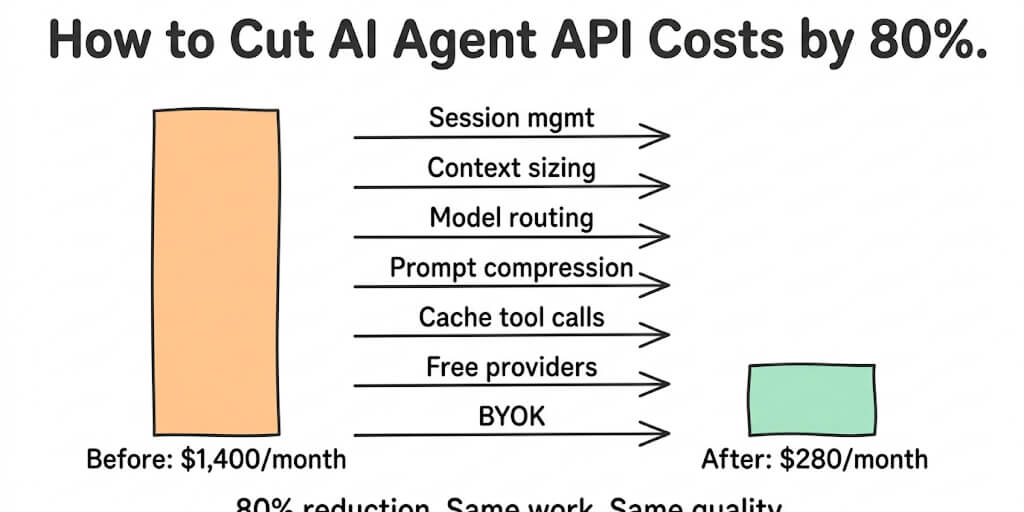
Our agent API bill was $1,400 last month. This month it's $280. Same agents. Same tasks. Same output quality. Here are the seven changes that got us there.
I opened our OpenAI dashboard on a Tuesday morning and felt my stomach drop. $47 in API costs. For one day. On one agent.
The agent was a support ticket classifier. It reads incoming emails, categorizes them, and routes them to the right team. Simple work. Should cost pennies.
But when I looked at the token breakdown, the math was obvious. The agent was re-reading its entire 12,000-token system prompt on every single request. It was loading all 15 tool definitions (another 8,000 tokens) whether or not it needed them. And it was running on Claude Sonnet for a task that DeepSeek Flash handles identically.
$47/day was not the cost of doing the work. It was the cost of doing the work badly.
Seven changes later, the same agent costs $4/day. Here's every optimization, with real dollar examples.
1. Session length management (the #1 hidden cost)
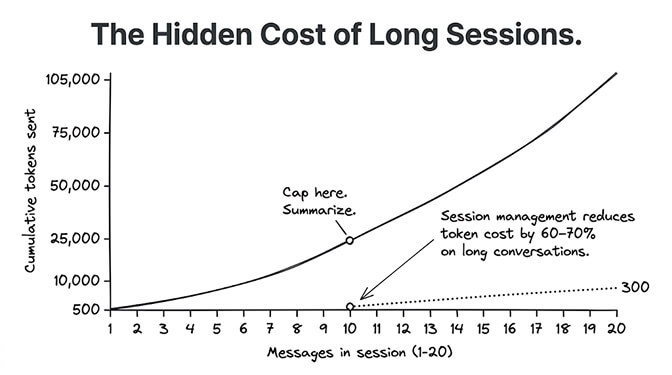
Here's what nobody tells you about AI agent API costs: the biggest expense isn't the work your agent does. It's the context it carries while doing it.
Every message in a conversation gets re-sent with every new request. Message 1 gets sent once. Message 2 gets sent with message 1. Message 3 gets sent with messages 1 and 2. By message 20, the agent is re-reading 19 previous messages plus your system prompt plus all tool definitions. Every. Single. Request.
A 20-message conversation where each message averages 500 tokens doesn't cost 10,000 tokens total. It costs approximately 105,000 tokens (the triangular sum). On Claude Sonnet at $3/M, that's $0.315 for one conversation. Run 500 conversations per day and you're at $157/day.
The fix: Cap sessions. After 10 messages, summarize the conversation and start a new session with the summary as context. The summary costs 200-300 tokens instead of 5,000+ tokens of raw history.
Dollar impact: One team cut their daily API bill from $180 to $60 with session management alone. That's the single biggest lever most people miss.
2. Context window right-sizing (stop overpaying for headroom)
Your agent probably runs with a context window larger than it needs. If you've set num_ctx 131072 on Ollama or maxed out your context window on an API call, you're paying for capacity your agent never uses.
