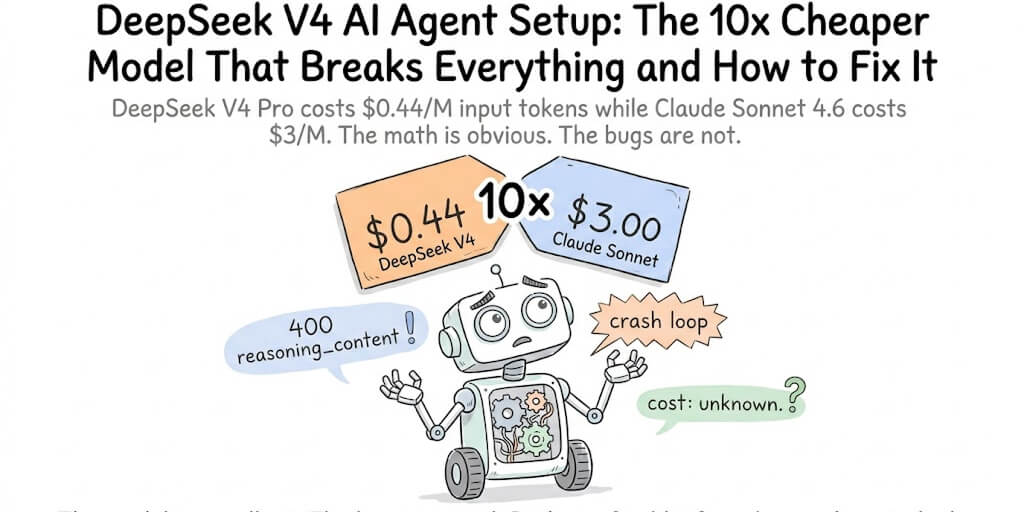
DeepSeek V4 Pro costs $0.44/M input tokens while Claude Sonnet 4.6 costs $3/M. The math is obvious. The bugs are not. Here's every issue we've found, with GitHub numbers and working fixes.
The Slack message came in at 11 PM on a Tuesday. One of our community members had just switched their OpenClaw agent from Claude Sonnet 4.6 to DeepSeek V4 Pro. The reasoning was simple: why pay $3 per million input tokens when you can pay $0.44?
The agent worked for exactly one turn. Then it crashed. Tried again. Crashed again. Reset the session. The second turn threw a 400 error about reasoning_content not being passed back.
"Is the model broken or am I broken?"
Neither. DeepSeek V4 is legitimately one of the best models for AI agents in 2026. The bugs are real, documented, and fixable. You just need to know where they are before you hit them at 11 PM on a Tuesday.
This is the DeepSeek V4 AI agent setup guide that should have existed a month ago.
The pricing that makes you double-check your calculator
Let me put the numbers in front of you, because they're almost hard to believe.
DeepSeek V4 Pro (75% promo through May 31, 2026): Input: $0.435/M tokens (cache miss). Output: $0.87/M tokens. Cache hits: $0.003625/M tokens.
DeepSeek V4 Flash: Input: $0.14/M tokens. Output: $0.28/M tokens. Cache hits: $0.0028/M tokens.
For comparison: Claude Sonnet 4.6: $3/M input, $15/M output. GPT-4.1: $2.50/M input, $10/M output. GPT-5.5: $30/M input (reasoning).
V4 Pro is roughly 7x cheaper than Claude Sonnet on input and 17x cheaper on output. V4 Flash is roughly 21x cheaper on input and 54x cheaper on output.
And these aren't small models. V4 Pro scores 81% on SWE-bench Verified. 1M token context window. 384K max output. Both OpenAI-compatible and Anthropic-compatible API endpoints.
DeepSeek's explicit goal is rock-bottom pricing, backed by Huawei Ascend and Cambricon chips. They're not competing on margin. They're competing on volume by making their API too cheap to ignore.
Every new account gets 5 million free tokens. No credit card required.

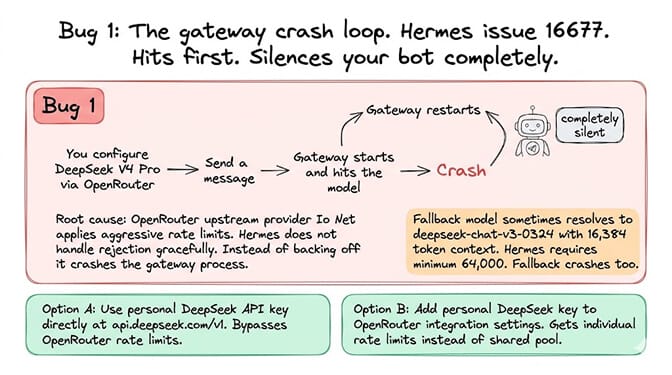
Bug #1: The gateway crash loop (Hermes, issue #16677)
This is the P1 that hits first. If you configure DeepSeek V4 Pro via OpenRouter as your default model in Hermes Agent, the gateway enters a crash loop that kills your Telegram bot and every other messaging integration.
