MiniMax M3 is real and running. Qwen 3.7 is not what you think. Here's what you can actually deploy as a local AI agent backend today, what's API-only, and how to stop wasting time on setup commands that don't work.
I typed ollama pull qwen3.7 and hit enter.
"Error: model 'qwen3.7' not found."
Tried qwen3.7-max. Same thing. Searched HuggingFace. Nothing under the official Qwen org. Went to Reddit. Found three "complete setup guides" for running Qwen 3.7 locally, each with confident terminal commands and VRAM tables. Every single one was fiction.
Here's what nobody writing SEO content about these models will tell you: Qwen 3.7 cannot be run locally. Not yet. Maybe not ever in its current form. The open weights that Alibaba's release pattern predicted for mid-June 2026? They haven't shipped. And the silence is getting louder.
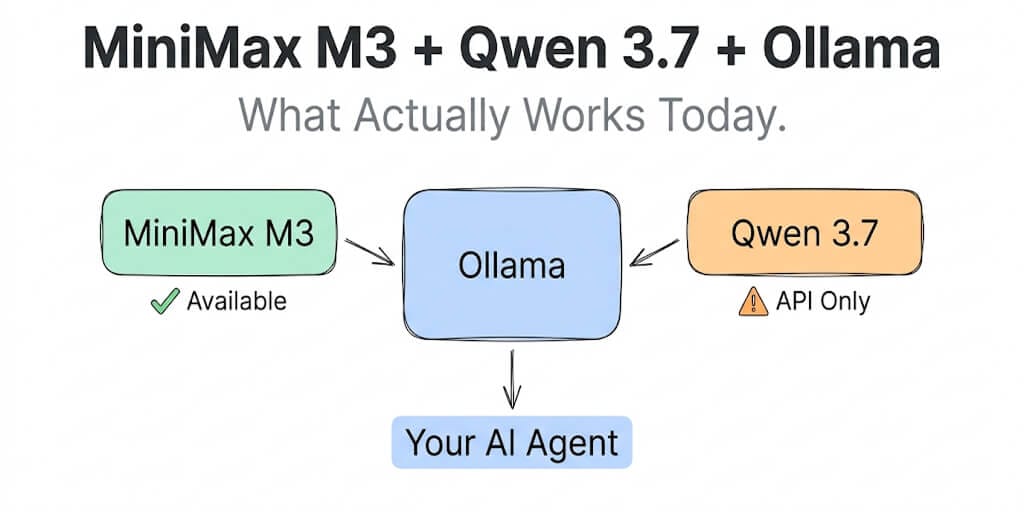
MiniMax M3, on the other hand? It's real. Open weights hit HuggingFace on June 7. Community GGUF quants are live. Ollama has a cloud-hosted version you can pull with two commands. The local path exists too, if you have the hardware.
This is the honest guide to building a local AI agent stack with these models. What works, what doesn't, what to use instead, and how to stop guessing.
What you can actually run today
Let's kill the confusion right now.
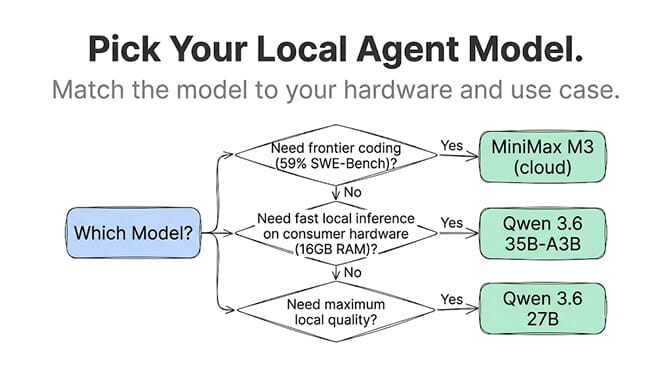
MiniMax M3 launched June 1, 2026. Open weights, 428B total parameters with 23B active (MoE architecture), 1M token context window, 59% SWE-Bench Pro. It's built for agent work. The API runs at $0.30/$1.20 per million tokens on the promo tier. Ollama supports it via cloud-hosted inference. Local GGUF quants exist but require serious hardware (128 GB+ RAM minimum for the smallest quantization).
Qwen 3.7 Max launched May 20, 2026 as an API-only model. No open weights. No HuggingFace repo. No Ollama tag. No GGUF files. The benchmarks are strong (92.4% GPQA Diamond, 56.6 on Artificial Analysis Intelligence Index), but you cannot download it. Period.
