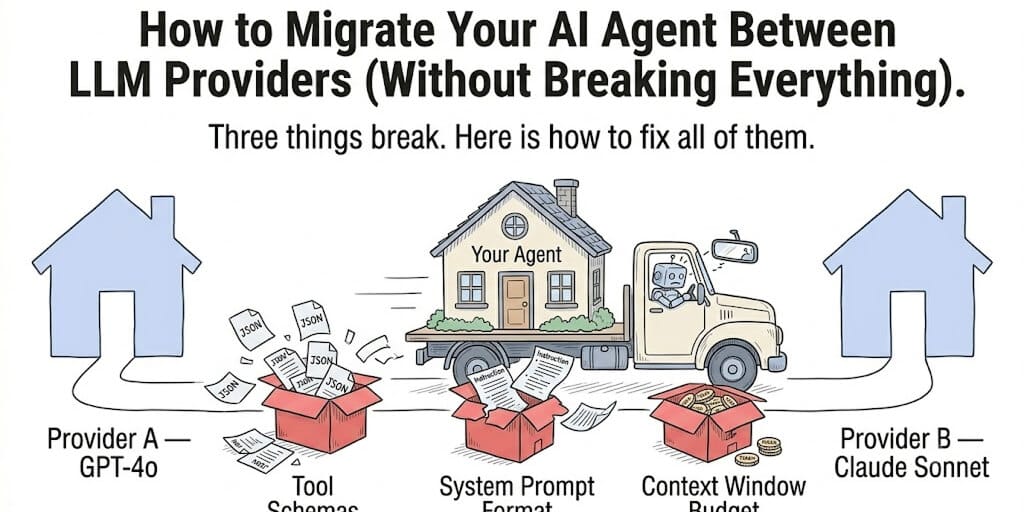
Switching from GPT-4o to Claude sounds easy until your tool calls stop working. Here's the migration checklist that saves you a weekend of debugging.
We moved a customer support agent from GPT-4o to Claude Sonnet last quarter. The model swap took five minutes. The debugging took three days.
The agent's tool calls worked perfectly on OpenAI. Defined in JSON Schema, tested, validated, deployed. On Claude, the same tool definitions parsed correctly, but the agent started calling tools with slightly different argument structures. Field names it had been inferring on GPT-4o suddenly got passed as null on Claude. One tool that accepted a customer_id parameter started receiving customerId instead.
Three days. To fix what should have been a dropdown change.
This is the hidden cost of building agents on a single provider. The moment you need to migrate your AI agent to a different LLM provider, whether for pricing, performance, or reliability, you discover that every model has its own quirks around tool calling, system prompt interpretation, and context handling.
Here's the migration guide we wish we had before that three-day weekend.
Why you'll eventually need to migrate (even if you don't think so now)
Most teams start with one LLM provider. Usually OpenAI, because GPT was there first. Everything works. Why would you switch?
Three reasons keep showing up.
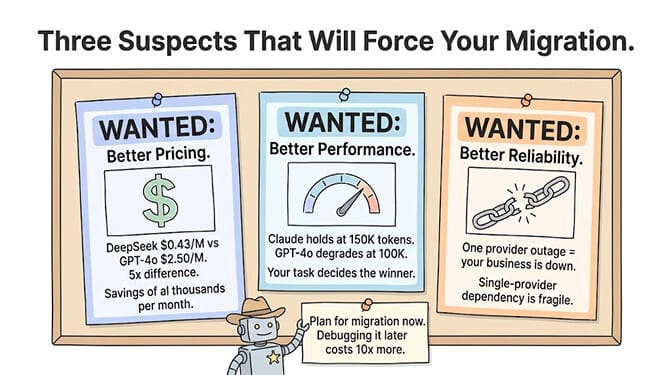
Pricing shifts. LLM pricing moves constantly. When DeepSeek V4 Pro dropped to $0.435 per million input tokens, teams running high-volume agents on GPT-4o at $2.50 per million suddenly had a compelling reason to evaluate alternatives. Claude Opus 4.8 at $5/$25 per million tokens versus GPT-5.5 at $5/$30 changes the math for reasoning-heavy agents.
