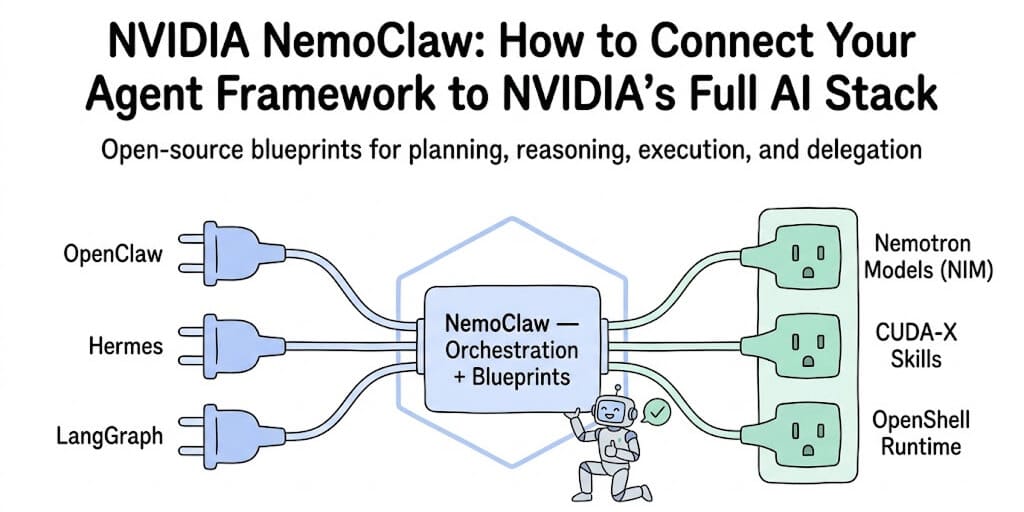
NVIDIA just open-sourced the orchestration layer most agent frameworks are missing. Here's what NemoClaw actually does and how to wire it into your existing setup.
We'd been running an agent on OpenClaw with Claude Sonnet for six months. It worked. But every time the agent needed to process a 50,000-row dataset, it would try to reason through the data line by line. Slow. Expensive. Token-hungry.
Then someone on the team pointed to NVIDIA NemoClaw and its CUDA-X agent skills. "What if the agent could call cuDF to process the dataframe on the GPU instead of reasoning about each row?"
We tested it. The data processing step went from 45 seconds and 30,000 tokens to 2 seconds and 200 tokens. Same agent. Same framework. Different skill.
That's the pitch for NemoClaw, and it's a real one. Not a new agent framework to replace what you're already using. A layer that connects your existing framework to NVIDIA's model stack, GPU-accelerated skills, and secure runtime. If you're new to it, start with our NemoClaw vs OpenClaw breakdown on what's actually different.
Here's what it is, how it works, and whether it matters for your setup.
What NemoClaw actually is (and isn't)
NemoClaw is an open-source orchestration framework and blueprint library for AI agents. NVIDIA announced it at GTC Taipei / Computex on June 1, 2026, as part of a broader Agent Toolkit that includes Nemotron models, OpenShell secure runtime, and CUDA-X agent skills.
What it is: Templates and blueprints for how agents plan, reason, execute, and delegate. Task decomposition patterns. Multi-agent delegation flows. Tool invocation with error recovery. A model router for choosing which model handles which step. Integration with NeMo libraries for customization.
What it isn't: A replacement for your agent framework. NemoClaw uses a "choice of harness" architecture. You keep your existing orchestration (OpenClaw, Hermes, LangGraph), and NemoClaw provides the structured blueprints and NVIDIA-specific integrations that plug into it.
Think of it like this: if your agent framework is the car, NemoClaw is a set of pre-built engine components and a GPS system that snap in. You don't replace the car. You upgrade what's under the hood.
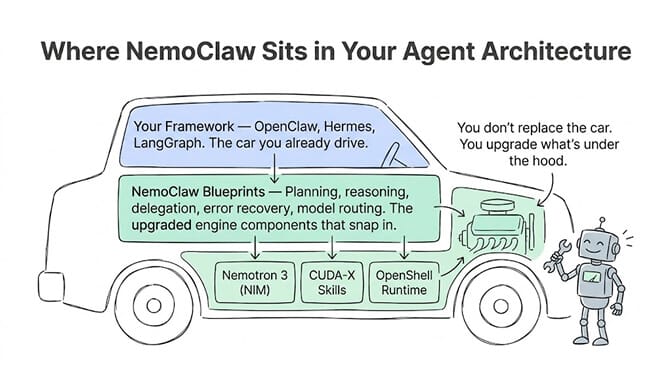
NemoClaw is not a new framework. It's the orchestration layer most frameworks are missing: structured blueprints for planning, delegation, and error recovery, plus direct access to NVIDIA's model and compute stack.
