The best free model for OpenClaw is Gemini 2.5 Flash on Google AI Studio's free tier — 1,500 requests per day, no credit card required, with a 1M-token context window and reliable tool calling. For higher quality at near-zero cost, DeepSeek V4-Flash is the next pick. For privacy or offline work, Ollama with gemma4:e4b (lightweight) or qwen3.5:9b (sweet spot) runs free forever on a 16GB machine.
Update (May 19, 2026): Anthropic banned Claude Pro/Max subscriptions from third-party tools like OpenClaw on April 4, 2026, then reversed the ban on May 13, 2026. Claude usage in OpenClaw will resume on June 15, 2026 via a new "Agent SDK credit" system — monthly non-rollover credits ($20-$200, billed at API rates) attached to paid Claude plans. Between now and then, the free-model picks below are still the working path. After June 15, you'll have more options, and we'll update this post when the dust settles.
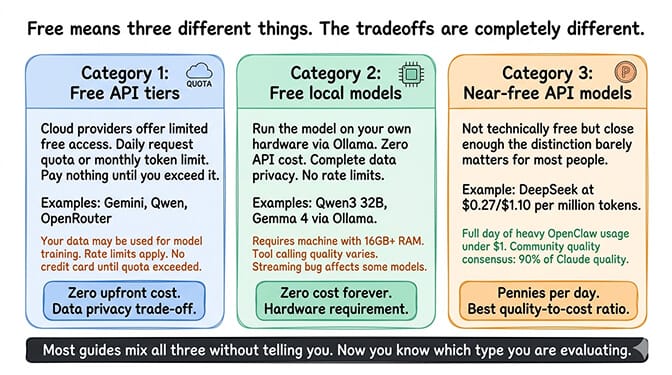
"Free" means three different things in the AI model world: free API tiers with rate limits and potential data training, free local models that require your own hardware, and near-free API models that cost pennies but aren't actually zero. I tested all three categories. Here's what works, what doesn't, and where the traps are.
The three categories of "free" (this matters)
Category 1: Free API tiers. Cloud providers offer limited free access. You get a quota (daily requests or monthly tokens), pay nothing until you exceed it, and your data may be used for model training. Gemini, Qwen, and OpenRouter fall here.
Category 2: Free local models. You run the model on your own hardware via Ollama. Zero API cost. Complete data privacy. But you need a machine with 16GB+ RAM for usable models, and tool calling quality varies significantly.
Category 3: Near-free API models. DeepSeek V4-Flash at $0.14/$0.28 per million tokens (the legacy V3 endpoint is being deprecated July 24, 2026 and now routes to V4-Flash). Not technically free, but a full day of heavy OpenClaw usage stays well under $1. Close enough to free that the distinction barely matters for most people.
Most "best free model" guides mix all three without telling you. The tradeoffs are completely different. If you want the full ranked roster rather than the top picks, our list of free models that actually work with OpenClaw covers seven providers with daily limits and quality scores.
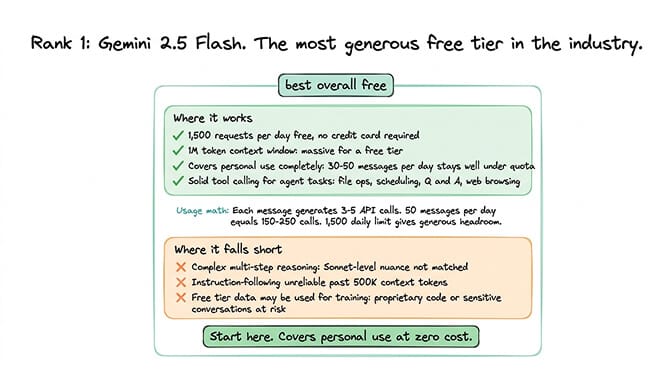
1. Gemini 2.5 Flash (best free API tier overall)
Google's free tier is the most generous in the industry. 1,500 requests per day. No credit card required. A massive 1M token context window. Solid tool calling for agent tasks.
