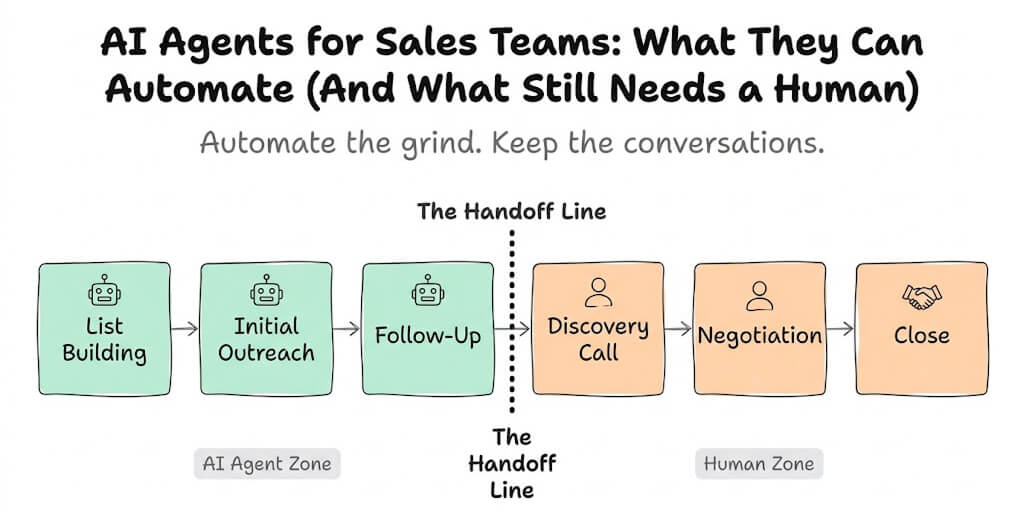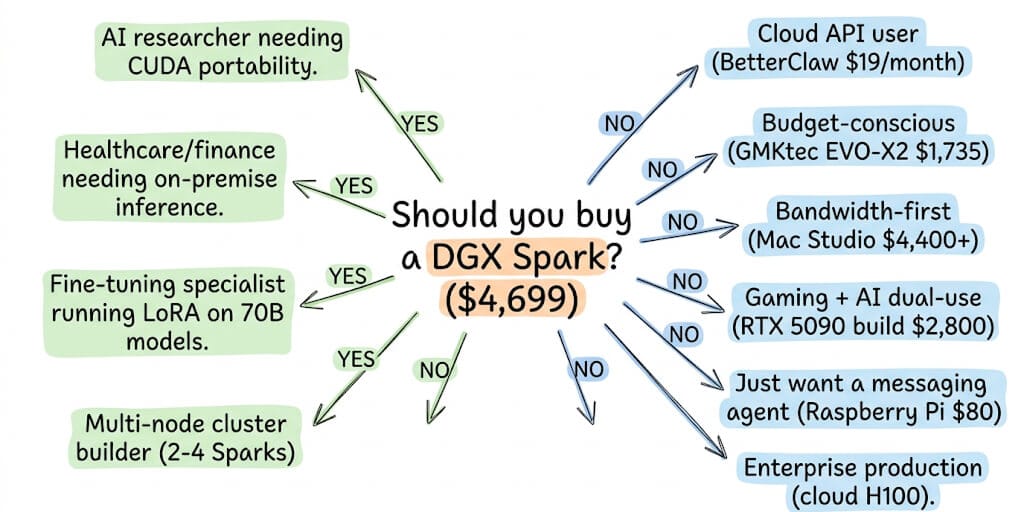
NVIDIA raised the price to $4,699. AMD's alternative costs $1,735. The ASUS version starts at $2,999. Cloud APIs cost $0.14/M tokens. Here are the four buyer profiles that justify the Spark, and the six that don't.
NVIDIA raised the DGX Spark from $3,999 to $4,699 in February 2026. Memory supply constraints. LPDDR5x pricing. The usual.