Qwen 3.6 is the model you should actually be running locally for Qwen-family agent work. Available on Ollama today. Two variants: 27B dense (17 GB disk, 77.2% SWE-bench) and 35B-A3B MoE (24 GB disk, only 3B active parameters, incredibly efficient). Apache 2.0 licensed.

If you came here to run Qwen 3.7 locally, use Qwen 3.6. It's real, it's good, and it's available right now. Swap it for 3.7 when (and if) open weights drop.
Setting up MiniMax M3 on Ollama
MiniMax M3 is the headline act here. It's the first open-weight model to combine frontier-level coding performance, a 1M-token context window, and native multimodality (text, image, video) in a single architecture. For agent workflows, the combination of strong tool-use capability and million-token context means your agent can hold an entire codebase or document set in memory while reasoning about it.
The cloud path (works on any machine)
Ollama offers M3 as a cloud-hosted model that runs on US servers with zero data retention. This is the fastest path to getting M3 into your agent stack:
# Install Ollama if you haven't
brew install ollama # Mac
# or: curl -fsSL https://ollama.com/install.sh | sh # Linux
# Pull MiniMax M3 Cloud
ollama pull minimax-m3:cloud
# Test it
ollama run minimax-m3:cloud "Explain how MoE routing works in 3 sentences"
That's it. M3 is now running as a local API endpoint at localhost:11434. Any agent framework that supports the Ollama API (which is most of them) can connect to it.
The cloud tag means inference happens on remote GPUs, but the Ollama API interface stays local. Your prompts go to MiniMax's servers, get processed, and results come back. For most agent use cases where you're not handling extremely sensitive data, this is the right tradeoff: frontier model performance without needing $15,000 in GPU hardware.
The local path (if you have the hardware)
Running M3 fully locally means zero data leaves your machine. But the model is 428B parameters, so even at aggressive quantization, you need significant resources.
The community quants are tracked on HuggingFace under unsloth/MiniMax-M3-GGUF. The smallest quantization (IQ1_M) still requires roughly 128 GB of disk and corresponding RAM. The recommended balance between quality and size is IQ3_XXS at about 159 GB.
Practical hardware requirements for local M3:
A Mac Studio or MacBook Pro with 192 GB unified memory handles Q4 comfortably. On the GPU side, you're looking at 2+ A100 80 GB cards or equivalent. A single RTX 4090 (24 GB VRAM) cannot run M3 at any quantization level.
There's one additional catch: llama.cpp support for M3 is still preliminary. As of late June 2026, you need to compile from a specific pull request (PR #24523) to run the GGUF files. This will stabilize, but right now local M3 is early-adopter territory.
MiniMax M3 cloud on Ollama gives you frontier agent performance with two commands. Local M3 gives you data sovereignty but requires workstation hardware. Pick based on your data sensitivity, not your enthusiasm.
Qwen 3.7: why it's not on Ollama (and what changed)
Here's the uncomfortable truth about Qwen 3.7.
Alibaba announced Qwen 3.7 Max at the Alibaba Cloud Summit on May 20, 2026. The benchmarks were impressive. It scored highest among Chinese models on Artificial Analysis's Intelligence Index. The 1M-token context window and native Anthropic API protocol support made it immediately attractive for agent builders.
But the open weights never came.
Alibaba's historical pattern was consistent: ship the API, release open weights 3 to 4 weeks later. Qwen 3.6 followed this exactly. API in late March, open weights in mid-April. By that cadence, Qwen 3.7 open weights should have appeared by mid-June.
It's now late June 2026. The HuggingFace Qwen organization shows zero Qwen 3.7 repositories. No GGUF files. No community quants. Some in the open-source AI community are asking whether Alibaba is splitting into two tracks: a closed frontier tier (3.7 Max, 3.7 Plus, Qwen-VLA) and an open mid-tier that stays one generation behind.
We don't know yet. But waiting for weights that may not come isn't a strategy.
Use Qwen 3.6 locally instead
Qwen 3.6 is genuinely excellent for agent work. The 27B dense variant scores 77.2% on SWE-bench Verified, which actually beats some larger flagships. The 35B-A3B MoE variant activates only 3B parameters per token, making it fast enough for real-time agent interactions on consumer hardware.