What happens: You set model.default: deepseek/deepseek-v4-pro with model.provider: openrouter. You send a message. The gateway starts, hits the model, and crashes. Restarts. Crashes again. Your bot goes completely silent.
Root cause: The OpenRouter upstream provider "Io Net" applies aggressive rate limits to DeepSeek V4 Pro. When the rate limit hits, Hermes doesn't handle the rejection gracefully. Instead of backing off and retrying, it crashes the gateway process.
A secondary failure: the fallback model sometimes resolves to deepseek/deepseek-chat-v3-0324, which has a 16,384 token context window. Hermes requires minimum 64,000. So the fallback crashes too.
The fix:
Option A: Use a personal DeepSeek API key directly instead of routing through OpenRouter. Add your key at the DeepSeek developer portal, then configure Hermes to use api.deepseek.com/v1 as the base URL.
# In your Hermes config
model:
default: deepseek-v4-pro
provider: custom
base_url: https://api.deepseek.com/v1
api_key: sk-your-deepseek-key
Option B: Add your personal DeepSeek API key to OpenRouter's integration settings. This gives you individual rate limits instead of the shared pool.
For a broader look at how different providers handle rate limiting across agent frameworks, our guide on reducing OpenClaw API costs covers provider-specific optimization strategies.
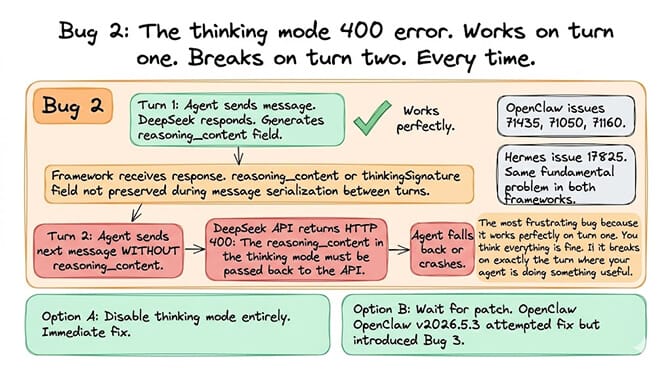
Bug #2: The thinking mode 400 error (both frameworks, multiple issues)
This one is sneakier. Your agent works fine on the first turn. You feel great. You saved 10x on costs. Then the second turn hits, and everything breaks.
What happens: The DeepSeek API returns HTTP 400: "The reasoning_content in the thinking mode must be passed back to the API."
Root cause: DeepSeek V4's thinking mode generates a reasoning_content field in its response. The API requires this field to be sent back verbatim in the next request. Both Hermes and OpenClaw fail to properly preserve and replay this field across conversation turns.
In OpenClaw (issue #71435, #71050, #71160): The thinkingSignature property gets lost during message serialization between turns. When the signature is undefined, the passback is silently skipped, and DeepSeek rejects the request.
In Hermes (issue #17825): Same fundamental problem. The reasoning_content from prior assistant turns gets dropped during session reload, so the second turn always fails.
The fix:
Option A: Disable thinking mode entirely. This is the simplest workaround.
For OpenClaw:
# In your OpenClaw config
agents:
defaults:
thinkingDefault: "off"
For Hermes, set thinking mode to disabled in your model configuration.
Option B: Wait for the patch. Both frameworks are tracking fixes. OpenClaw's v2026.5.3 attempted a fix via the openrouter/thinking-policy.ts extension, but introduced a new bug where reasoning_effort values don't match OpenRouter's accepted values (issue #77350).
The thinking mode bug is the most frustrating because it works perfectly on turn one. You think everything is fine. Then it breaks on exactly the turn where your agent is doing something useful.
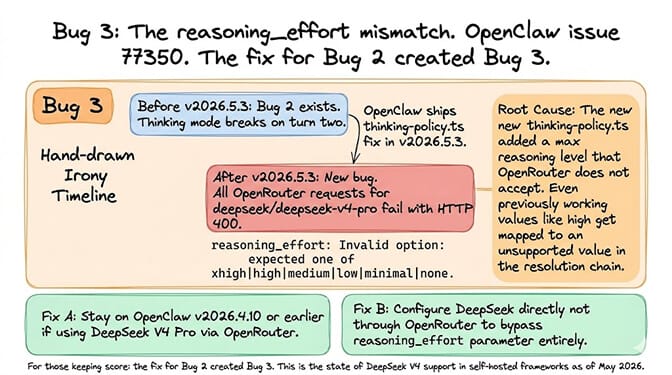
Bug #3: The reasoning_effort mismatch (OpenClaw, issue #77350)
This one appeared after OpenClaw tried to fix Bug #2.
