
Your agent forgets things. Four tools promise to fix it. Here's what each one actually does and which one you should install first.
Three weeks into using OpenClaw, I asked my agent who managed our auth team. I'd told it this in a conversation ten days earlier. The agent searched its memory, retrieved six chunks of text about authentication, and couldn't connect any of them to the person I'd mentioned.
The information was there. The retrieval couldn't find it. That's the difference between storing memory and understanding memory.
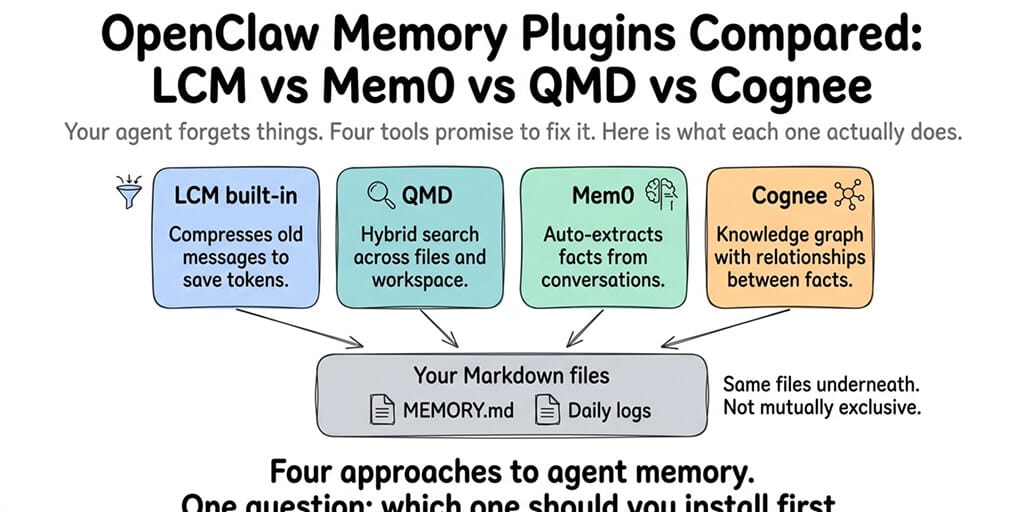
OpenClaw's default memory system works fine for the first few weeks. After that, the limitations show up in specific, predictable ways. The current ecosystem has several memory engines and plugins that fix these limitations in different ways: OpenClaw's built-in compaction (the active-session layer), QMD (hybrid search sidecar), Mem0 (automatic fact extraction), Cognee (knowledge graph), Honcho (cross-session user modeling), and Memory LanceDB (open-source vector store). Memory Wiki and Dreaming sit alongside these as structured-knowledge and consolidation layers respectively — covered in our Memory Wiki guide.
They solve different problems. They're not interchangeable. And most people install the wrong one first. Here's the honest comparison.
At a glance
| Plugin | Layer | Cost | Setup | Privacy | Best for |
|---|---|---|---|---|---|
| Built-in compaction | Active session | Free | Built-in | Local | Default; tune freshTailCount for long sessions |
| Lossless Claw (LCM) | Active session | Free | ~5 min | Local | Drop-in compaction replacement |
| Built-in SQLite memory | Cross-session retrieval | Free | Built-in | Local | Baseline; supports keyword + vector + hybrid |
| QMD | Cross-session retrieval | Free | ~5 min | Local | Most users — sidecar with BM25 + vector + rerank |
| Memory LanceDB | Cross-session retrieval | Free | ~5 min | Local (with Ollama embeddings) | Local-first auto-capture, larger stores |
| Mem0 | Auto-capture | Free / $249 Cloud Pro | 30s-15min | Cloud or local | Hands-off users who don't curate MEMORY.md |
| Cognee | Knowledge graph | Free / $200 Cloud Team | ~15 min | Local or cloud | Relational queries across people/projects/teams |
| Honcho | User modeling | Free | ~10 min | Local | Multi-user agents, implicit preference tracking |
| Memory Wiki | Structured knowledge | Free | ~10 min | Local | Durable facts with provenance & freshness |
| Dreaming | Consolidation | Free | Built-in (2026.4.5+) | Local | Automated promotion of short-term signals |
Compaction (top two rows) handles the active session. Memory engines (next five rows) handle cross-session retrieval — and OpenClaw has only one memory plugin slot, so they generally don't stack with each other. Memory Wiki and Dreaming sit alongside the engines as separate plugins. Honcho's "9/10" rating in the table above for implicit preference tracking comes from community evaluation in OpenClaw issue #60572.