Two weeks later, GMKtec shipped the EVO-X2 with AMD's Ryzen AI Max+ 395 for $1,735. Same 128GB unified memory. Same 273 GB/s bandwidth. Faster token generation on medium-to-large models in TechRadar's benchmarks. Half the price.
That changed the buying decision completely. The DGX Spark is no longer the only 128GB AI desktop. It's the most expensive one. For the full menu of options at every budget, see our DGX Spark alternatives guide. The question isn't "should you buy a DGX Spark?" It's "does the NVIDIA ecosystem premium justify $3,000 more than the competition?"
Here are the four buyer profiles where it does, and the six where it doesn't.
The four people who should actually buy a DGX Spark
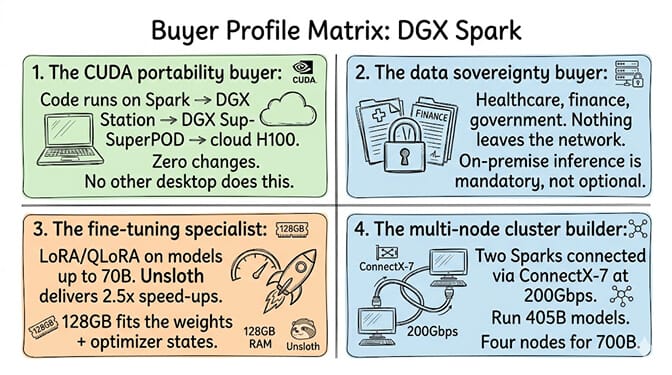
Profile 1: The CUDA portability developer
This is the DGX Spark's real value proposition. Code that runs on the Spark runs on DGX Station, DGX SuperPOD, and cloud NVIDIA instances with zero changes. No other $4,699 desktop gives you that pipeline. If your workflow is "prototype locally → deploy to NVIDIA cloud," the Spark is the only desktop that eliminates the translation step.
Who this is: ML engineers at companies using NVIDIA infrastructure. Researchers submitting to conferences with NVIDIA benchmark requirements. Teams building products that will eventually run on NVIDIA cloud.
Profile 2: The data sovereignty buyer
Healthcare. Finance. Government. Legal. Any organization where sending patient data, financial records, or classified information to a cloud API is prohibited by regulation or policy. The DGX Spark runs inference entirely on-premise. Nothing leaves the network.
The honest caveat: If data sovereignty is the requirement but you only need 8-20B models, the GMKtec EVO-X2 at $1,735 meets the same requirement for less than half the cost. The Spark's premium only justifies itself if you also need CUDA or NVIDIA's software stack.
Profile 3: The fine-tuning specialist
128GB unified memory fits LoRA and QLoRA fine-tuning for models up to 70B parameters. Unsloth delivers 2.5x speed-ups over standard HuggingFace. NeMo AutoModel provides NVIDIA's fine-tuning pipeline. Three frameworks, all well-supported on the Spark.
Who this is: ML engineers customizing open-source models for specific domains. Teams building vertical AI products that need fine-tuned behavior. Researchers running ablation studies.
For the complete DGX Spark bandwidth analysis and model performance benchmarks, our guide covers which model sizes run at interactive speeds.
Profile 4: The multi-node cluster builder
Two DGX Sparks connected via ConnectX-7 (200Gbps aggregate) run models up to 405B parameters. Four nodes (announced at GTC 2026) support up to 700B with near-linear scaling. At $9,398 for two nodes or $18,796 for four, this is the cheapest way to run massive models locally.
The honest caveat: At $18,796 for four nodes, you could rent an H100 for 9,387 hours ($2/hour). That's over a year of 24/7 cloud access. The cluster only makes financial sense if you're running it daily for 12+ months.