Performance on your specific task. General benchmarks don't predict agent performance. Claude maintains instruction following at 150K+ tokens where GPT-4o degrades past 100K. Gemini 2.5 Flash runs at 173 tokens per second where Claude Sonnet runs at roughly 80. The best model for your agent depends on what your agent actually does.
Provider reliability. API outages happen. Rate limits get hit. If your production agent goes down because your only LLM provider has a bad day, your business has a bad day. Multi-provider capability isn't a luxury. It's resilience.
Gartner projects 40% of enterprise applications will embed AI agents by end of 2026. A meaningful percentage of those agents will need to switch providers at least once. The ones who planned for it will migrate in minutes. The ones who didn't will spend a weekend wondering why their tools stopped working.
The three things that break when you switch providers
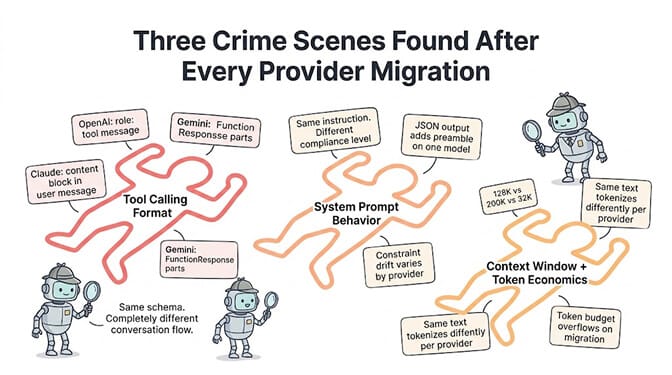
1. Tool calling formats (the biggest headache)
Every LLM provider implements tool calling (also called function calling) slightly differently. The differences seem minor in documentation. They're major in production.
OpenAI uses a tools parameter with function type definitions. Tool calls come back in the response as tool_calls with a structured function object containing name and arguments (as a JSON string).
Anthropic (Claude) uses a tools parameter with a similar JSON Schema format, but tool results are sent back differently. Claude expects tool results as separate tool_result content blocks within the user message, not as a separate tool role message like OpenAI.
Google (Gemini) uses function_declarations within a tools parameter. The response format for function calls uses a different structure with functionCall objects.
The schema definitions are similar across providers. The conversation flow for tool use is where things diverge. How you send tool results back to the model, how multi-turn tool calls are structured, and how the model signals it wants to use a tool... all of these differ.
If you've hardcoded OpenAI's tool calling format into your agent, migrating to Claude means rewriting your tool execution loop.
2. System prompt behavior
Same system prompt. Different models. Different behavior.
Claude tends to follow system prompt instructions more literally and maintains adherence over longer conversations. GPT-4o interprets instructions more flexibly but can drift from constraints as context grows. Gemini models handle structured output formatting differently than both.
A system prompt that says "Always respond in JSON format" works one way on GPT-4o (usually complies, occasionally wraps in markdown), differently on Claude (strict compliance but may add explanatory text outside the JSON), and differently again on Gemini (generally complies but with different whitespace handling).
For agents, these differences compound. A tool that parses the model's response expecting exact JSON may break on a provider that adds a natural language preamble before the structured output.
3. Context window and token economics
Your agent's behavior changes when the context window changes. An agent optimized for GPT-4o's 128K context window may overflow on a model with 32K, or it may behave differently with Claude's 200K window because the extra space changes how much history the model attends to.
Token counting also differs between providers. The same English text tokenizes differently on OpenAI's tiktoken versus Anthropic's tokenizer versus Google's tokenizer. A prompt that fits within a token budget on one provider may exceed it on another.
The migration checklist (do this in order)

Here's the step-by-step process we use when migrating agents between providers.
Step 1: Abstract your tool definitions
If your tool definitions are provider-specific (OpenAI function calling format, Claude tool format, Gemini function declarations), convert them to a provider-agnostic schema. Standard JSON Schema works. Then write a thin translation layer that converts your universal schema to whatever format the target provider expects.
This is a one-time investment that makes every future migration trivial.
Step 2: Rewrite the tool execution loop
The conversation flow for tool calling differs between providers. On OpenAI, tool results go in a message with role: "tool". On Claude, tool results go as content blocks within a role: "user" message. On Gemini, they go as FunctionResponse parts.