What the default memory actually does (and where it breaks)
OpenClaw's built-in memory splits your Markdown files (MEMORY.md, daily logs) into roughly 400-token chunks, embeds each chunk, and stores them in a local SQLite index. When you ask a question, it runs a semantic search over those chunks and returns the top results.
This works when the exact words you're searching for appear in the memory. It breaks in three specific ways.
Keyword misses. Out of the box, the default search leans on semantic similarity. The current builtin SQLite backend can do hybrid (keyword + vector) when you configure an embedding provider, but most new installs run pure vector search and the typical user never tunes it. If you stored "Docker configuration" but search for "container setup," the semantic match might still fail. Exact keyword matching would catch this. Without explicit hybrid configuration, you get one or the other, not both.
No cross-session recall. Once a conversation ends, the context fades unless the agent explicitly wrote something to a memory file. Information from old conversations that wasn't persisted is gone.
No relational understanding. The system stores text chunks. It doesn't understand that Alice manages the auth team, that the auth team handles permissions, and that you should ask Alice about permission issues. Those are three separate chunks that require reasoning to connect.
For the detailed explanation of how OpenClaw memory and compaction work, our compaction guide covers what happens to your context window during long conversations.
Built-in compaction (and Lossless Claw, the third-party LCM)
OpenClaw ships with default LLM-summarization compaction that manages your active conversation context. There's no formal product name for it in the docs — it's just "built-in compaction" or "default LLM summarization."
A third-party plugin called Lossless Claw (by Martian-Engineering, published as @martian-engineering/lossless-claw on npm) implements an LCM (Lossless Context Management) algorithm as a drop-in replacement. People sometimes refer to either by "LCM," which has caused confusion in the community.
What the compaction layer does: Compresses older messages in the conversation window to keep the context from overflowing. Preserves recent messages in full while summarizing older ones. Controls how much of the context window is used for conversation history versus system prompts and tool results.
What it doesn't do: Cross-session recall. Semantic search. Relationship understanding. Compaction manages the current conversation. It doesn't improve how the agent retrieves information from past conversations.
When to tune it: If your agent forgets things mid-conversation (within a single session), adjust freshTailCount (how many recent messages stay uncompressed) and contextThreshold (when compression triggers). The defaults work for most conversations. Long, complex sessions benefit from a higher freshTailCount (32 instead of the default).
Cost: Free. Built in. No additional API calls beyond the summarization model. Lossless Claw is also free, but is an optional install if the built-in compaction doesn't suit your workload.
Compaction manages the current session. QMD, Mem0, Cognee, Honcho, and LanceDB manage everything else. Don't compare compaction to the retrieval plugins. They work on different problems.
QMD: The hybrid search upgrade (start here)
QMD combines BM25 keyword search with vector semantic search and LLM reranking. It's the single biggest improvement you can make to OpenClaw's memory recall with the least setup effort.
What it does: Searches your Markdown memory files using both exact keyword matching (BM25) and semantic similarity (vectors), then uses an LLM to rerank results by relevance. This means "container setup" matches "Docker configuration" through semantic search while "CVE-2026-25253" matches through exact keywords. The combination catches queries that either approach alone would miss.
What it doesn't do: Automatic fact extraction. Relationship mapping. QMD searches your existing files better. It doesn't create new information or understand connections between facts.
Setup complexity: Low. QMD runs as a local-first search sidecar alongside OpenClaw — BM25, vector search, and reranking compiled into a single binary that OpenClaw manages as an external subprocess. Community benchmarks circulating in third-party guides cite recall accuracy jumping from roughly 45% (default SQLite) to 92% with QMD hybrid search (no primary benchmark has been published by the QMD authors). Setup takes about 5 minutes.
Cost: Free. Runs locally. No external API costs beyond the LLM reranking step (which uses your existing model provider).
Best for: Anyone who writes things down in memory files and wants better retrieval. This is the 80/20 solution. Biggest improvement, least effort.
For the complete guide to OpenClaw best practices including memory file organization, our practices guide covers how to structure memory files that QMD searches effectively.