The six people who should buy something else
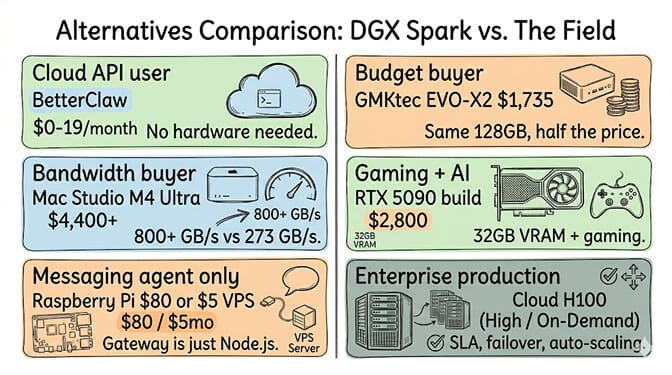
Alternative 1: You use cloud APIs (skip hardware entirely)
If your agents use Claude, GPT, or DeepSeek via API, the DGX Spark is a $4,699 messaging router. The agent gateway is a Node.js process that sends API requests. A $5/month VPS does the same job. A Raspberry Pi does the same job.
If you want an always-on agent on cloud APIs without any hardware purchase, BetterClaw handles the infrastructure for $0-19/month. 28+ model providers. BYOK. No hardware. No local inference required. Free tier with 1 agent. $19/month per agent for Pro.
Alternative 2: You want 128GB but not the NVIDIA tax (GMKtec EVO-X2)
$1,735. Same 128GB unified memory. Same 273 GB/s bandwidth. AMD Ryzen AI Max+ 395 APU. TechRadar tested it: faster generation speeds on medium-to-large models including GPT-OSS 20B and Llama 3.3 70B. Lower first-token latency.
The trade-off: ROCm instead of CUDA. Improving rapidly but lacks NVIDIA's pre-configured Docker containers, NIM microservices, and NemoClaw. If you don't need CUDA, this is the obvious budget pick.
Alternative 3: You need bandwidth more than capacity (Mac Studio M4 Ultra)

800+ GB/s bandwidth. 192GB max memory. 3x faster token generation for models above 30B. Starting at $4,400 (192GB config around $7,999). If your primary use case is running 30-70B models at interactive speed, the Mac Studio outperforms the Spark on the metric that matters most, which is exactly the DGX Spark memory bandwidth bottleneck we break down separately.
The trade-off: MLX and llama.cpp instead of CUDA. No TensorRT-LLM. No NIM. No NVIDIA ecosystem portability. For inference-only workflows, this doesn't matter.
Alternative 4: You also game (RTX 5090 build)
$2,800-3,200 for a custom build with an RTX 5090 (32GB GDDR7). Fastest inference for models under 20B. Plus you can play games on it. The DGX Spark can't run a game. For the full cost picture on a discrete GPU build, see our DGX Spark vs local GPU vs cloud comparison.
The trade-off: Only 32GB VRAM. Models above 30B require offloading to system RAM, which kills performance. The Spark's 128GB fits everything. But if 8-20B models are your range, the RTX 5090 is faster and cheaper.
Alternative 5: You just want a messaging agent (Pi or VPS)
The OpenClaw/Hermes gateway is a Node.js or Python process that sends API requests. It doesn't need local inference hardware. A Raspberry Pi 5 ($80) or a $5/month VPS runs the gateway. The AI model runs in the cloud. The hardware on your desk is irrelevant.
For the comparison of self-hosted versus managed agent deployment, our comparison covers when hardware matters and when it doesn't.
Alternative 6: You need enterprise production (cloud H100)
Spheron's analysis: "DGX Spark is a desktop computer with no managed uptime, no automatic failover, and no replacement SLA." If your AI agent is a production dependency serving customers 24/7, it doesn't belong on desktop hardware that throttles under sustained load.
