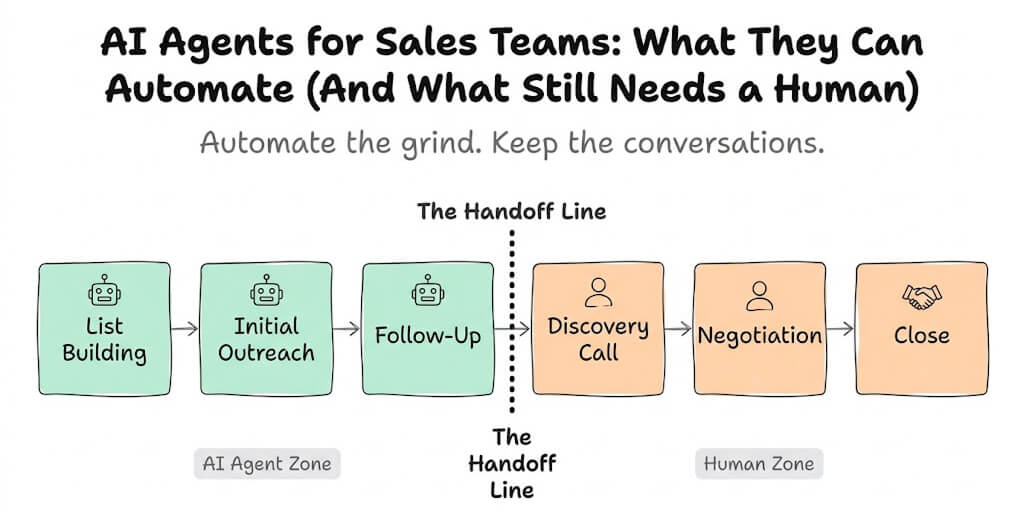
128GB of unified memory. 1 petaflop of FP4 compute. But the 273 GB/s memory bandwidth is shared between CPU and GPU. Here's where that bottleneck hits, which models run well, and when you should skip local hardware entirely.
Sebastian Raschka's benchmark comparison put it plainly: "The DGX Spark performs roughly on par with the 6-times more expensive H100 for single-sample inference on small models, but the H100 dominates for batched workloads and large models due to the bandwidth gap."
On par with a $30,000+ GPU for small models. Crushed by it for large models. Because of one number: 273 GB/s.
The DGX Spark ($4,699) has 128GB of unified memory. That's more than any single consumer GPU. It can technically load models up to 200 billion parameters. NVIDIA's own marketing says "run autonomous AI agents locally." They even ship NemoClaw (their OpenClaw security wrapper) pre-configured.
But memory capacity and memory bandwidth are different things. Capacity determines what fits. Bandwidth determines how fast it runs. And 273 GB/s, shared between CPU and GPU, creates a very specific performance envelope that most buyers don't understand until they've already spent $4,699. If the bandwidth math pushes you away from the Spark entirely, our DGX Spark alternatives guide covers six cheaper paths to local AI.
Here's what that bandwidth number actually means for running local AI agents.
Why memory bandwidth matters more than memory size for agents

LLM inference is memory-bandwidth bound, not compute-bound. For every token the model generates, the GPU reads the entire model's weights from memory. Bigger model = more bytes to read = slower generation. The speed limit isn't how fast the GPU can compute. It's how fast it can read.
The math is simple. A 7B parameter model in INT4 quantization = ~3.5GB. At 273 GB/s, the GPU can read that ~78 times per second. Theoretical max: ~78 tokens/second. Real-world: ~20-40 tokens/second (overhead, KV cache, etc.).
A 70B model in INT4 = ~35GB. At 273 GB/s: ~7.8 reads/second. Real-world: ~3-5 tokens/second. That's noticeably slow for interactive agent use.
The bandwidth rule: On DGX Spark, models under 20B parameters run at interactive speed (15-40 tokens/second). Models between 20-70B run but feel sluggish (3-10 tokens/second). Models above 70B technically load but are too slow for real-time agent interaction.
The DGX Spark sweet spot (8-20B models, and why that's actually fine)
Here's what most people get wrong about the DGX Spark.
They buy it to run the biggest model that fits. That's backwards. The 128GB memory is impressive. Loading a 120B model is possible. But running a 120B model at 2-3 tokens/second makes your agent feel broken. The experience is worse than using a smaller model at full speed.
AwesomeAgents' testing confirmed it: "In practice, anything above 30B gets noticeably slow for interactive use due to the 273 GB/s memory bandwidth being shared between CPU and GPU. The 8-20B range is where this hardware shines."
Specific benchmarks:
Llama 3.1 8B: 20 tokens/second (single request), 368 tokens/second at batch 32. Fast. Interactive. Agent-quality.
Nemotron 3 Super 120B (12B active MoE): Runs well because only 12B parameters are active per token despite the 120B total. This is the model NVIDIA optimized specifically for DGX Spark.
Qwen3 32B: Runs but slower. Acceptable for personal agents. Not acceptable for multi-user or latency-sensitive use.
For the comparison of hardware options for running always-on agents, our comparison covers the full spectrum from Pi to cloud.
How DGX Spark compares to the alternatives (the bandwidth gap)