Mem0: Automatic fact extraction (for people who hate writing notes)
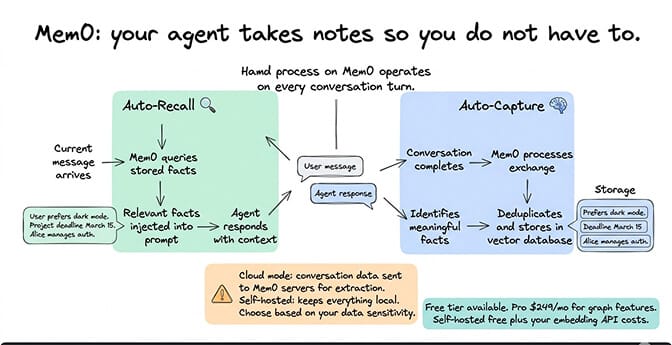
Mem0 watches your conversations, automatically extracts structured facts ("user prefers dark mode," "project deadline is March 15," "Alice manages auth"), deduplicates them, and stores them in a vector database. Before each response, it queries those stored facts and injects relevant ones into the prompt.
What it does: Two processes run on every conversation turn. Auto-Recall searches stored facts for anything relevant to the current message and injects them. Auto-Capture processes the conversation after each exchange, identifies meaningful facts, and stores them. You don't write MEMORY.md entries manually. The system does it for you.
What it doesn't do: Relationship reasoning. Mem0 stores individual facts. It doesn't build connections between them. It's a smart note-taker, not a knowledge graph.
Setup complexity: Low for cloud mode (30 seconds with an API key from app.mem0.ai). Moderate for self-hosted mode (requires configuring vector store and embedding provider). Cloud mode sends conversation data to Mem0's servers. Self-hosted mode keeps everything local.
Cost: Mem0 Cloud free tier available. Pro tier: $249/month for graph features. Self-hosted: free, requires your own embedding API costs.
Best for: Users who interact with OpenClaw conversationally across many sessions and don't want to manually curate memory files. Also strong for multi-user deployments where each user needs isolated memory (Mem0's userId namespace handles this natively).
The privacy trade-off: Mem0 Cloud sends your conversation data to external servers for extraction. If data privacy is a concern, use self-hosted mode or skip Mem0 entirely. The extraction process adds API costs because every conversation turn gets processed twice: once by your agent's model and once by Mem0's extraction model.
Cognee: Knowledge graph for relationship reasoning
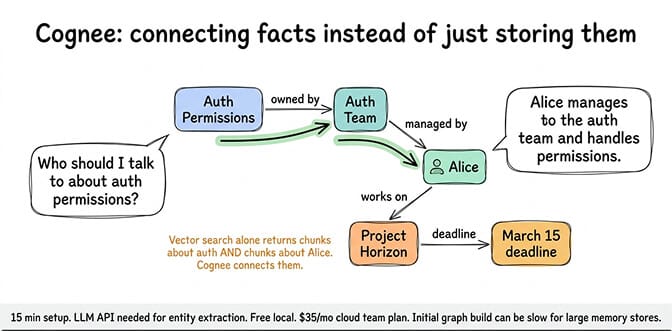
Cognee builds a knowledge graph from your Markdown memory files. Instead of searching for similar text, it extracts entities and relationships, then traverses the graph to answer queries that require connecting multiple facts.
What it does: On startup, scans your MEMORY.md and daily logs. Extracts entities (people, projects, teams, dates) and relationships between them. When you ask "who should I talk to about auth permissions?", Cognee traverses: Auth Permissions → Auth Team → Alice (manages). The agent gets structured context: "Alice manages the auth team and handles permissions." Vector search alone would return chunks about auth and chunks about Alice but might not connect them.
What it doesn't do: Keyword search. Simple text retrieval. Cognee is designed for relational queries, not "find the paragraph where I mentioned X." Use QMD for text retrieval and Cognee for relationship reasoning.
Setup complexity: Moderate. Takes about 15 minutes. Requires LLM API for entity extraction during indexing. The initial graph build processes all your memory files, which can be slow and costly for large memory stores.
Cost: Free for local deployment. Cognee Cloud Team plan is $200/month (2,500 docs / 2 GB / 10 users / 10K API calls) — the $35 figure that circulates online is the per-1,000-docs storage top-up, not the Team plan itself. The entity extraction process also uses LLM calls during indexing, adding ongoing API costs as memory files grow.
Best for: Teams managing complex, long-running projects where relationships between people, systems, and decisions matter. If you're tracking "who manages what, which team owns which system, and what was decided about X project three weeks ago," Cognee answers these queries that no other plugin handles well.
If managing memory plugins, retrieval tuning, and extraction costs feels like more infrastructure work than you want, Better Claw includes hybrid vector plus keyword search built into the platform. $19/month per agent, BYOK. The memory layer is pre-optimized. No plugins to install or configure.