The decision in one table
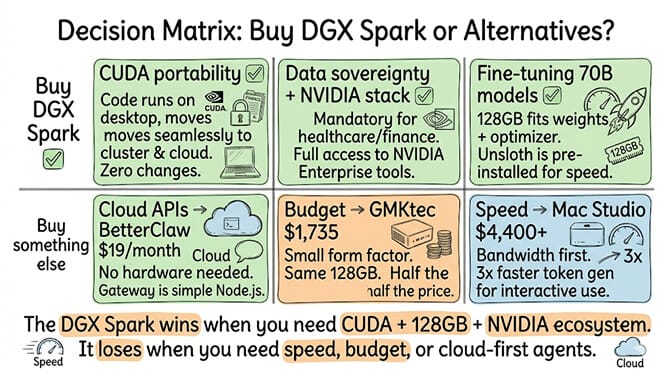
| If you need... | Buy this | Price |
|---|---|---|
| CUDA portability to NVIDIA cloud | DGX Spark | $4,699 |
| 128GB on a budget | GMKtec EVO-X2 | $1,735 |
| Fastest 30-70B inference | Mac Studio M4 Ultra | $4,400+ |
| Gaming + AI | RTX 5090 build | $2,800 |
| Just an agent on cloud APIs | BetterClaw (no hardware) | $0-19/month |
| Enterprise production SLA | Cloud H100 | ~$2/hour |
The DGX Spark is a great machine. It's just not the right machine for most people buying it. The four profiles that justify the price are specific and narrow: CUDA portability, data sovereignty with NVIDIA stack, fine-tuning, and multi-node clusters. Everyone else has a cheaper, faster, or simpler option.
If you want an always-on AI agent without buying, configuring, or maintaining any hardware, give BetterClaw a try. Free tier with 1 agent and BYOK. $19/month per agent for Pro. 28+ model providers including local Ollama endpoints if you do have a Spark. No hardware required for the 90% of agent use cases that use cloud APIs. The agent runs. The hardware decision becomes irrelevant.
Frequently Asked Questions
Who should buy a DGX Spark?
Four specific buyer profiles: CUDA portability developers (code runs identically from Spark to cloud H100), data sovereignty buyers (healthcare/finance/government needing on-premise inference), fine-tuning specialists (LoRA/QLoRA on models up to 70B), and multi-node cluster builders (2-4 Sparks for models up to 700B). Everyone else has a cheaper or faster alternative.
What's the cheapest DGX Spark alternative with 128GB?
The GMKtec EVO-X2 at $1,735 offers the same 128GB unified memory and 273 GB/s bandwidth with AMD's Ryzen AI Max+ 395. TechRadar benchmarks show faster token generation on medium-to-large models. The trade-off: ROCm instead of CUDA, so no NVIDIA NIM, TensorRT-LLM, or NemoClaw. The ASUS Ascent GX10 (same GB10 chip as the Spark) starts at $2,999 for the 1TB version.
Is DGX Spark worth $4,699 for running AI agents?
For most agent users: no. If your agent uses cloud APIs (Claude, GPT, DeepSeek), the gateway is just a Node.js process that a $5/month VPS handles. BetterClaw offers managed agent deployment at $0-19/month with no hardware required. The Spark only makes sense for agents running local models in privacy-sensitive environments where data can't leave the network.
DGX Spark vs Mac Studio M4 Ultra for local AI?
Different strengths. Mac Studio: 800+ GB/s bandwidth (3x faster token generation for 30-70B models), up to 192GB memory, silent operation. DGX Spark: full NVIDIA stack (CUDA, TensorRT-LLM, NIM, NemoClaw), 128GB, NVIDIA cloud portability. Choose Mac Studio for raw inference speed. Choose DGX Spark for NVIDIA ecosystem compatibility.
Can I run a production AI agent 24/7 on a DGX Spark?
Not recommended. Spheron: "DGX Spark is a desktop computer with no managed uptime, no failover, no SLA." Multiple reviewers document thermal throttling after 20-30 minutes of sustained load. For production 24/7 agents, use a cloud VPS ($5-10/month) or a managed platform like BetterClaw ($0-19/month). The Spark is a development machine, not a production server.