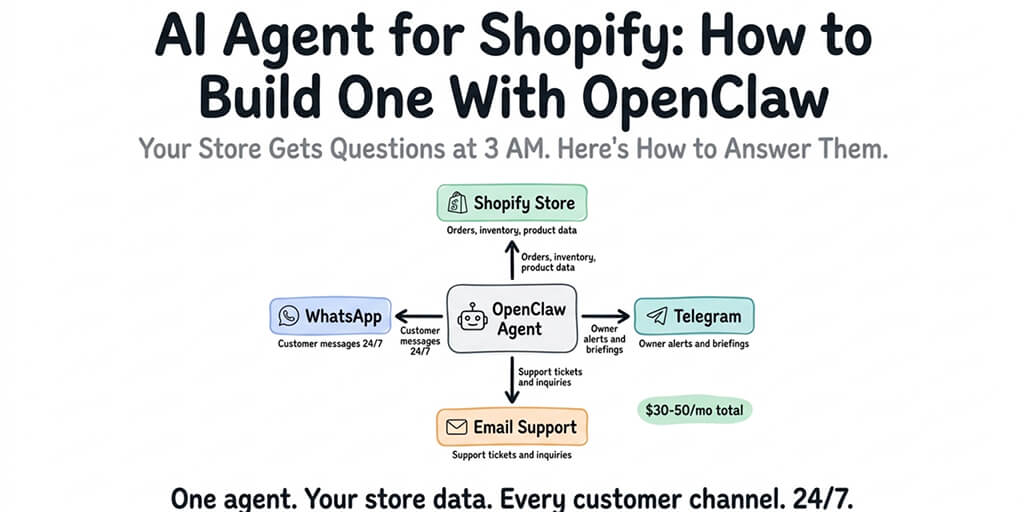
Five agents running 24/7. Email triage, meeting prep, expense tracking, content research, Slack digest. Total monthly cost: somewhere between $0 and $19. Here's the exact stack, the models, the platform, and where the money goes.
My API bill last month was $3.42. Five agents. Running every day. Email classification, morning briefing, expense tracking, content research, and a Slack digest that fires at 6 PM.
The month before, the same five agents cost $87. Same tasks. Same output quality. Same reliability. The only difference: I stopped using Claude Sonnet for everything and started using the right model for each task.
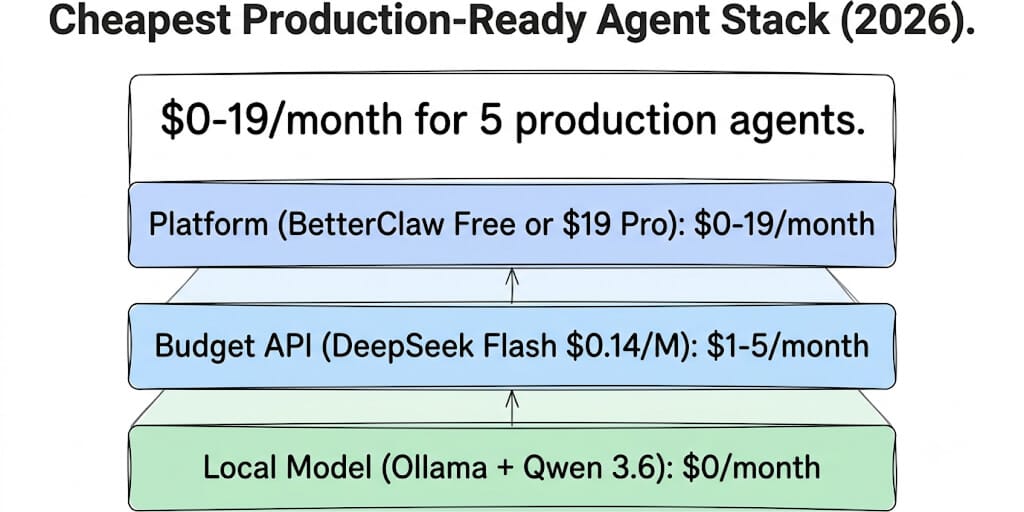
Here's the cheapest production-ready agent stack you can build in 2026, broken down by layer.
Layer 1: The local model (cost: $0)
Ollama + Qwen 3.6 35B-A3B. Runs on 16 GB Apple Silicon or any machine with 16+ GB RAM. Apache 2.0. Zero per-token cost. 25-35 tok/s.