For a personal OpenClaw agent doing 30-50 messages per day, the free tier covers your entire usage. You'd need to send 50+ messages daily before hitting the 1,500 request ceiling, and each message generates 3-5 API calls (reasoning, tool use, response).
Where it works
Simple agent tasks. File operations. Scheduling. Q&A. Web browsing. The quality is competitive with GPT-4o-mini for routine work.
Where it falls short
Complex multi-step reasoning. Creative writing quality. Instruction-following gets unreliable past 500K tokens in the context window. If your tasks require Sonnet-level nuance, Flash won't match it.
The catch
Free tier data may be used for training. If you're processing proprietary code or sensitive conversations, this matters. Use the paid API or run local instead.
For the full model-by-model comparison including paid options, our model guide covers the complete roster.
2. Qwen 3 via OAuth (deprecated — read before you set it up)
For most of 2026, OpenClaw's bundled qwen-portal-auth plugin used an OAuth device-code flow against Qwen's portal to grant ~2,000 free requests/day — particularly attractive for multilingual workloads (Chinese, Japanese, Korean). That free tier was discontinued on April 15, 2026 (OpenClaw GitHub issue #49557). Server-side restrictions now block the OAuth method, even on existing tokens.
What to use instead
If multilingual quality is what brought you here, the best free path is now Qwen via paid API key (Alibaba Cloud Model Studio or DashScope — token costs are competitive with DeepSeek) or running a Qwen model locally via Ollama. qwen3.5:9b runs comfortably on 16GB Macs and handles Chinese/Japanese/Korean well; qwen3-coder:30b is the heavyweight pick for 24GB+ machines. See the Ollama section below for the local-setup details.
The catch
If you find older guides telling you to enable the qwen-portal-auth plugin and run the device-code login, they pre-date the April 15 deprecation. Don't waste the setup time — the OAuth flow returns a 401 even after a successful login.

3. DeepSeek V4-Flash (best quality, technically not free)
DeepSeek hands new accounts a one-time 5 million-token free credit (valid roughly 30 days), then switches to pay-as-you-go on V4-Flash at $0.14 / $0.28 per million tokens (input/output). A full day of heavy OpenClaw usage still lands well under $1 even at peak. The legacy deepseek-chat/deepseek-reasoner (V3) endpoints are scheduled for full deprecation on July 24, 2026 and currently route to V4-Flash internally — point new configs at V4-Flash directly.
This is the quality pick. Community consensus puts DeepSeek's current Flash tier at roughly 90% of Claude Sonnet / GPT-5.3 Instant quality for everyday tasks — email drafting, research summaries, brainstorming, code review. For most workloads you'll barely notice the difference from models costing 10x more.
Where it works
Nearly everything. DeepSeek's quality-to-cost ratio is the best in the market. It's the default recommendation from multiple community guides for a reason.
Where it falls short
Occasional latency spikes during peak hours. Tier-1 RPM limits can interrupt high-volume workflows. For complex reasoning tasks that require Opus-level depth, V4-Flash won't match the premium models — that's what V4-Pro (75% off through May 31, 2026) is for.
The catch
The 5M-token free credit is one-time, not monthly. Once it's gone, you're on pay-as-you-go — still cheap, but you do need a credit card on file. For the cheapest providers including current DeepSeek pricing, our cost guide covers the specifics.

4. Ollama local models (free forever, hardware required)
Running models locally via Ollama costs nothing per token. Your data never leaves your machine. Complete privacy. No rate limits. No quota.
Sizing matters more than people expect. A 32B model in q4 quantization actually needs ~19-20 GB of VRAM/RAM, not 16GB — so the realistic 16GB-Mac picks are qwen3.5:9b or gemma4:e4b (both released in 2026, both tool-calling-capable). If you have 24GB+ unified memory or VRAM, step up to qwen3-coder:30b or glm-4.7-flash (~19GB at q4). For agent workflows specifically, the community-favorite combo on a 32GB+ machine is qwen3-coder:30b for code and glm-4.7-flash for reasoning.
