

Three model families, three bets on where the agent economy is going, and one honest answer about which one belongs in your agent.
Three model releases in six weeks.
Claude Sonnet 4.6 on February 17. MiniMax M2.7 on March 18. GLM 5.1 open-sourced on April 7. Each one claiming agentic coding crown. Each one priced very differently. Each one attractive to run inside OpenClaw.
So which one actually belongs in your agent?
That's the question behind "best LLM for OpenClaw" and it doesn't have one answer. It has three, depending on what you're building, what you're optimizing for, and how much you want to spend every month to keep your agent thinking.
The three models, stripped to what matters
Let me skip the marketing paragraphs and give you the numbers that actually change decisions.
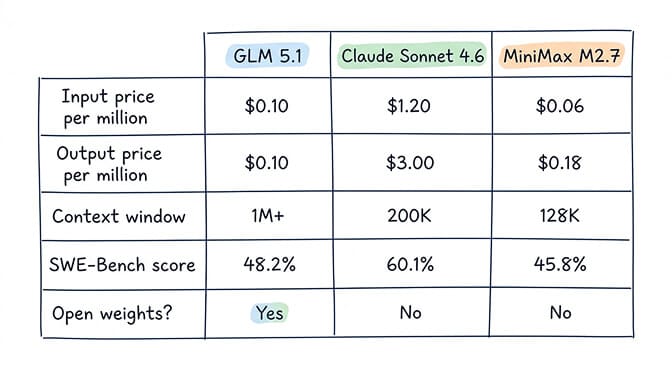
Claude Sonnet 4.6. Released February 17, 2026. $3 per million input tokens, $15 per million output. 1 million token context window at standard pricing since March 14. 79.6% on SWE-bench Verified. Closed weights, API only. Anthropic's mid-tier that made Opus feel overpriced for most workloads.
GLM 5.1. Open-weights release on April 7, 2026. $1 per million input, $3.20 per million output. 200K token context window. 58.4 on SWE-Bench Pro, officially ahead of Claude Opus 4.6 at 57.3 on that specific benchmark. 744B parameter Mixture-of-Experts, 40B active per token, trained entirely on Huawei Ascend 910B chips with no Nvidia involvement. MIT licensed weights on Hugging Face.
MiniMax M2.7. Released March 18, 2026. $0.30 per million input, $1.20 per million output. 200K context window. 56.2% on SWE-Pro, 57.0% on Terminal Bench 2. Open weights under a non-commercial license, so self-hosting commercially needs a separate agreement. Built specifically for long-horizon agent workflows.
Three wildly different positions in the market. One of them is about 10x cheaper than another. One of them you can run on your own hardware. One of them is the safe default if you just want the thing to work.
Why model choice matters more in OpenClaw than in a chat app
Here's what I see people get wrong. They pick a model for their agent the same way they'd pick one for ChatGPT. "Which is smartest" or "which is cheapest."
OpenClaw is different. Your agent is not answering one question. It's looping. Reading tool outputs, deciding what to do next, calling another tool, reading that output, deciding again. A single user request can trigger 20 or 30 model calls internally.
That changes the math. A model that's 10% more reliable cuts your retry loops. A model that's 5x cheaper per token becomes massively cheaper per completed task. A model with a bigger context window lets your agent carry more state across steps without resorting to memory summarization hacks.
For chat apps, pick the smartest model you can afford. For agents, pick the one that finishes the most tasks per dollar.
The question isn't "which LLM is best." The question is "best LLM for OpenClaw specifically." Because the answer actually differs.
Claude Sonnet 4.6: the default nobody gets fired for picking
If your agent is doing anything customer-facing, anything that touches production code, anything where a bad response has real-world consequences, Sonnet 4.6 is the boring correct answer.