What happens: After upgrading to OpenClaw v2026.5.3, all OpenRouter requests for deepseek/deepseek-v4-pro fail with HTTP 400: "reasoning_effort: Invalid option: expected one of xhigh|high|medium|low|minimal|none."
Root cause: OpenClaw's new thinking-policy.ts extension added a max reasoning effort level that OpenRouter doesn't accept. Somewhere in the resolution chain, the configured value (even high, which previously worked) gets mapped to an unsupported value.
The fix: Stay on OpenClaw v2026.4.10 or earlier if you're using DeepSeek V4 Pro via OpenRouter. Alternatively, configure DeepSeek directly (not through OpenRouter) to bypass the reasoning_effort parameter entirely.
For those keeping score: the fix for Bug #2 created Bug #3. This is the state of DeepSeek V4 support in self-hosted agent frameworks as of May 2026.
If you're looking at these three bugs and thinking "I just want to use DeepSeek V4 without debugging framework internals"... that's a completely reasonable reaction. BetterClaw supports DeepSeek V4 (and 28+ other providers) via BYOK. You paste your API key, select the model from a dropdown, and your agent runs. No gateway config. No thinking mode serialization bugs. No reasoning_effort mismatches. The platform handles provider compatibility so you don't have to. Free plan, $19/month for Pro.
The cost comparison that actually matters
Let me model what DeepSeek V4 Pro costs for a real agent workload versus the alternatives.
Scenario: Customer support agent handling 200 tickets/day. Average 2,000 input tokens + 1,000 output tokens per ticket. 50% cache hit rate.
DeepSeek V4 Pro (promo): ~$0.09/day. $2.70/month. DeepSeek V4 Flash: ~$0.03/day. $0.90/month. Claude Sonnet 4.6: ~$1.20/day. $36/month. GPT-4.1: ~$1.00/day. $30/month.
Add self-hosting costs: VPS: $20-50/month. Your time debugging: priceless (or $50-100/hr if you bill it).
BetterClaw with DeepSeek V4 BYOK: LLM cost: $2.70/month. Platform: $0 (free plan) or $19/month (Pro). Total: $2.70 to $21.70/month. No VPS. No debugging.
The LLM cost savings from DeepSeek are real. But they evaporate if you spend 4 hours debugging thinking mode serialization at your hourly rate.
For a deeper comparison of total cost across the OpenClaw ecosystem, our hidden OpenClaw costs breakdown covers heartbeat expenses, token overhead, and infrastructure costs that don't show up on the API bill.

What DeepSeek V4 actually does well for agents
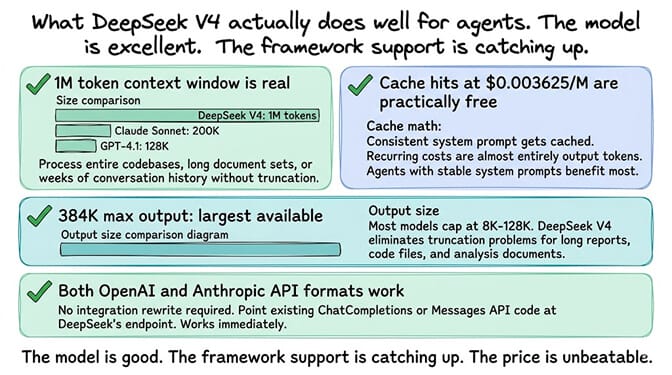
Despite the bugs, the model itself is excellent for agent workloads. Let me be specific about what works.
The 1M context window is real. Most models cap at 128K or 200K. DeepSeek V4's 1M window means your agent can process entire codebases, long document sets, or weeks of conversation history without truncation.
Cache hits at $0.003625/M are practically free. If your agent uses a consistent system prompt (and it should), that prompt gets cached. Your recurring costs are almost entirely output tokens.
384K max output is the largest available. For agents that generate long reports, code files, or analysis documents, this eliminates the truncation problem that plagues shorter output limits.
Both OpenAI and Anthropic API formats work. You don't need to rewrite your integration. If your existing code talks to the OpenAI ChatCompletions API or the Anthropic Messages API, point it at DeepSeek's endpoint and it works.
The model is good. The framework support is catching up. The price is unbeatable. That's the honest assessment.
For a broader look at which models work best for different agent use cases, our best AI models for autonomous agents guide covers the full spectrum from budget to premium.