The setup is one command on Ollama 0.17+:
ollama launch openclaw --model gemma4:e4b # or qwen3.5:9b
Where it works
Privacy-sensitive workflows. High-volume tasks where API costs add up. Offline operation. Development and testing.
Where it falls short
The legacy /v1 OpenAI-compatible endpoint drops tool calls under streaming — use OpenClaw's native Ollama provider (baseUrl: http://127.0.0.1:11434, no /v1) and tool calls work. Small local models (under 7B parameters) generally can't call tools reliably even with the correct provider. For the troubleshooting guide on local model tool calling, our Ollama guide covers which models work and which don't.

5. OpenRouter
OpenRouter aggregates models from multiple providers. Some models have a :free suffix that routes to free endpoints. Llama 3.2 3B and others are available at zero cost through OpenRouter.
Where it works
Experimentation. Trying different models without creating accounts with each provider. One API key, many models.
Where it falls short
Free model availability changes without notice. Quality of free endpoints varies. Queue times during peak hours can make the agent feel slow. The free models on OpenRouter are generally the smallest and least capable versions.

The models we'd skip (with caveats)
A few free options come up in community threads but tend to disappoint for OpenClaw-style agent work. Two of these are "softer" calls — your mileage may vary, especially as the models keep updating.
GLM-5.1 / GLM-5 Turbo
Z.ai's GLM-5 family (GLM-5 in February, GLM-5-Turbo in March, GLM-5.1 in late March 2026) is technically capable — GLM-5.1 actually tops some coding benchmarks. But community reports from OpenClaw-style agent workflows are mixed: thinking-loop behavior on GLM-5, occasional gibberish output, sometimes both. We'd test on your specific workload before relying on it — our 30-day GLM 5.1 OpenClaw review is exactly that test on a real production agent. The earlier glm-4.7-flash (the OpenClaw community favorite for local agent runs) doesn't have the same complaints — if you want a GLM-family model, that's the safer pick.
Kimi free tier
Kimi K2's free tier is roughly 1,000 requests/day with a 300k token/day rate limit, and billing includes input + output + cached tokens. Community reports of "burning a month's quota in a day" tend to be heavy multi-turn agent sessions where context replays add up fast. It can work for low-volume work; for agent loops with long context, expect to hit limits quickly.
Any local model under 7B parameters
Tool calling is unreliable or nonexistent at this size — the agent will describe tasks instead of executing them. If you're going local, go 8B+ (qwen3.5:9b or gemma4:e4b are the floor) or stick with a cloud free tier. For an honest look at the strongest local Qwen option, our Qwen 3.7 and Ollama review covers what runs locally today and what doesn't.
Start with Gemini 2.5 Flash free tier. It covers personal use with zero cost. When you outgrow it, switch to DeepSeek V4-Flash at near-zero cost. Only go local (Ollama) if data privacy is a hard requirement and you have the hardware.
Which free model is right for you?
| Use case | Privacy needed? | Hardware available? | Pick |
|---|---|---|---|
| Personal assistant, low volume | No | No | Gemini 2.5 Flash (1,500 req/day free) |
| High quality, budget-conscious | No | No | DeepSeek V4-Flash (5M one-time + $0.14/$0.28 per M tokens) |
| Sensitive data, privacy-first | Yes | Yes (24GB+) | Ollama + qwen3-coder:30b or glm-4.7-flash |
| 16GB Mac, privacy or offline | Yes | 16GB | Ollama + gemma4:e4b or qwen3.5:9b |
| Multilingual (CJK) | No | No | Paid Qwen via DashScope (free OAuth deprecated April 15) |
| Model experimentation | No | No | OpenRouter :free |
Quick-start configs
Setup snippets for the top three picks:
# Gemini 2.5 Flash — get an API key at ai.google.dev
export GOOGLE_API_KEY="your_gemini_key"
# In OpenClaw config, set provider: gemini, model: gemini-2.5-flash
# DeepSeek V4-Flash — sign up at platform.deepseek.com
export DEEPSEEK_API_KEY="your_deepseek_key"
# In OpenClaw config, set provider: deepseek, model: deepseek-v4-flash
# Ollama local (Ollama 0.17+, one command auto-configures OpenClaw)
ollama launch openclaw --model gemma4:e4b # or qwen3.5:9b on 16GB; qwen3-coder:30b on 24GB+
Full Ollama configuration (provider block, native /api/chat path, context window) is covered in our OpenClaw Ollama guide.
