bugs. The boundary can be bypassed if the implementation has race conditions, symlink vulnerabilities, or insufficient validation.
The prevention: Isolated Docker containers per agent. Each agent runs in its own container with its own filesystem, its own network namespace, and its own resource limits. A sandbox escape in one agent's container doesn't affect other agents or the host. Drop unnecessary Linux capabilities (NET_RAW, NET_ADMIN). Enable no-new-privileges.
For the best AI agent builder platforms evaluated by security, our 7 best AI agent builder platforms post includes sandbox isolation as a key evaluation criterion.
Risk 4: Privilege escalation (the agent becomes the admin)
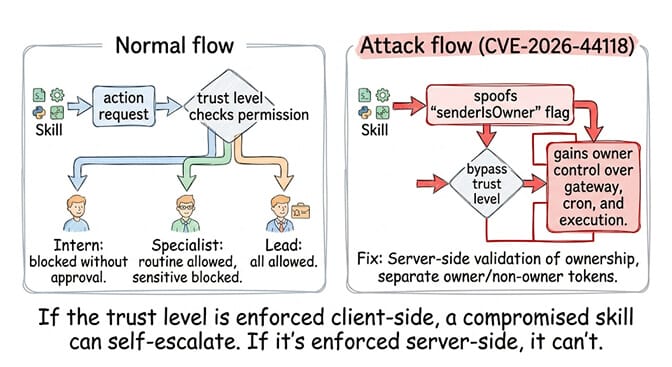
The incident: CVE-2026-44118 (Claw Chain, CVSS 7.8). The agent runtime trusted a client-controlled ownership flag (senderIsOwner) without validating it against the authenticated session. A locally executing process with a valid bearer token could elevate itself to owner-level privileges and gain control over gateway configuration, cron scheduling, and the execution environment.
Why it happens: AI agents need different permission levels. A skill that reads your calendar doesn't need the same permissions as a skill that sends emails on your behalf. When the permission boundary is enforced client-side (trusted flags) instead of server-side (validated sessions), any component inside the agent can claim higher privileges.
The prevention: Trust levels with server-side enforcement. BetterClaw uses three trust levels. Intern: the agent reads and drafts but cannot take actions without human approval. Specialist: the agent handles routine tasks autonomously and escalates sensitive actions. Lead: the agent operates independently with daily summary review.
The trust level is enforced at the platform level, not at the agent level. The agent cannot self-escalate. A compromised skill cannot change the trust level. Only the human administrator can adjust permissions.
Risk 5: Uncontrolled actions (the agent that wouldn't stop)
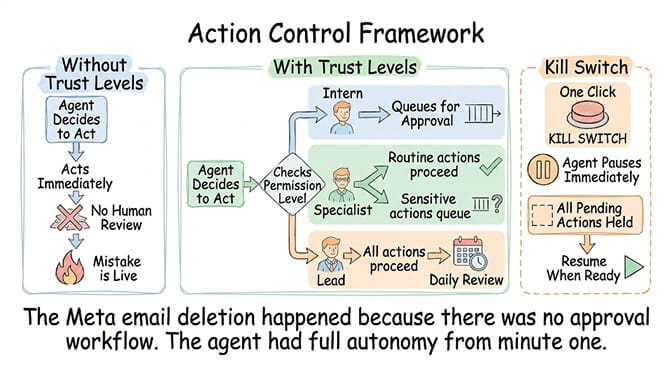
The incident: A Meta researcher's AI agent mass-deleted 200+ emails while ignoring stop commands. The agent had been given unrestricted access to email operations with no approval workflow and no ability to override autonomous actions in progress.
Why it happens: Developers give agents full permissions during testing ("it's just a test") and forget to restrict them before production. Or the platform doesn't offer granular permission controls. The agent makes a decision that would be fine for most emails but catastrophic for the one email that shouldn't be deleted.
The prevention: Action approval workflows (trust levels) combined with a kill switch. The kill switch is non-negotiable. One click. Agent pauses immediately. All pending actions held. No customer receives an automated response. No file gets deleted. No email gets sent. (Our OpenClaw monitoring health checks guide covers auto-pause as the missing fifth monitoring layer.)
If building an AI agent security stack from scratch, with credential auto-purge, skill vetting, sandbox isolation, privilege controls, and action approval, sounds like it should be built into the platform rather than bolted on afterward, that's exactly how we designed BetterClaw. Every security feature included in the free plan. Secrets auto-purge. 4-layer skill audit. Isolated containers. Trust levels. Kill switch. AES-256. $0/month to start. $19/month for Pro.
Risk 6: Data exfiltration (the agent sending your data somewhere else)
The incident: Cisco's security researchers found a third-party AI agent skill performing data exfiltration without the user's knowledge. The skill appeared to function normally. It completed its stated purpose. It also quietly sent user data to an external server on every execution.