# Pull Qwen 3.6 (MoE variant, best for most setups)
ollama pull qwen3.6:35b-a3b
# Or the dense variant if you have 24GB+ VRAM
ollama pull qwen3.6:27b
# Test it
ollama run qwen3.6:35b-a3b "List 3 ways to structure a multi-step agent workflow"
The 35B-A3B MoE needs about 24 GB of disk space and runs well on 16 GB of system RAM at Q4_K_M quantization. That means a MacBook Pro with 16 GB or an RTX 3090/4090 handles it comfortably.
Both variants support tools and function calling natively. Thinking mode is on by default in Qwen 3.6 — pass "think": false in your API calls if you want faster tool-call responses without the reasoning chain.
Accessing Qwen 3.7 via API
If you specifically need Qwen 3.7 Max performance for long-horizon agent tasks, it's available through API:
Through OpenRouter at qwen/qwen3.7-max, pricing is $2.50 per million input tokens and $7.50 per million output tokens. Through Alibaba Cloud Model Studio (DashScope) directly, pricing is slightly lower. Through Fireworks AI, which has a direct hosting partnership with Alibaba for the 3.7 Plus variant.
The model natively supports the Anthropic API protocol, which means agent frameworks built for Claude work with Qwen 3.7 without an adapter layer. That's a notable compatibility win.
The hybrid approach (this is what actually works)
Here's what we've found works best in practice: run a local model for the majority of agent tasks, and route to a frontier API for the hard stuff.
Your Qwen 3.6 35B-A3B handles 80% of agent interactions. Routine tool calls, simple reasoning, data extraction, structured output. It runs locally, costs nothing per token, and responds fast.
For the remaining 20% — the complex multi-step reasoning, the 500K-token codebase analysis, the tasks where you genuinely need frontier capability — route to MiniMax M3 (via Ollama cloud or API) or Qwen 3.7 Max (via OpenRouter).
This is exactly the architecture that BetterClaw supports natively. Our platform lets you connect any model provider via BYOK, including your local Ollama instance for complete data privacy. Or paste an OpenRouter API key to access MiniMax M3, Qwen 3.7 Max, Claude, GPT, and 28+ other providers through a single agent configuration. You don't have to choose one model or one approach. Free plan, no credit card, $19/month for Pro.
Hardware requirements: the real numbers
Let's get specific about what you need to run each model locally.

Qwen 3.6 35B-A3B (MoE, recommended for most users): 16 GB RAM minimum (Mac or Linux). 24 GB disk space. Runs at Q4_K_M quantization. RTX 3090/4090 or M1 Pro/M2 Pro and above. Generates roughly 15 to 25 tokens per second on Apple Silicon.
Qwen 3.6 27B (Dense, higher quality): 24 GB+ VRAM or 32 GB+ unified memory. 17 GB disk. Better reasoning than the MoE variant but slower inference. RTX 4090 or M2 Max and above.
MiniMax M3 (Local GGUF): 128 GB+ RAM minimum for the smallest quant. Mac Studio 192 GB or 2x A100 80 GB. This is workstation territory. Most developers should use the Ollama cloud path instead.
MiniMax M3 (Ollama Cloud): Any machine that can run Ollama. Literally a Chromebook would work. Inference happens remotely.
Gartner projects 40% of enterprise applications will embed AI agents by end of 2026. The local-first segment of that market is growing fast. Between MiniMax M3, Qwen 3.6, and models like Gemma 4 12B, there are genuinely production-capable models running on consumer hardware today. The gap between "local hobby project" and "local production agent" closed this year.
Wiring your local model into an agent framework
Once you have Ollama serving your model, connecting it to an agent framework is straightforward. Ollama exposes an OpenAI-compatible API at localhost:11434/v1. Any framework that supports custom OpenAI-compatible endpoints works.
For a basic test, you can verify your local model handles tool calling (the foundation of agent behavior) by sending a function-call request to the Ollama API. Both Qwen 3.6 and MiniMax M3 support tools natively.
The more interesting question is what happens after the initial connection. Persistent memory, context management, trust levels, skill verification — these are the production concerns that separate a working demo from a deployed agent. Running the model locally solves the inference problem. It doesn't solve the agent platform problem.
If you're comfortable managing your own agent infrastructure on top of Ollama, frameworks like CrewAI (47K+ GitHub stars, requires Python) and LangGraph give you maximum flexibility at the cost of significant setup time and ongoing maintenance. If you'd rather spend your time on agent workflows instead of infrastructure, that's exactly the tradeoff BetterClaw's no-code platform was designed to resolve.