Map out the full tool call lifecycle for your target provider: how the model requests a tool call, how you execute it, how you send the result back, and how the model responds to the result. Test each step independently.
Step 3: Test your system prompt on the new model
Before migrating the full agent, test your system prompt with 10-20 representative inputs on the new model. Look for:
Drift in response format. If your agent's system prompt requires JSON output and the new model wraps it in markdown or adds preamble text, your parser will break.
Changes in constraint adherence. Instructions that GPT-4o followed loosely may be followed strictly by Claude, or vice versa.
Differences in tool selection behavior. Given the same input and same available tools, different models may choose different tools or call them in a different order. Test the 10 most common scenarios your agent handles.
Step 4: Verify token budgets
Count tokens for your typical agent payload (system prompt + tool definitions + conversation history + tool results) using the target provider's tokenizer. If your payload exceeds the target model's context window, you'll need to trim before migrating.
Step 5: Run in shadow mode
Deploy the new provider alongside the old one. Send the same inputs to both. Compare outputs. Don't switch production traffic until you've validated behavior on at least 100 representative inputs.
The number one migration mistake is switching production immediately after "it seems to work in testing." Shadow mode for a week catches the edge cases your test suite doesn't.
The abstraction that makes this a non-problem
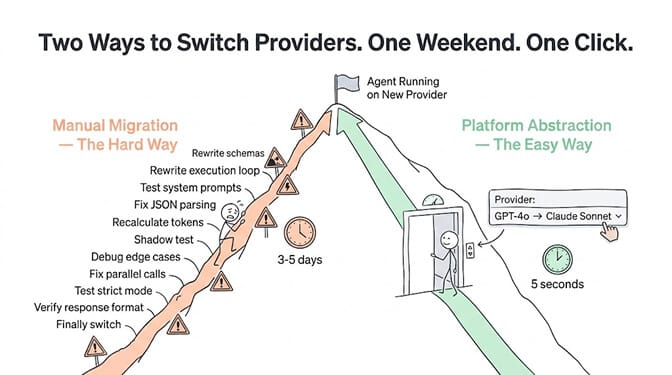
Here's the honest realization we had after the third provider migration: this shouldn't be a problem at all.
If your agent platform abstracts the LLM provider behind a standard interface, switching providers is a dropdown change. Tool definitions stay the same. System prompts stay the same. The platform handles format translation, token counting, and conversation flow differences.
This is exactly how we built BetterClaw's multi-provider support. All 28+ model providers work through the same interface. Your tools, prompts, memory, and integrations are provider-agnostic. Switching from GPT-4o to Claude Sonnet to Gemini Flash is a dropdown change. No code rewrite. No tool reformatting. No debugging weekend. BYOK with zero markup means you pay providers directly. Free plan with 1 agent and 500 credits a month. $49/month on Pro.
Provider-specific gotchas worth knowing
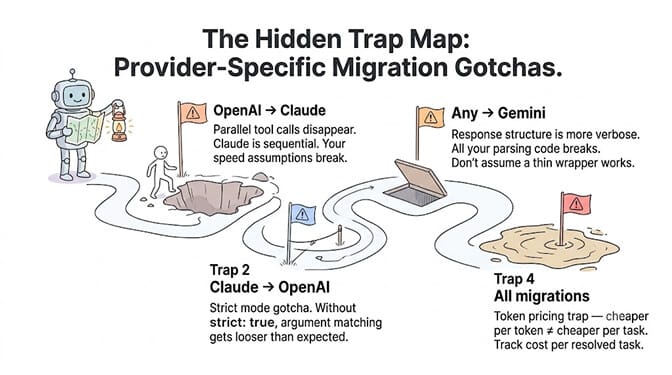
A few specific migration traps we've seen repeatedly:
OpenAI to Claude: parallel tool calls. OpenAI supports parallel tool calls (the model requests multiple tools simultaneously in one response). Claude handles tool calls sequentially by default. If your agent relies on parallel execution for speed, you'll need to restructure.
Claude to GPT: strict mode. OpenAI offers a strict: true parameter for function calling that guarantees the model's tool call arguments match your schema exactly. Claude doesn't have this explicit mode. If you're migrating from Claude to OpenAI and weren't using strict mode, you might find OpenAI without strict mode is more lenient in argument matching than you expected.