CUDA-X agent skills (this is the part that changes things)
The blueprints are useful. The CUDA-X agent skills are the real differentiator.
CUDA-X skills are GPU-accelerated domain capabilities that your agent can call as tools. Instead of the LLM reasoning its way through a complex computation (slow, expensive, error-prone), the agent calls a CUDA-X skill that executes the computation on GPU hardware in milliseconds.
Here's what's available:
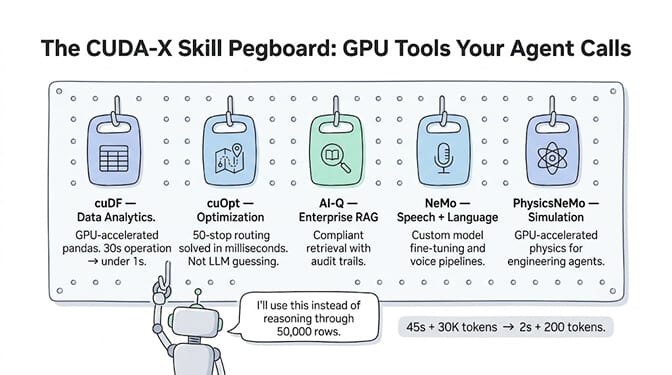
cuDF for data analytics. Your agent can call cuDF to process, filter, join, and aggregate large datasets at GPU speed. A pandas-equivalent operation that takes 30 seconds on CPU runs in under 1 second on GPU via cuDF. For agents that handle data pipelines, reporting, or analytics, this is massive.
cuOpt for optimization. Route optimization, scheduling, resource allocation. If your agent needs to solve "what's the best delivery route for these 50 stops," cuOpt solves it on GPU instead of the LLM guessing.
AI-Q for enterprise RAG. NVIDIA's retrieval pipeline for connecting agents to enterprise knowledge bases. Structured for compliance-sensitive environments where you need audit trails on what was retrieved and why.
NeMo for speech and language. Custom model fine-tuning, speech recognition, text-to-speech. If your agent handles voice interactions, NeMo provides the pipeline.
PhysicsNeMo for physics simulation. Agents that need to simulate physical systems (engineering, manufacturing, scientific research) can run GPU-accelerated simulations rather than approximating through language.
CUDA-X skills are available now through the Claude Code marketplace and the Hermes Skills Hub. They're also installable directly through NemoClaw's blueprint installer.
For agent builders focused on business workflows (email, CRM, support, scheduling), CUDA-X skills are overkill. They matter when your agent's workload includes heavy computation, data processing, or domain-specific simulation that an LLM shouldn't be doing alone.
Which frameworks NemoClaw supports (and how to connect)
NemoClaw's "choice of harness" means it doesn't dictate your orchestration layer. The supported frameworks as of June 2026:
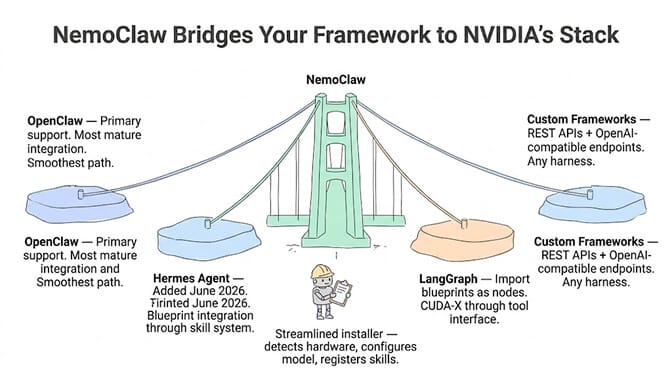
OpenClaw is the primary supported framework. The NemoClaw installer sets up blueprints directly in an OpenClaw environment. The integration is the most mature. If you're already on OpenClaw, this is the smoothest path.
Hermes Agent was added in the June update. The NemoClaw installer now supports Hermes alongside OpenClaw. Blueprint integration works through Hermes's skill system.