When to wait and when to ship
Here's the honest assessment of where things stand.
MiniMax M3 is production-ready for agent backends via API or Ollama cloud. Local inference is early-adopter territory. The MSA sparse attention architecture makes the 1M-token context window practical, not just a spec sheet number. At $0.30 per million input tokens (promo pricing), it's 12x cheaper than GPT-5.5 on input.
Qwen 3.7 open weights are a question mark. The June window that precedent predicted has closed. It might be weeks away, it might be months, or the open-weight Qwen line might stay at 3.6 while the frontier goes proprietary. Use Qwen 3.6 today and swap later if weights drop.
Qwen 3.6 is the practical workhorse. Available now, runs on consumer hardware, Apache 2.0, strong coding and agent benchmarks. This is what you should build on if you want local inference today.
The models are half the equation. The agent platform is the other half. Whether you build your own stack, use a framework, or use a managed platform, just don't let model selection become a reason to delay shipping. The best model for your agent is the one you can deploy today.
If any of this resonated, give BetterClaw a look. Free plan with 1 agent and every feature. $19/month per agent for Pro. Connect your local Ollama instance, your OpenRouter key, or any of our 28+ supported providers. Your first agent deploys in about 60 seconds. We handle the platform. You pick the model.
The real takeaway
Six months ago, "run a frontier model locally as your agent backend" was aspirational. Today, MiniMax M3 on Ollama gives you a 59% SWE-Bench Pro model with a million-token context window for two terminal commands. Qwen 3.6 gives you production-grade local inference on a laptop.
The gap between open-weight models and closed APIs shrunk dramatically this year. It hasn't disappeared. But the set of tasks where local models are genuinely sufficient for production agent work got a lot bigger.
Don't wait for the perfect model. Build with what works today. The model can always be swapped. The agent workflows you build this week can't be built retroactively.
Frequently Asked Questions
What is the best local model for AI agent workflows in 2026?
For most developers, Qwen 3.6 35B-A3B is the best balance of performance, efficiency, and accessibility. It runs on 16 GB RAM, activates only 3B parameters per token for fast inference, supports tool calling natively, and is Apache 2.0 licensed. For tasks requiring frontier coding capability, MiniMax M3 via Ollama's cloud tag delivers 59% SWE-Bench Pro performance without needing workstation hardware locally.
How does MiniMax M3 compare to Qwen 3.7 for agent tasks?
MiniMax M3 is open-weight and available for both cloud and local inference, while Qwen 3.7 is currently API-only with no announced date for open weights. On benchmarks, M3 scores 59% on SWE-Bench Pro and 83.5 on BrowseComp. Qwen 3.7 Max scores 92.4% on GPQA Diamond and 56.6 on the Artificial Analysis Intelligence Index. M3 is the better choice if you want open weights or Ollama compatibility. Qwen 3.7 via API is the better choice if raw benchmark performance matters most for your use case.
How do I set up Ollama for a local AI agent backend?
Install Ollama (brew install ollama on Mac or curl -fsSL https://ollama.com/install.sh | sh on Linux), then pull your model (ollama pull qwen3.6:35b-a3b for local or ollama pull minimax-m3:cloud for cloud-hosted M3). Ollama exposes an OpenAI-compatible API at localhost:11434/v1 that any agent framework can connect to. The entire setup takes under five minutes for the cloud path or 10 to 15 minutes including model download for local.
How much does running a local AI agent model cost compared to API?
A local model like Qwen 3.6 costs nothing per token after the initial hardware investment (which you may already have). MiniMax M3 via Ollama cloud costs about $0.30 per million input tokens on the promo tier. For comparison, GPT-5.5 runs about $10 per million input tokens and Claude Opus 4.7 about $15. At 100,000 agent interactions per month, local inference saves roughly $500 to $1,500/month compared to frontier APIs. BetterClaw's BYOK model lets you connect any provider or local instance at $0 on the free plan or $19/month per agent on Pro, with zero inference markup.
Can I use MiniMax M3 and Qwen models together in one agent?
Yes. The hybrid approach routes routine tasks to a fast local model (Qwen 3.6) and complex reasoning tasks to a frontier model (MiniMax M3 or Qwen 3.7 API). BetterClaw supports this natively, letting you configure multiple model providers per agent and route based on task complexity. If you're building your own stack, Ollama lets you run multiple models simultaneously, and most agent frameworks support model selection per task or step.