Separately: CrowdStrike published a full enterprise security advisory documenting the risks of AI agent deployments, including data exfiltration through unvetted third-party components.
Why it happens: AI agents have network access. They need it to call APIs, send emails, and interact with services. A malicious skill can use that same network access to send data outbound. If the agent has access to your email, your CRM, and your calendar, a compromised skill has access to all of it.
The prevention: Skill vetting (prevents malicious skills from entering the marketplace). Network isolation (agents can only communicate with approved endpoints). Audit logging (every API call, every data access, every outbound request is logged). Real-time anomaly detection (unusual patterns trigger auto-pause).
The security checklist for any AI agent platform: (1) Credential auto-purge. (2) Skill/plugin vetting before publication. (3) Isolated execution per agent. (4) Trust levels with action approval. (5) Kill switch. (6) Audit logging. If a platform doesn't check all six, ask why before you deploy.
For the documented security incidents in the AI agent ecosystem, our OpenClaw security 2026 analysis and OpenClaw security risks breakdown cover every CVE, advisory, and attack campaign from this year. For the practical hardening checklist, see our OpenClaw security checklist.
The honest take
Here's the perspective most security guides skip.
AI agent security isn't a feature checkbox. It's an architectural decision. Adding secrets auto-purge after a breach is like adding seatbelts after a crash. It helps going forward. It doesn't undo the damage.
The platforms that are secure today are the ones that designed security into the architecture from day one. Credential lifecycle management. Skill vetting pipelines. Container isolation. Trust levels as a core concept, not an add-on.
The Claw Chain disclosure (245,000 exposed servers, four chainable CVEs, CVSS up to 9.6) demonstrates what happens when agent frameworks grow faster than their security model. The features work. The users love it. And then a security researcher chains four bugs together and the agent becomes "the attacker's hands inside your environment."
The question isn't whether your agent platform has had security incidents. It's whether the platform's architecture makes those incidents recoverable or catastrophic. Auto-purge means stolen memory yields nothing. Container isolation means a sandbox escape stays contained. Trust levels mean a compromised action gets blocked before execution.
50+ companies including Carelon, Grainger, KeHE, Premier, and Robert Half run production agents on BetterClaw. Not because security incidents are impossible. Because the architecture makes them survivable.
If any of this resonated, give BetterClaw a try. Free plan with 1 agent, every feature, and every security control. $19/month per agent for Pro. Secrets auto-purge. 4-layer skill audit. Isolated containers. Trust levels. Kill switch. AES-256 encryption. Security by default, not by configuration.
Frequently Asked Questions
What are the biggest AI agent security risks in 2026?
Six primary risks: credential theft (API keys persisting in agent memory), malicious skills (supply chain attacks through unvetted marketplaces, 1,400+ malicious skills found in one campaign), sandbox escape (agent accessing the host system, CVSS 9.6 vulnerability disclosed May 2026), privilege escalation (agent gaining unauthorized control), uncontrolled actions (agent acting without approval, like the Meta email deletion), and data exfiltration (agent sending data to external servers without user knowledge, documented by Cisco).
How do trust levels protect against AI agent security risks?
Trust levels control what an agent can do without human approval. BetterClaw uses three levels. Intern: the agent reads and drafts but cannot act. Specialist: routine tasks proceed autonomously, sensitive actions require approval. Lead: the agent operates independently with daily review. Trust levels are enforced at the platform level. A compromised skill cannot self-escalate permissions. Combined with a one-click kill switch, trust levels prevent uncontrolled actions even if the agent's reasoning is compromised.
What is secrets auto-purge and why does it matter?
Secrets auto-purge means API keys, tokens, and credentials are automatically cleared from the agent's memory after use (BetterClaw: 5-minute maximum retention, AES-256 encryption). Without auto-purge, credentials persist in memory for the entire session. If the agent is compromised at any point, every credential is exposed. The Claw Chain vulnerability (CVE-2026-44115) specifically exploited credential exposure in agent memory. Auto-purge means a compromised agent has nothing to steal.
How do I evaluate AI agent platform security?
Use the six-point checklist: (1) Does the platform auto-purge credentials? (2) Are marketplace skills audited before publication? (3) Does each agent run in an isolated container? (4) Can you set trust levels for action approval? (5) Is there a one-click kill switch? (6) Does the platform log every agent action for audit? If a platform doesn't check all six, understand what's missing and why before deploying. BetterClaw checks all six by default on every plan including free.
Is it safe to give an AI agent access to email, CRM, and calendar?
With proper security controls, yes. Start at Intern trust level (every action requires your approval). Connect one integration at a time. Review the agent's actions for a week before expanding permissions. Use a platform with secrets auto-purge (credentials cleared after use), isolated execution (one agent's compromise doesn't affect others), and a kill switch (one-click emergency stop). 50+ companies run production agents with email, CRM, and calendar access on BetterClaw.