Most agent tasks (email triage, classification, CRM updates, short responses) need 8,000-16,000 tokens of effective context. Setting a 128K window doesn't cost tokens directly on APIs (you pay per token used, not per token available). But it enables behavior bloat: the agent fills the space. Tool responses get longer. Conversation histories grow. The model generates more verbose output because it "knows" it has room.
The fix: Set explicit limits on tool response length, conversation history retention, and output length. num_predict 1024 on Ollama caps output. On APIs, set max_tokens to the minimum needed for each task type. Classification: 50 tokens. Email draft: 500 tokens. Report: 2,000 tokens.
Dollar impact: Reducing average output from 800 tokens to 300 tokens (for tasks that don't need 800) saves 62% on output costs. On Sonnet at $15/M output: $12/day → $4.56/day for 1,000 tasks.
3. Model routing (the biggest percentage drop)
This is the optimization that delivers the largest single reduction. Run simple tasks on cheap models. Run complex tasks on expensive models. Route between them automatically.
The three-tier approach:
Tier 1 (65% of tasks): Classification, extraction, routing, formatting. DeepSeek V4 Flash at $0.14/M. Or GLM 5.2 at $1.40/M. Or MiniMax M3 at $0.60/M.
Tier 2 (25% of tasks): Drafting, analysis, summarization. Claude Sonnet at $3/M.
Tier 3 (10% of tasks): Complex reasoning, judgment calls, safety-critical decisions. Opus 4.8 at $5/M.
Dollar impact: Without routing (all Sonnet): $1,800/month on 1,000 tasks/day. With routing: $770/month. $1,030/month saved (57%). The classifier prompt itself costs about $0.03/day.
The single highest-impact optimization for AI agent costs is model routing. 65% of typical agent tasks produce identical output on a model that costs 21x less than Sonnet. Don't pay $3/M for work that $0.14/M handles identically. Our model routing setup guide covers the implementation.
4. Prompt compression (the Caveman approach)
Your agent's output is probably 60% filler. "Certainly! I'd be happy to help you with that. Let me walk you through the changes step by step..." That preamble costs money. Every token of it.
The Caveman skill pattern forces terse output. No pleasantries. No step-by-step explanations unless requested. Maximum information density.
Without compression: 300-500 tokens per response. With compression: 80-150 tokens. Over 30 exchanges: 9,000-12,000 tokens saved.
Dollar impact: At Sonnet rates, compression saves approximately $0.15 per 30-message session. At 100 sessions/day: $15/day or $450/month. Not the biggest lever by itself, but it compounds with everything else.
5. Caching repeated tool calls (the 90% discount)

If your agent sends the same system prompt and tool definitions with every request, you're re-paying for context the provider already has.
Anthropic prompt caching: 90% discount on cached tokens. Your 12,000-token system prompt costs $0.036 the first time and $0.0036 on every subsequent request in the same session. Over 100 requests: $0.036 + ($0.0036 × 99) = $0.39 instead of $3.60 without caching. 89% cheaper.
OpenAI automatic caching: 50% discount on repeated prefixes. No configuration needed.
Google caching: 75% discount with a small storage fee.
The gotcha: Caching works when the prefix is identical. If you change one word in your system prompt, the cache invalidates. Structure your prompts with a stable prefix (system instructions, tool definitions) and a variable suffix (conversation history, user message).
Dollar impact: On an agent that makes 500+ API calls per day with a stable system prompt, caching alone saves 40-60% on input costs. Our prompt caching cost savings guide covers the setup for each provider.
6. Free providers for non-critical tasks (stop paying for testing)
Your development and testing workflow probably runs on the same provider as production. Every test prompt, every debug run, every "let me try a different system prompt" iteration costs production-rate tokens.
The fix: Use free providers for development, testing, and non-critical tasks.
- Z.ai (GLM 5.2): Free tier for testing. Strong coding and classification performance.
- Groq: Free tier. 30K TPM, 30 RPM, no credit card. 500+ tok/s speed.
- Google AI Studio (Gemini): Free tier with generous limits.
- DeepSeek: Free credits on signup.
Dollar impact: If 20% of your API calls are development/testing, routing those to free providers saves 20% of your total bill. On a $500/month bill, that's $100/month for zero work.
On BetterClaw, BYOK means you connect any provider's API key and pay them directly. 28+ providers supported. Zero inference markup. Use Groq for testing, Sonnet for production, and switch with a dropdown. Free plan with every feature. $19/month per agent on Pro.