The practical setup (when you're ready)
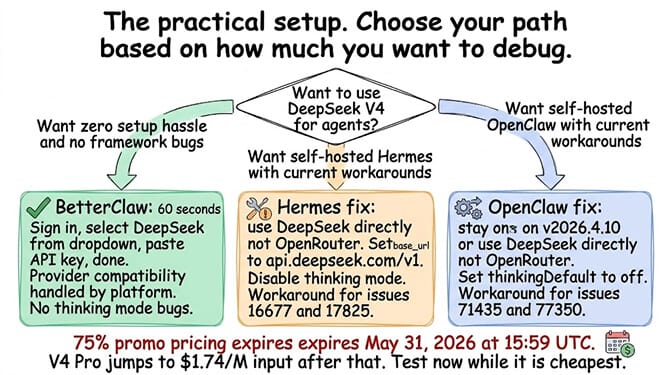
On BetterClaw: Sign in. Go to agent settings. Select "DeepSeek" as your provider. Choose "DeepSeek V4 Pro" from the model dropdown. Paste your API key. Done. 60 seconds.
On Hermes (workaround for current bugs):
# Use DeepSeek directly, NOT through OpenRouter
hermes config set model.default deepseek-v4-pro
hermes config set model.provider custom
hermes config set model.base_url https://api.deepseek.com/v1
hermes config set model.api_key sk-your-key
# Disable thinking mode until the passback bug is fixed
hermes config set model.thinking off
On OpenClaw (workaround for current bugs):
# Stay on v2026.4.10 or use DeepSeek directly
model:
provider: deepseek
model: deepseek-v4-pro
apiKey: sk-your-key
agents:
defaults:
thinkingDefault: "off"
Important: The 75% promo pricing expires May 31, 2026 at 15:59 UTC. After that, V4 Pro jumps to $1.74/M input and $3.48/M output. Still competitive, but 4x higher than the promo rate. If you're evaluating DeepSeek for agent workloads, test now while it's cheapest.
The bottom line on DeepSeek V4 for agents
DeepSeek V4 is the cheapest capable model for AI agents in 2026. Period. The 1M context, 384K output, and sub-dollar-per-million pricing make it the obvious choice for cost-conscious deployments.
The bugs are real but bounded. Disable thinking mode and avoid OpenRouter rate limits, and you'll have a stable, absurdly cheap agent backend. The framework fixes are coming. The model itself isn't the problem.
If any of this resonated, give BetterClaw a look. Free plan with 1 agent and every feature. $19/month per agent for Pro. DeepSeek V4, Claude, GPT, Gemini, Mistral... 28+ providers, zero markup, one dropdown. Your first deploy takes about 60 seconds. We handle the provider compatibility. You handle the interesting part.
Frequently Asked Questions
Can you use DeepSeek V4 for AI agents?
Yes. DeepSeek V4 Pro and V4 Flash both work with AI agent frameworks including Hermes, OpenClaw, and BetterClaw. The model supports tool calling, 1M token context windows, and both OpenAI and Anthropic API formats. However, as of May 2026, there are known bugs with thinking mode in multi-turn conversations on both Hermes and OpenClaw. Disabling thinking mode resolves the issue.
How does DeepSeek V4 Pro compare to Claude Sonnet 4.6 for agents?
DeepSeek V4 Pro is roughly 7x cheaper on input ($0.435/M vs $3/M) and 17x cheaper on output ($0.87/M vs $15/M) during the promo period through May 31, 2026. Claude Sonnet 4.6 has better thinking mode stability and more mature framework support. DeepSeek V4 Pro has a larger context window (1M vs 200K) and larger max output (384K vs 128K). For cost-sensitive workloads where thinking mode isn't critical, DeepSeek V4 is the better value.
How do I set up DeepSeek V4 Pro with Hermes Agent?
Use DeepSeek's API directly (not via OpenRouter) to avoid the gateway crash loop (issue #16677). Set model.provider: custom, model.base_url: https://api.deepseek.com/v1, and model.api_key to your DeepSeek key. Disable thinking mode until the reasoning_content passback bug (issue #17825) is fixed. This gives you stable multi-turn conversations at DeepSeek's direct pricing.
How much does DeepSeek V4 cost for AI agent workloads?
At promo pricing (through May 31, 2026): V4 Pro is $0.435/M input and $0.87/M output. V4 Flash is $0.14/M input and $0.28/M output. Cache hits are $0.003625/M (Pro) and $0.0028/M (Flash). A customer support agent handling 200 tickets/day costs roughly $2.70/month on V4 Pro or $0.90/month on V4 Flash. After the promo, V4 Pro rises to $1.74/M input and $3.48/M output. On BetterClaw, you pay DeepSeek directly (BYOK, zero markup) plus $0 (free plan) or $19/month (Pro).
Is DeepSeek V4 reliable enough for production AI agents?
The model itself is reliable. The framework integration has known bugs as of May 2026: thinking mode fails on multi-turn tool calls (Hermes #17825, OpenClaw #71435, #71050), and OpenRouter routing can crash Hermes's gateway (#16677). With thinking mode disabled and direct API access (not OpenRouter), production stability is solid. BetterClaw handles all provider compatibility internally, so these framework-level bugs don't affect managed deployments.