Honcho: Cross-session user modeling (when "who you're talking to" matters)
Honcho is an AI-native memory system that builds a persistent user model over time. Where Mem0 captures discrete facts ("user prefers dark mode"), Honcho models the user — their preferences, drift over time, communication patterns, implicit signals — and exposes that as queryable context. The plugin (@honcho-ai/openclaw-honcho, repo at plastic-labs/openclaw-honcho) plugs into OpenClaw's memory slot.
What it does: Tracks observations across sessions, automatically builds user and agent models, semantic-searches past observations, and is aware of parent-agent relationships when sub-agents are involved.
What it doesn't do: It doesn't index your existing MEMORY.md files the way QMD does. It's about who the user is, not what's in the files. It also currently replaces other plugins in OpenClaw's single memory slot (more on that below) rather than complementing them.
Setup complexity: Moderate (~10 minutes). Install the plugin, configure the Honcho endpoint, run any migration tools the repo provides if you're moving from memory-core.
Cost: Free open-source. Honcho's hosted service has its own pricing.
Best for: Multi-user agents where each user needs an isolated, evolving model. Personal assistants where implicit-preference tracking matters. Community evaluation in OpenClaw issue #60572 ("Multi-Slot Memory Architecture") rated Honcho 9/10 on implicit preference detection with low false-inference rate and strong preference-drift tracking.
Memory LanceDB: Open-source vector store
Memory LanceDB (@openclaw/memory-lancedb on npm) is the official LanceDB-backed memory engine. Install it via openclaw plugins install @openclaw/memory-lancedb — it's not bundled into the OpenClaw runtime image even though it's labeled "official."
What it does: Stores memory in a LanceDB-backed vector database with auto-recall (search past observations on every turn) and auto-capture (write new facts from conversations into the store). Supports local Ollama embeddings, which means you can run the entire memory layer offline without sending data to a cloud embedding API.
What it doesn't do: No knowledge graph (use Cognee), no user modeling (use Honcho), no claim-level structured knowledge (use Memory Wiki).
Setup complexity: Low (~5 minutes). Plugin install + provider config.
Cost: Free. If you point it at Ollama for embeddings, there's no API cost at all. Otherwise the embedding provider you choose carries its usual rates.
Best for: Self-hosted setups that want Mem0-style auto-capture without sending data to a cloud service. Larger memory stores where SQLite starts to feel slow. A practical local-first alternative to Mem0 Cloud.
A note on the single-slot problem
OpenClaw currently exposes one memory plugin slot. Picking Honcho replaces the built-in memory. Picking Memory LanceDB replaces it too. This is the architectural reality the post's "they're not mutually exclusive" framing has to bend around: you can stack QMD (a sidecar) and Memory Wiki (a separate plugin) alongside a memory engine, but you can't run two memory engines simultaneously in the slot. OpenClaw issue #60572 proposes a multi-slot architecture (separate slots for recall, capture, user-modeling) to fix this; it's open and not yet implemented at time of writing.
Which one should you install first?
Here's the practical recommendation.
Most users: start with QMD. It requires the least setup (5 minutes), produces the biggest community-reported improvement in recall accuracy (the 45%→92% figure floating around online), runs locally with no external API costs, and works with your existing Markdown files without changing how you use OpenClaw. This is the 80/20 answer.
Add Memory Wiki and let Dreaming feed it. Memory Wiki (2026.4.7) gives you structured claims with provenance; Dreaming (2026.4.5) handles the persistence side automatically. The pair closes the "agent only remembers what gets written down" gap that retrieval plugins alone can't fix.
Pick one capture/modeling engine for the memory slot: Mem0 if you want hands-off fact capture (cloud or self-hosted), Honcho if you need cross-session user modeling (multi-user agents, implicit preferences), or Memory LanceDB if you want Mem0-style auto-capture entirely local with Ollama embeddings. You can only fill the memory slot with one of these at a time.
Add Cognee if relationships matter. If your work involves connecting people to projects, teams to systems, and decisions to timelines, Cognee's graph retrieval answers queries that text search can't. But it's overkill for personal assistant use cases.
Recommended stacks
- Beginner: built-in compaction + QMD. Five minutes of work, biggest practical jump in recall.
- Solo power user: QMD + Memory Wiki + Dreaming. Retrieval, structured durable facts, and automated consolidation.
- Privacy-first / offline: Memory LanceDB (with Ollama embeddings) + Memory Wiki + Dreaming. Everything local, no cloud calls.
- Multi-user agent: Honcho + QMD (sidecar coexists) + Dreaming. Per-user modeling on top of shared retrieval.