If the model configuration, provider setup, and free tier management feels like more work than you want, BetterClaw supports 28+ model providers from a dropdown. Free plan with 1 agent and BYOK. $49/month for Pro. Smart context management means you use fewer tokens per interaction regardless of which model you choose, which stretches free tiers further.

The uncomfortable truth about free models
Free models work for personal use, learning, and experimentation. They struggle on business-critical agent deployments where response quality, reliability, and uptime matter. The quality gap between Gemini Flash free and Claude Sonnet 4.6 is real; so is the reliability gap between a rate-limited free tier and a paid tier with guaranteed capacity; so is the privacy gap between a free tier that may train on your data and a paid API that doesn't. Most people who start on free models end up on DeepSeek V4-Flash (near-free) or Sonnet/Haiku (mid-tier) within a month because the quality-to-cost ratio at those price points is dramatically better than zero.
If you're evaluating OpenClaw agents and want to start free, give BetterClaw's free tier a try. 1 agent, BYOK (bring your Gemini or DeepSeek key), hosting included. No credit card. Your first deploy takes 60 seconds. If and when you're ready for Pro, it's $49/month for Pro with full access. Start free. Upgrade when the agent is worth it to you.
Frequently Asked Questions
What is the best free model for OpenClaw?
Gemini 2.5 Flash via Google AI Studio. It offers 1,500 free requests per day (no credit card required), a 1M-token context window, and reliable tool calling. It covers personal OpenClaw usage (30-50 messages/day) completely within the free tier. For higher quality at near-zero cost once you outgrow Flash, DeepSeek V4-Flash is the next pick.
What happened to Claude on OpenClaw?
Anthropic banned Claude Pro/Max subscriptions from third-party tools like OpenClaw on April 4, 2026. The ban was reversed on May 13, 2026 — a new "Agent SDK credit" system (monthly non-rollover credits billed at API rates) will reinstate Claude usage on paid plans starting June 15, 2026. Until then, the free-tier picks in this post are the working path.
Can I run OpenClaw completely free?
Yes, in two ways. First, use a free API tier (Gemini 2.5 Flash gives 1,500 requests/day free). Second, run models locally via Ollama — gemma4:e4b or qwen3.5:9b run on a 16GB machine, larger models like qwen3-coder:30b and glm-4.7-flash need 24GB+. The trade-offs: free API tiers have rate limits and may train on your data; local models require hardware and benefit from the native /api/chat Ollama provider for working tool calling.
Which free models support tool calling in OpenClaw?
Cloud free tiers: Gemini 2.5 Flash, DeepSeek V4-Flash, OpenRouter :free. Local via Ollama (use the native provider, not /v1): qwen3-coder:30b, glm-4.7-flash, qwen3.5:9b, gemma4:e4b, hermes3, mistral:7b, gpt-oss:20b. Models under 8B parameters generally cannot call tools reliably regardless of provider config.
Is DeepSeek actually free for OpenClaw?
Partially. DeepSeek hands new accounts a one-time 5 million-token free credit (valid ~30 days), not a recurring monthly free tier. After it's gone, V4-Flash bills at $0.14 / $0.28 per million tokens (input / output). A heavy day of OpenClaw usage typically lands well under $1. Most personal users stay under $5/month total. Functionally near-free, but not zero cost after the initial credit.
Does BetterClaw support free models?
Yes. BetterClaw's free plan includes 1 agent with BYOK (bring your own API key). You can connect your Gemini free tier key, DeepSeek key, or any of 28+ supported providers. BetterClaw charges for the platform ($49/month for Pro), not for inference. You pay your model provider directly at their rates, including free tiers. Smart context management stretches free-tier quotas further by keeping per-turn token volume lean.