LangGraph/LangChain works through NemoClaw's model router and tool definitions. You import NemoClaw's blueprints as LangGraph nodes and call CUDA-X skills through the tool interface.
Custom frameworks can integrate through the model router API and CUDA-X skill endpoints. NemoClaw exposes standard OpenAI-compatible endpoints for model access and REST APIs for skill invocation.
The quick setup path
The streamlined installer (released at Computex) handles most of the setup:
Install NemoClaw for your framework (OpenClaw or Hermes). The installer detects your hardware, sets up the appropriate Nemotron model for your GPU/memory, configures OpenShell sandboxing, and registers CUDA-X skills as available tools.
For local hardware (DGX Spark, RTX PCs, DGX Station), the installer optimizes inference with NVFP4 checkpoints. NVIDIA and vLLM have co-optimized inference to deliver 2.6x performance on DGX Spark compared to previous checkpoints. If you're still deciding whether the Spark is worth it, our DGX Spark alternatives guide compares cheaper local options.
For cloud deployments, NemoClaw connects to Nemotron 3 via NVIDIA NIM microservices on HuggingFace, OpenRouter, or NVIDIA Build.
The enterprise angle (why 12+ companies are already building on this)
The Computex show floor had more than a dozen engineering software providers demonstrating NemoClaw-based autonomous agents:
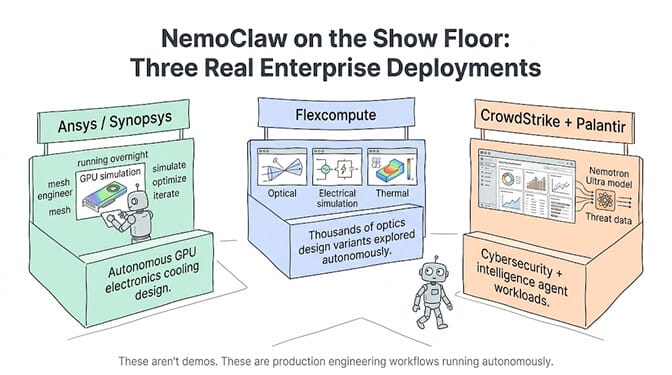
Ansys (Synopsys) demoed an autonomous AI engineer using NemoClaw to mesh, simulate, and optimize GPU electronics cooling designs. The agent decomposes the engineering task, runs simulations through PhysicsNeMo, evaluates results, and iterates. Overnight.
Flexcompute combined OpenShell with their Tidy3D and PhotonForge agents for multiphysics co-packaged optics design. Optical, electrical, and thermal simulation exploring thousands of design variants autonomously.
CrowdStrike and Palantir are both integrating Nemotron 3 Ultra into their agent platforms for cybersecurity and intelligence workloads.
These aren't demo projects. They're production engineering workflows running autonomously for hours using NemoClaw's planning and delegation blueprints.
Gartner projects 40% of enterprise applications will embed AI agents by end of 2026. NVIDIA's bet is that many of those agents will need GPU-accelerated compute for data-heavy or simulation-heavy workloads, not just LLM reasoning. NemoClaw is how they make that integration accessible.
When NemoClaw matters for you (and when it doesn't)
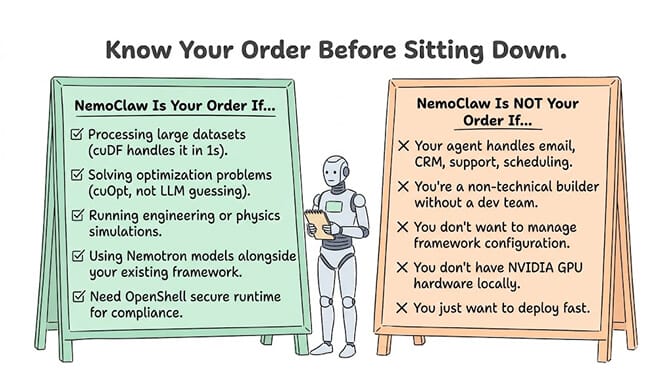
NemoClaw makes sense when:
- Your agent processes large datasets that the LLM currently reasons through row by row. CUDA-X cuDF is a direct upgrade.
- Your agent solves optimization problems (routing, scheduling, allocation). cuOpt handles these in milliseconds.
- Your agent runs engineering or scientific simulations. PhysicsNeMo gives you GPU-accelerated simulation as a tool call.
- You want to use Nemotron models alongside your existing framework instead of replacing everything.