7. BYOK cost visibility vs platform markup (the invisible tax)
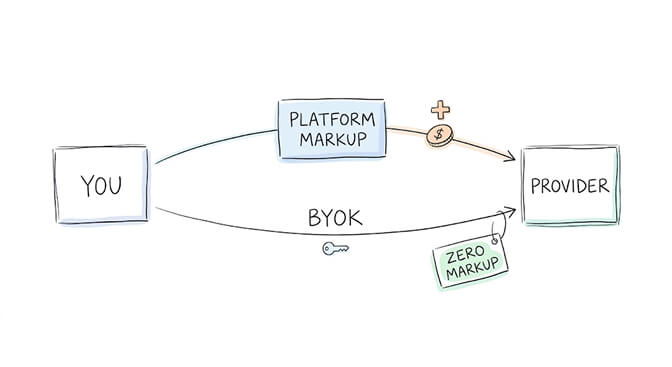
Here's the cost nobody puts on their comparison table: platform markup on inference.
Many AI agent platforms add a margin on top of the model provider's pricing. You pay $3/M for Sonnet, but the platform charges you $4-5/M. The extra $1-2/M is invisible unless you compare your platform bill against the provider's published rates.
The fix: Use BYOK (Bring Your Own Key). You bring an API key from the provider (Anthropic, OpenAI, Google, whoever). You pay the provider directly at their published rates. The platform charges for the platform, not for your tokens.
Dollar impact: If your platform adds a 30% markup on inference and you spend $500/month on tokens, you're paying $150/month in hidden markup. BYOK eliminates this entirely.
BetterClaw charges $0-19/month for the platform and adds zero markup on inference. Your tokens, your keys, your provider's published rates. Per-agent cost caps ensure you never exceed your budget. The $19/month platform cost is predictable. The token cost is transparent.
The compound effect (why 80% is real)
These seven changes don't just add up. They compound.
Session management: 30-40% reduction. Context right-sizing: 10-15% on top. Model routing: 50-60% on remaining costs. Prompt compression: 15-20% on output. Caching: 40-60% on input. Free providers: 20% of dev/test costs eliminated. BYOK: 20-30% markup eliminated.
Applied together on a $1,400/month bill:
Session management → $910. Model routing → $400. Caching → $240. Compression + right-sizing + free providers → $280.
$1,400 → $280. 80% reduction. Same agents. Same tasks. Same output quality. Different engineering.
Gartner projects 40% of enterprise applications will embed AI agents by end of 2026. The teams that hit the wall won't be the ones who couldn't build agents. They'll be the ones who couldn't afford to run them. Token economics is not optimization. It's survival.
Give BetterClaw a look if you want cost controls built in from the start. BYOK with zero markup. Per-agent cost caps. Smart context management. Free plan with 1 agent and every feature. $19/month per agent for Pro. We handle the infrastructure and the cost controls. You handle the agent logic.
Frequently Asked Questions
How much does it cost to run an AI agent per month?
A typical AI agent costs $10-100/month in API tokens depending on the model, volume, and optimization level. Before optimization: an agent processing 500 tasks/day on Claude Sonnet costs approximately $450/month. After applying all seven optimizations (session management, model routing, caching, compression, right-sizing, free providers for dev, BYOK): the same agent costs approximately $90/month. Platform costs are separate: BetterClaw is $0 (free) or $19/month (Pro).
What's the fastest way to reduce AI agent API costs?
Model routing delivers the biggest single reduction. Route 65% of simple tasks (classification, extraction, routing) to DeepSeek V4 Flash at $0.14/M instead of Claude Sonnet at $3/M. That's a 21x cost reduction on those tasks with identical accuracy. Combined with Anthropic's 90% prompt caching discount on repeated system prompts, these two changes alone cut costs by 50-60%.
Does reducing costs affect agent output quality?
Not when done correctly. Model routing sends each task to a model capable of handling it. Simple tasks produce identical results on cheap models. Prompt compression removes filler, not content. Caching reduces cost without changing the prompt. The only optimization that risks quality is aggressive context right-sizing. Start conservative and validate output before reducing further.
What is BYOK and why does it save money?
BYOK (Bring Your Own Key) means you connect your own API key from model providers (Anthropic, OpenAI, Google, etc.) and pay them directly at their published rates. Many agent platforms add a 20-30% markup on inference costs. On a $500/month token bill, that's $100-150/month in hidden markup. BetterClaw uses BYOK with zero inference markup. You pay the provider's price, nothing more.
How do I set a spending cap on my AI agent?
On BetterClaw, per-agent cost caps let you set a hard monthly limit. If the agent hits the cap, it pauses automatically. No surprise bills. On self-hosted setups, implement spending limits at the API key level (most providers support this) or add middleware that tracks token consumption and blocks requests above a threshold. The model routing setup guide covers implementation details.