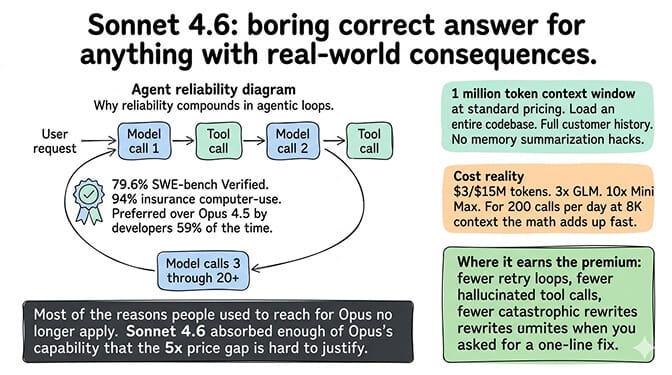
79.6% on SWE-bench Verified. 94% on insurance computer-use benchmarks. In Claude Code testing, developers preferred Sonnet 4.6 over the previous Opus 4.5 flagship 59% of the time. That's a mid-tier model beating the last generation's flagship in coding preference.
The 1 million token context window, now at standard pricing across the full window, is the feature that actually matters for agents. You can load an entire codebase, a full customer history, a day's worth of support tickets, and the model still tracks what it's doing. No fragile memory summarization. No "please remind me what we were working on."
The cost is the cost. $3/$15 per million tokens is 3x Sonnet's price compared to GLM, 10x compared to MiniMax. For an agent doing 200 model calls a day with 8K context each, that adds up fast.
Where Sonnet 4.6 earns its premium: reliability. Fewer retry loops. Fewer hallucinated tool calls. Fewer "I've refactored the entire codebase" when you asked for a one-line fix.
If you've been comparing Sonnet vs Opus for OpenClaw workloads, most of the reasons people used to reach for Opus no longer apply. Sonnet 4.6 absorbed enough of Opus's capability that the 5x price gap is hard to justify outside of a narrow set of deep reasoning tasks.
GLM 5.1: the open-source model that finally showed up
This is the interesting one.
GLM 5.1 is the first open-weights model that's credibly competitive with the top closed-source options on a serious agentic coding benchmark. Not approximately. Actually ahead. 58.4 vs Claude Opus 4.6's 57.3 on SWE-Bench Pro. On the broader coding composite that includes Terminal-Bench 2.0 and NL2Repo, Opus still leads at 57.5 vs 54.9. But that's one benchmark point of separation on a composite, which is close enough to matter.
At $1/$3.20 per million tokens through Z.ai's API, it's roughly 3x cheaper than Sonnet. If you run it on your own hardware under the MIT license, your marginal cost per token is just electricity.
Where GLM 5.1 shines: long-horizon autonomous coding. Z.ai demonstrated it running for eight hours straight on a single task, completing 655 iterations autonomously. That's exactly the profile of a production OpenClaw agent that needs to handle a multi-step workflow without human babysitting — we put that claim to the test in our 30-day GLM 5.1 OpenClaw review.
Where GLM 5.1 is still finding its footing: raw speed (44.3 tokens per second is slow by 2026 standards), and the fact that all of this was trained on Huawei Ascend chips with zero Nvidia hardware, which is a geopolitically loaded signal some teams will care about and others won't.
The thing that made me sit up: Z.ai explicitly called out compatibility with OpenClaw in their release documentation. This is a model designed with agent frameworks in mind, not retrofitted afterward.
If you've been running a production OpenClaw agent on Sonnet and watching your API bill climb, GLM 5.1 is the first credible alternative that doesn't force you to downgrade on capability. Pair it with the smart model routing pattern to route cheap calls through GLM and reserve Sonnet for the hard cases, and your cost curve bends sharply.

MiniMax M2.7: the dark horse for long-context agent work
MiniMax doesn't get as much airtime as the other two, but for a specific class of OpenClaw workloads it's the most interesting option on the board.