- You need the OpenShell secure runtime for compliance or governance requirements.
NemoClaw doesn't matter when:
- Your agent handles business workflows (email, CRM, support, scheduling). These workloads don't need GPU-accelerated compute. They need good integrations, persistent memory, and trust levels.
- You're a non-technical builder who doesn't want to manage local hardware or agent framework configuration. NemoClaw requires a developer to set up and maintain. BetterClaw's visual builder handles the orchestration, model routing, and 200+ skills without touching a terminal. Free plan with 1 agent and 500 credits a month. $49/month on Pro. BYOK with zero markup, including Nemotron models via OpenRouter.
The bigger picture: NVIDIA is becoming an agent platform company
Here's what's worth stepping back to see. NVIDIA shipped six agent-related products at Computex:
Vera CPU (purpose-built for agentic AI). Nemotron 3 Ultra (550B open-weight model). NemoClaw (orchestration framework). OpenShell (secure runtime). DGX Spark + RTX Spark (consumer hardware for local agents). CUDA-X Agent Skills (GPU-accelerated tools).
That's a full stack. From silicon to skills. NVIDIA isn't just selling GPUs to run models anymore. They're building the infrastructure layer that agents run on. Models, orchestration, security, compute, hardware.
For agent builders, this means two things. First, the "should I use NVIDIA models" question is now "should I use the NVIDIA agent stack," which is a much bigger decision. Second, the open-source approach (NemoClaw, Nemotron open-weights, MIT license) means you can adopt pieces without buying the whole stack.
McKinsey estimates AI agents represent a $2.6-4.4 trillion addressable market. NVIDIA is positioning itself as the platform company for the compute-heavy segment of that market. For business agents that don't need GPU compute, the market is wide open for platforms focused on integration, ease of use, and speed to production.
Give BetterClaw a look if your agents are business-focused rather than compute-focused. Free plan with 1 agent and 500 credits a month. $49/month for Pro. 28+ model providers including Nemotron via OpenRouter. Deploy in 60 seconds. We handle the orchestration and infrastructure. You handle what the agent actually does.
Frequently Asked Questions
What is NVIDIA NemoClaw?
NemoClaw is an open-source orchestration framework and blueprint library for AI agents, announced by NVIDIA at Computex (GTC Taipei) on June 1, 2026. It provides structured templates for agent planning, reasoning, execution, and delegation. NemoClaw integrates with existing frameworks (OpenClaw, Hermes, LangGraph) through a "choice of harness" architecture, and connects agents to Nemotron models, CUDA-X GPU-accelerated skills, and the OpenShell secure runtime.
How does NemoClaw compare to building agents from scratch with LangGraph?
NemoClaw provides pre-built blueprints for common agent patterns (task decomposition, multi-agent delegation, error recovery) that you'd otherwise code manually in LangGraph. It also gives you direct access to CUDA-X skills (GPU-accelerated data processing, optimization, simulation) and the OpenShell secure runtime. LangGraph offers maximum flexibility but requires building every pattern from scratch. NemoClaw is the structured, NVIDIA-optimized middle ground.
How do I install NemoClaw for my agent framework?
Use the streamlined installer released at Computex 2026. It detects your hardware, configures the appropriate Nemotron model, sets up OpenShell sandboxing, and registers CUDA-X skills as available tools. Supports OpenClaw and Hermes natively. For LangGraph, import NemoClaw blueprints as nodes and connect CUDA-X skills through the tool interface. For cloud, connect to Nemotron via NVIDIA NIM on HuggingFace, OpenRouter, or NVIDIA Build.
How much does NemoClaw cost?
NemoClaw itself is free and open-source. The costs come from the models and compute: Nemotron 3 Ultra is available as open-weights (free to self-host) or via API through OpenRouter and NVIDIA NIM (usage-based pricing). CUDA-X skills require NVIDIA GPU hardware to run locally. For cloud-hosted access, pricing follows standard NVIDIA NIM rates. DGX Spark hardware starts at approximately $3,000.
Do I need NemoClaw if my agents handle business workflows like email and CRM?
Probably not. NemoClaw's primary value is connecting agents to GPU-accelerated compute (data analytics, optimization, physics simulation) and NVIDIA's model stack. If your agents handle email, CRM, support, or scheduling workflows, you need good integrations, persistent memory, and trust levels more than GPU compute. Managed platforms like BetterClaw provide these capabilities out of the box with 200+ verified skills and 25+ OAuth integrations.