- Knowledge-graph-heavy team: QMD + Cognee + Memory Wiki + Dreaming. Text retrieval, relational reasoning, structured claims, and consolidation.
Start with the beginner stack. Add layers only when you hit a specific limitation. Don't install everything because you can — install the layer that fixes the problem you actually have.
The memory problem that plugins can't fix on their own
Retrieval plugins improve how the agent finds stored information. None of them fix the fundamental problem on their own: your agent only remembers what gets written down. If a fact from a conversation doesn't get persisted to a memory file, it's gone after the session ends. LCM can keep it in the active context for a while, but compaction eventually summarizes it away, and no retrieval plugin can find information that was never stored.
OpenClaw 2026.4.5 introduced Dreaming, an automated memory consolidation system with three phases (Light / Deep / REM) that closes part of this gap. Dreaming scores short-term signals from your sessions and promotes durable items into MEMORY.md automatically, so the persistence side of the equation no longer has to be entirely manual. Pair that with Memory Wiki (shipped in 2026.4.7), the structured-claims layer that sits alongside MEMORY.md, and you get persistence with provenance — see our Memory Wiki guide for the setup.
The best memory setup still combines a persistence strategy (manual notes, Mem0 capture, or Dreaming + Memory Wiki) with a retrieval strategy (QMD or Cognee). Both layers matter. Most people focus on retrieval and ignore persistence.
For the complete memory troubleshooting guide including how memory persistence interacts with your system prompt, our guide covers the persistence side of the equation.
If you want memory that works without installing and configuring plugins, give Better Claw a try. $19/month per agent, BYOK with 28+ providers. Hybrid vector plus keyword search is built into the platform. Persistent memory with automatic capture. No QMD setup, no Mem0 API keys, no Cognee graph builds. The memory layer just works.
Frequently Asked Questions
What are the main memory plugins for OpenClaw?
OpenClaw's current memory landscape spans compaction (built-in summarization, plus the third-party Lossless Claw LCM plugin), retrieval engines (built-in SQLite, QMD sidecar, Memory LanceDB, Honcho, Mem0, Cognee), and the structured-knowledge layer (Memory Wiki, with Dreaming feeding it). Compaction handles the active session; the rest improve cross-session memory in different ways. OpenClaw has only one memory plugin slot, so you pick one engine, but QMD (sidecar) and Memory Wiki can sit alongside whatever engine you choose.
Which OpenClaw memory plugin should I install first?
QMD. It requires the least setup (5 minutes), produces the biggest community-reported improvement in recall accuracy (the 45%→92% figure cited in community benchmarks, no primary source published), runs locally with no external API costs, and works with your existing Markdown files. Start with QMD and only add Mem0 (auto fact capture), Honcho (per-user modeling), or Cognee (relational reasoning) when you hit specific limitations QMD doesn't address.
How much do OpenClaw memory plugins cost?
QMD: free, runs locally as a sidecar. Mem0 Cloud: free tier, Pro tier $249/month for graph features. Mem0 self-hosted: free, requires your own embedding API costs. Cognee local: free, requires LLM API for entity extraction. Cognee Cloud Team: $200/month. Honcho: free open-source. Memory LanceDB: free open-source plugin. Built-in compaction (and the third-party Lossless Claw LCM plugin): free. The hidden cost with Mem0 and Cognee is ongoing API consumption — both run LLM calls for extraction, doubling the per-turn token cost.
Can I use multiple OpenClaw memory plugins at the same time?
Yes. QMD and Cognee can run together (QMD handles text retrieval, Cognee handles relational queries). Mem0 can run alongside either. The Markdown files remain the shared foundation across all plugins. The tradeoff is token overhead: each retrieval system injects context into the prompt before every response, increasing input tokens and API costs.
Does BetterClaw include memory plugins?
BetterClaw includes hybrid vector plus keyword search (similar to QMD's approach) built into the platform with no plugin installation required. Persistent memory with automatic capture is part of the managed infrastructure. If you want Cognee's knowledge graph or Mem0's specific extraction features, those would need to be configured separately. For most users, BetterClaw's built-in memory handles the 80% use case without plugin management.
Related Reading
- OpenClaw Memory Fix Guide — Memory loss, OOM crashes, and the persistence problem
- OpenClaw Memory Compaction Explained — How LCM manages your active context window
- OpenClaw Session Length Is Costing You Money — How memory size affects your API bill
- The OpenClaw SOUL.md Guide — How system prompts interact with memory retrieval
- OpenClaw API Costs: What You'll Actually Pay — The cost impact of stacking memory plugins