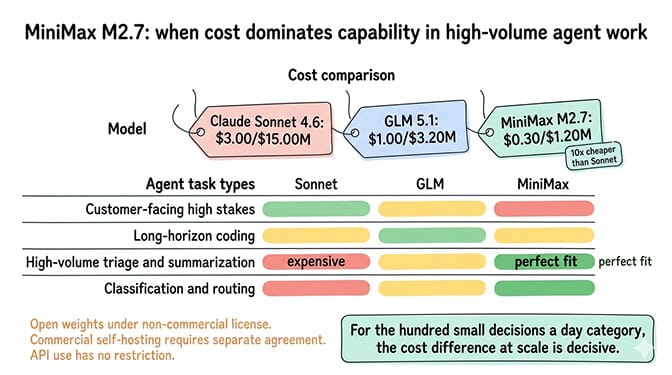
At $0.30/$1.20 per million tokens, it's the cheapest of the three by a wide margin. Roughly 10x cheaper than Sonnet. Roughly 3x cheaper than GLM 5.1. A 200K context window, decent benchmark performance (56.2% on SWE-Pro, 57.0% on Terminal Bench 2), and explicit design focus on autonomous agent workflows.
The catch: the open weights are released under a non-commercial license. If you want to self-host it for a commercial product, you need to negotiate a separate agreement with MiniMax. For API use, no restriction.
Where M2.7 fits: high-volume agent work where cost dominates capability. Support ticket triage. Log summarization. Content moderation. The "a hundred small decisions a day" category where you don't need Opus-class reasoning and you really don't want to pay for it.
If you're building an OpenClaw agent that needs to run constantly and cheaply, M2.7 through an API is hard to beat on dollar-per-token economics. Our deep dive on MiniMax M2.7 for OpenClaw breaks down exactly which tasks hold up at 10% of Claude's cost and which ones don't.
The routing answer nobody wants to hear
If you've read this far, you've probably already figured out where this is going.
You don't pick one.
Production OpenClaw agents in 2026 should route between models based on task type. Sonnet 4.6 for anything customer-facing or consequential. GLM 5.1 for long-horizon coding and autonomous workflows where cost matters. MiniMax M2.7 for high-volume cheap decisions that just need to be right often enough.
This is the pattern every mature agent deployment I've seen is converging on. Single-model agents are going the way of single-database applications. They work, but they're leaving money and capability on the table.
If you want model routing wired up without having to build the routing logic yourself, BetterClaw handles multi-model OpenClaw deployments with 28+ providers and per-task routing baked in. $49/month for Pro, BYOK, and you can swap models per skill without touching YAML.
The self-hosting math for GLM 5.1
GLM 5.1 is the only one of the three you can actually run on your own hardware under a permissive license. That's a real option, and the math deserves its own section.
The model has 744B total parameters with 40B active. Inference requires serious GPU memory (realistically you're looking at multi-GPU setups to run it at full precision, FP8 quantized versions cut that roughly in half). If you're running at low volume, cloud API at $1/$3.20 per million tokens will be cheaper than owning the hardware. If you're running at high volume, the math flips around maybe 500M to 1B tokens a month.
The bigger hidden cost is operational. Self-hosting GLM 5.1 means you're now maintaining vLLM or SGLang deployments, handling model updates, managing quantization tradeoffs, and debugging your own inference stack. The trap of hidden infrastructure costs on OpenClaw deployments applies here too. Self-hosting a frontier model isn't free. It's a bet that your engineering time is cheaper than API margin.
For most teams, the right answer is GLM 5.1 via API, not self-hosted. For teams already running GPU infrastructure at scale, the calculus changes. If you'd rather not pay for any tokens at all to start, our guide to the best free model for OpenClaw covers the zero-cost paths before you commit to a paid tier.
What I'd actually pick tomorrow
If I had to build one new OpenClaw agent tomorrow, I'd pick based on what the agent does.