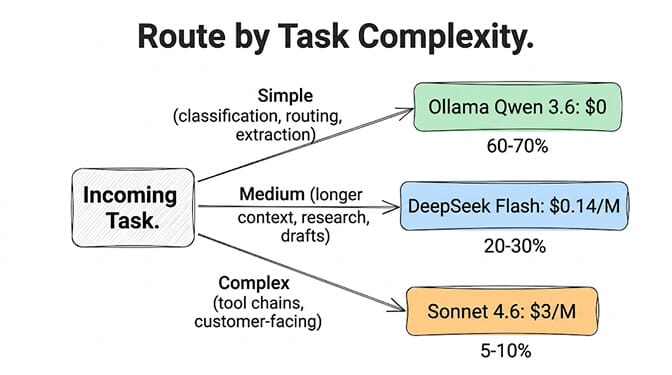
This handles 60-70% of your agent's tasks. Classification. Routing. Simple extraction. Summarization. Intent detection. Anything with structured input, structured output, and tolerance for occasional errors.
# Install
curl -fsSL https://ollama.com/install.sh | sh
# Pull the model
ollama pull qwen3.6:35b-a3b
# Enable on boot (Linux)
sudo systemctl enable ollama
Why Qwen 3.6 specifically? It's the sweet spot for agents. MoE architecture (3B active parameters from 35B total) means it's fast on modest hardware. Tool calling works with thinking mode disabled. 128K context on the full model. Apache 2.0 license. For the complete Ollama setup and Modelfile configuration, see our dedicated Ollama setup guide.
Alternatives at this tier: Gemma 4 12B (multimodal, great for image tasks), Phi-4-mini (3.8B, runs on 4 GB VRAM, built-in function calling).
Layer 2: The budget cloud API (cost: $1-5/month)
DeepSeek V4 Flash at $0.14/M input, $0.28/M output. For the 20-30% of tasks that need more context, better reasoning, or faster throughput than your local model provides.
At 200 tasks per day averaging 5K tokens each: $4.20/month. At 50 tasks per day: $1.05/month.
Flash handles the tasks that need longer context than your local model provides, or where you need cloud reliability (no laptop sleep, no connection errors). Meeting prep with 10-page calendar context. Expense extraction from long email threads. Research summarization from multiple sources.
When to upgrade from Flash: If your agent needs complex multi-step tool chains (Flash hallucinates tools at ~12-15%), step up to MiniMax M3 at $0.60/M or GLM 5.2 at $1.40/M. Still far cheaper than Sonnet's $3/M.
Layer 3: The platform (cost: $0-19/month)
You need something to orchestrate the agents, manage model connections, schedule tasks, and handle integrations. Three options at this price point.
Option A: BetterClaw Free ($0/month)
1 agent, 100 tasks/month, every feature, 7-day memory. BYOK required (bring your own API keys). No credit card. This is enough for a single personal agent doing 3-4 tasks per day.
Option B: BetterClaw Pro ($19/month per agent)
Unlimited tasks, hourly scheduling, all 15+ chat platforms (Telegram, Slack, WhatsApp, Discord, Teams), $5 managed LLM credits, priority support. For 5 agents: $95/month ($76/month annual). But if you're optimizing for the absolute cheapest stack, run 1 Pro agent that handles multiple task types via routing.
Option C: Self-hosted framework ($0/month, your time)
OpenClaw or Hermes on your own machine. Free, but you manage Docker, YAML, updates, security patches, and every connection error yourself. CrowdStrike's security advisory on OpenClaw and the 1,400 malicious skills on ClawHub are worth reading before going this route.
The complete stack (copy this)
| Layer | Choice | Monthly Cost |
|---|---|---|
| Local model | Ollama + Qwen 3.6 35B-A3B | $0 |
| Cloud API (budget) | DeepSeek V4 Flash ($0.14/M) | $1-5 |
| Cloud API (quality) | Sonnet 4.6 ($3/M, 5-10% of tasks) | $2-8 |
| Platform | BetterClaw Free or Pro | $0-19 |
| Hardware | Existing laptop/desktop (16 GB+) | $0 (already own) |
| Total | $3-32/month |
The $0 version: Ollama locally for everything + BetterClaw Free. 1 agent, 100 tasks, zero dollars. Good for personal use.
The $19 version: 1 BetterClaw Pro agent with model routing. Qwen 3.6 locally for classification. Flash for medium tasks. Sonnet for the 5-10% that need precision. Unlimited tasks.
The $3-5 version: Self-hosted framework + Ollama locally + Flash for overflow. Zero platform cost, but you spend hours on infrastructure instead of agent logic.
The cheapest production agent stack in 2026 isn't about finding the cheapest model. It's about routing each task to the cheapest model that's good enough for that specific task. Most tasks need a $0 local model. Some need a $0.14/M API. Very few need $3/M.
The 5 agents that run on this stack
Agent 1: Email triage ($0/month, local)
Reads incoming emails. Classifies into 5 categories (support, sales, billing, technical, spam). Routes to the right team member or auto-archives. Runs on Qwen 3.6 locally. 500 emails/day capacity.
Agent 2: Morning briefing ($0-1/month, local + Flash)
Reads calendar for the day. Pulls relevant email threads. Generates a 3-paragraph briefing delivered to Slack at 7 AM. Calendar summary runs locally. Email context uses Flash for longer threads.