Any provider to Gemini: response structure. Gemini's function calling response format is more verbose. The parsing code you wrote for OpenAI or Claude will almost certainly break on Gemini's response structure. Don't assume a thin wrapper will work.
Token pricing traps. Migrating to a "cheaper" provider doesn't always save money. If the new model uses more tokens per response (longer outputs, more verbose reasoning), or if it needs more tool calls to reach the same result, the per-token savings get offset by higher token volume. Track total cost per task, not just cost per token.
The real cost of vendor lock-in
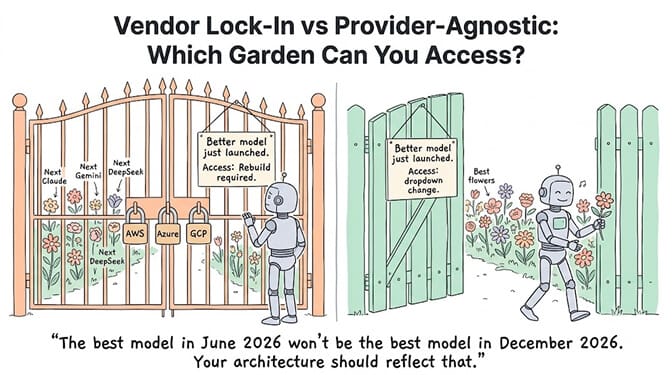
McKinsey estimates AI agents represent a $2.6-4.4 trillion addressable market. A significant portion of that value depends on agents that can adapt to rapidly changing LLM capabilities and pricing.
Google Vertex AI Agent Builder locks you to GCP. Azure Copilot Studio locks you to Azure. AWS Bedrock AgentCore locks you to AWS. If a better model launches on a competing platform, you can't use it without rebuilding.
The teams that build provider-agnostic agents today will be the ones that can adopt the next breakthrough model tomorrow without a rewrite.
The best model in June 2026 won't be the best model in December 2026. That's not a bug in the system. That's the system working. Your agent architecture should reflect that reality.
Give BetterClaw a look if provider flexibility matters to you. 28+ model providers. Switch with a dropdown. Free plan with 1 agent and 500 credits a month. $49/month for Pro. We handle the provider abstraction. You handle the agent logic.
Frequently Asked Questions
What does it mean to migrate an AI agent between LLM providers?
Migrating an AI agent between LLM providers means moving your agent from one model (like GPT-4o) to another (like Claude Sonnet or Gemini Flash) while preserving the agent's behavior, tool integrations, memory, and system prompt logic. The challenge is that each provider implements tool calling, conversation flow, and response formatting differently, so a migration is rarely as simple as changing an API key.
How does tool calling differ between OpenAI, Claude, and Gemini?
All three support tool calling with JSON Schema-based definitions, but the conversation flow differs significantly. OpenAI uses a role: "tool" message to return results. Claude expects tool results as content blocks within a role: "user" message. Gemini uses FunctionResponse parts. OpenAI supports parallel tool calls natively while Claude processes them sequentially. These differences mean rewriting your tool execution loop when you switch providers.
How long does it take to migrate an AI agent to a new LLM provider?
On a custom-built agent, expect 3-5 days for a thorough migration including tool schema conversion, execution loop rewriting, system prompt testing, token budget verification, and shadow testing. On a platform with provider abstraction (like BetterClaw), switching providers is a dropdown change that takes seconds because the platform handles format translation internally.
Is it worth building a provider-agnostic AI agent?
Yes, for three reasons: LLM pricing shifts constantly (DeepSeek V4 Pro at $0.43/M tokens versus GPT-4o at $2.50/M), different models outperform on different tasks (Claude for instruction following, GPT for multimodal, Gemini for speed), and provider outages are unavoidable. Building provider-agnostic, or choosing a platform that is, means you can optimize costs, performance, and reliability without rebuilding.
Will my AI agent behave the same after switching models?
Not identically. Different models interpret system prompts differently, select tools in different orders, and produce outputs with different formatting. The core capability will transfer, but expect behavioral differences on edge cases. Shadow testing (running both providers on the same inputs and comparing outputs for at least a week) is the best way to catch discrepancies before switching production traffic.