Customer-facing agent handling real conversations with real stakes: Sonnet 4.6. The reliability premium is worth it.
Internal dev tool, code review, long-running engineering tasks: GLM 5.1 via Z.ai API. Best price-to-capability ratio on coding, and the 8-hour autonomous run capability is genuinely useful for long-horizon work.
High-volume triage, classification, summarization, routing: MiniMax M2.7 via API. The cost difference at scale is decisive.
Multi-purpose agent doing all three: all three, routed by task. Cheap for triage, GLM for long coding sessions, Sonnet for anything the user sees.
One last thing
Two years ago, "which LLM should I use" was a one-model question. Today it's a portfolio question. The teams that figure out model routing as a core architecture concern, not an afterthought, are going to run agents 30-50% cheaper than the teams still picking one provider and sticking to it.
The other thing to sit with: the open-weights story is real now. GLM 5.1 beating Claude Opus 4.6 on a serious coding benchmark, trained on domestic Chinese hardware with no Nvidia involvement, released under MIT license, and explicitly OpenClaw-compatible? That's not a niche story. That's the shape of the next two years of agent infrastructure.
If you've been running one model and wondering whether it's the right one, or running none and wondering where to start, give BetterClaw a try. $49/month for Pro, BYOK across 28+ model providers including all three covered here, and your first deploy takes about 60 seconds. We handle the routing infrastructure. You handle the call on which model gets which task.
The best LLM for OpenClaw isn't one model. It's the right model for each job, routed well.
Frequently Asked Questions
What is the best LLM for OpenClaw in 2026?
There isn't a single best LLM for OpenClaw. For customer-facing and high-reliability agent work, Claude Sonnet 4.6 at $3/$15 per million tokens is the default. For long-horizon autonomous coding, GLM 5.1 at $1/$3.20 is the strongest price-to-performance option with open weights. For high-volume cheap decisions, MiniMax M2.7 at $0.30/$1.20 wins on pure cost. Most production agents should route between them per task.
How does GLM 5.1 compare to Claude Sonnet 4.6 for OpenClaw?
GLM 5.1 is roughly 3x cheaper than Sonnet 4.6 on API pricing and scores 58.4 on SWE-Bench Pro, officially ahead of Claude Opus 4.6 at 57.3 on that specific benchmark. Sonnet 4.6 leads on the broader coding composite and offers a 1M context window vs GLM's 200K. GLM is open-weights under MIT license; Sonnet is API-only. For coding-heavy agent work where cost matters, GLM wins. For multi-purpose agents touching customer data, Sonnet is still the safer pick. See how models compare for OpenClaw workloads for more detail.
How do I set up multi-model routing for my OpenClaw agent?
At a high level: pick models for each category of task your agent handles, configure API keys for each provider, set routing rules in natural language or config, and test the fallback path when one provider is down. On managed platforms like BetterClaw, this is configured through a UI. On self-hosted OpenClaw, you're managing provider SDKs, routing logic, and credential storage yourself.
Is GLM 5.1 worth using instead of Claude Sonnet 4.6 to save money?
For coding-heavy agents, yes. GLM 5.1 is about 3x cheaper on API and scores competitively with Claude Opus 4.6 on SWE-Bench Pro. For customer-facing agents where reliability is the highest priority, Sonnet 4.6's consistency still justifies the premium. Many teams use both, routing cheap coding tasks to GLM and consequential user interactions to Sonnet. See BetterClaw pricing for how multi-model routing fits into a managed agent deployment.
Is MiniMax M2.7 reliable enough for production OpenClaw agents?
For the right use cases, yes. M2.7 scored 56.2% on SWE-Pro and 57.0% on Terminal Bench 2, which is competitive for high-volume agent work. The honest tradeoff: it's slower than Sonnet and less reliable on the hardest reasoning tasks. Use it for triage, classification, and summarization where cost matters more than peak capability. Do not use it as your only model for agents handling anything irreversible.