Agent 3: Expense tracking ($0.50/month, Flash)
Scans Gmail for receipts. Extracts vendor, amount, category, date. Adds to a Google Sheet. Flash at $0.14/M handles the extraction. 10-20 receipts per week: under $0.50/month.
Agent 4: Content research ($1-3/month, Flash + Sonnet)
Researches a topic across multiple sources. Produces a structured summary with key findings, quotes (paraphrased), and source list. Flash for initial research. Sonnet for the final synthesis on high-quality pieces.
Agent 5: Slack digest ($0/month, local)
Summarizes the day's Slack activity into a channel-by-channel digest. Posted at 6 PM. Runs entirely on Qwen 3.6 locally. Pure summarization task, no tools needed.
Total for all five: $1.50-4.50/month in API costs + $0-19/month in platform costs.
For the full build guide on each of these agents, see our personal agent use cases.
If you want all five agents running through one dashboard without managing Ollama configs, API keys, and model routing manually, BetterClaw handles the orchestration. Free plan with 1 agent and every feature. $19/month per agent on Pro. BYOK with zero inference markup across 28+ providers.
What "production-ready" actually means at this price
Let's be honest about the tradeoffs.
What you get: Agents that run daily, handle structured tasks, save you 2-3 hours per day, and cost less than a coffee subscription.
What you don't get: 99.9% uptime SLA. Automatic failover. Enterprise audit logs. Customer-facing quality on every output. The local model will occasionally crash when your laptop sleeps. Flash will occasionally hallucinate a tool call. Your 5 PM digest might arrive at 5:03 PM.
"Production-ready" at this price means: Good enough for personal and internal team use. Not good enough for customer-facing production at scale. For that, you need managed hosting, premium models, and monitoring. The gap between $19/month and enterprise-grade is the gap between "works for me" and "works for 10,000 customers."
Gartner projects 40% of enterprise applications will embed AI agents by end of 2026. Most of those will start exactly where this stack sits: small, cheap, personal, proving the value before scaling up.
Give BetterClaw a look if you want to start with the cheapest stack and scale up when you're ready. Free plan with 1 agent and every feature. $19/month per agent for Pro. Enterprise pricing when you need SSO, audit logs, and SLAs. We handle the infrastructure at every tier. You handle the agent logic.
Frequently Asked Questions
What is the cheapest way to run AI agents in 2026?
The cheapest production-ready agent stack costs $0-19/month: Ollama with Qwen 3.6 locally ($0 per token), DeepSeek V4 Flash for overflow ($0.14/M, $1-5/month for typical personal use), and BetterClaw Free ($0) or Pro ($19/month). Five personal agents (email triage, morning briefing, expense tracking, content research, Slack digest) run on this stack for $1.50-4.50/month in API costs plus platform fees.
Can I run production agents for free?
Yes, with limitations. Ollama + Qwen 3.6 on your own hardware costs $0/token. BetterClaw's free plan gives you 1 agent, 100 tasks/month, and every feature with no credit card. The tradeoffs: local inference stops when your laptop sleeps, you're limited to open-weight models (no Claude or GPT-5.5), and 100 tasks/month caps your volume. For truly free unlimited use, self-host OpenClaw or Hermes with Ollama, accepting the infrastructure maintenance cost.
Which local model is best for the cheapest agent stack?
Qwen 3.6 35B-A3B is the current sweet spot. MoE architecture (3B active from 35B total) runs at 25-35 tok/s on 16 GB hardware. Apache 2.0 license. Tool calling works (disable thinking mode). 128K context. Alternatives: Gemma 4 12B for multimodal tasks (image/audio/video), Phi-4-mini (3.8B) for ultra-lightweight deployment on 4 GB hardware with built-in function calling.
How does this compare to running everything on Claude Sonnet?
Five agents on Sonnet at 500 total tasks/day costs approximately $56-87/month in API fees alone (plus platform costs). The same five agents on the cheapest stack cost $1.50-4.50/month in API fees. The quality tradeoff: Sonnet has 3% tool hallucination vs Qwen 3.6's ~8-10% and Flash's ~12-15%. For personal and internal agents where occasional errors are acceptable, the 10-20x cost savings justify the quality gap. For customer-facing agents, Sonnet's reliability premium is worth paying.
What hardware do I need for local inference?
Any machine with 16 GB RAM runs Qwen 3.6 35B-A3B at Q4 quantization. Apple Silicon Macs (M1/M2/M3/M4 with 16 GB) are the sweet spot: 25-35 tok/s, silent, low power. NVIDIA RTX 3060 (12 GB) or RTX 4060 (8-16 GB) work on Linux/Windows. For Phi-4-mini (3.8B), even 8 GB RAM is sufficient. No special hardware purchase needed if your existing laptop or desktop meets these specs.