Mac Studio M4 Ultra (192GB, $5,999+): 819 GB/s. 3x the bandwidth of DGX Spark. Models up to 70B run at interactive speed. IntuitionLabs noted: "Apple's M-series offers substantially higher memory bandwidth." If bandwidth matters more than CUDA, the Mac wins, a tradeoff we unpack further in Apple Silicon vs NVIDIA for AI agents.
DIY 3x RTX 3090 (~$3,000 used): 2,808 GB/s combined. 10x the Spark's bandwidth. But only 72GB total VRAM (24GB each). Can't load models above 30B without quantization tricks. Faster on small models. Can't load big models.
Cloud H100 ($2/hr): 3,352 GB/s. 12x the Spark's bandwidth. 80GB HBM3. Runs 70B models at 40+ tokens/second. But costs $1,460/month if running 24/7. The Spark pays for itself versus cloud in ~97 days of shared dev use (Spheron's analysis).
The honest trade-off: The DGX Spark's 128GB lets you load models nothing else can load on a single desktop device. But the 273 GB/s bandwidth means those large models run slowly. You're choosing "it fits" over "it's fast."
What this means for OpenClaw and local AI agents
Here's where it gets practical.

NVIDIA positions DGX Spark explicitly for local AI agents. Their blog post is titled "Scaling Autonomous AI Agents and Workloads with NVIDIA DGX Spark." NemoClaw, their OpenClaw security wrapper, ships pre-configured. OpenClaw runs on it. The PinchBench benchmark (specifically for measuring LLM performance with OpenClaw) was developed with DGX Spark in mind.
But OpenClaw's gateway doesn't need local inference. The gateway is a Node.js process. It routes messages to API providers. If you're using Claude, GPT, or DeepSeek via API, the DGX Spark is a $4,699 messaging router. That's $4,680 more than a Raspberry Pi doing the same job.
The DGX Spark makes sense for local agents when:
You need data sovereignty (nothing leaves your network). You're running Nemotron, Llama, or Qwen locally via Ollama. You want zero API costs. You're fine with 8-20B model performance.
The DGX Spark doesn't make sense when:
You use cloud APIs (the hardware is irrelevant). You need 70B+ model quality (the bandwidth makes it too slow). You want the simplest path to a working agent (cloud is simpler).
If you want an always-on agent without buying $4,699 hardware, managing CUDA drivers, or worrying about memory bandwidth, BetterClaw runs your agent in the cloud on any model from any provider. No hardware purchase. No local inference. BYOK with 28+ providers including local Ollama endpoints. Free tier with 1 agent. $19/month per agent for Pro. The $19/month is 0.4% of the DGX Spark's purchase price.
The honest recommendation (who should buy this)

Here's the take.
Buy the DGX Spark if: You're an AI researcher or developer who needs CUDA compatibility, 128GB for large model experimentation, NVIDIA's full software stack (NIM, TensorRT-LLM, NemoClaw), and you're running 8-20B models in production locally. The $4,699 pays for itself versus cloud in ~97 days if you're using it daily for development.
Don't buy the DGX Spark for: Running an always-on agent that uses cloud APIs. The Mac Mini M4 at $699 does the same gateway job. A $5/month VPS does it too. The DGX Spark's value is local inference, not message routing.
Don't buy the DGX Spark expecting: 70B model performance at interactive speed. The 273 GB/s bandwidth makes models above 30B feel slow. The Mac Studio's 819 GB/s is 3x faster for the same models at a similar price.
The DGX Spark is a genuinely impressive piece of hardware solving a genuine problem (local AI development with data sovereignty). But the memory bandwidth constraint means it's a development tool, not a production inference server. Spheron's analysis was direct: "If it crashes at 3 AM, someone has to restart it manually. No managed uptime. No automatic failover. No replacement SLA."
For production always-on agents, managed platforms handle the infrastructure so the hardware question disappears entirely. Give BetterClaw a try. Free tier with 1 agent and BYOK. $19/month per agent for Pro. No hardware. No bandwidth bottlenecks. No thermal throttling. The agent runs on cloud infrastructure. The model choice is yours. The infrastructure is ours.
Frequently Asked Questions
What is the memory bandwidth of the NVIDIA DGX Spark?
273 GB/s of LPDDR5x unified memory, shared between the CPU and GPU. This is lower than the Mac Studio M4 Ultra (819 GB/s) and significantly lower than discrete GPUs like the RTX 4090 (1,008 GB/s). The bandwidth determines token generation speed for local LLM inference. Models under 20B run at interactive speed. Models above 30B feel noticeably slow.
Can the DGX Spark run OpenClaw with local models?
Yes. NVIDIA ships NemoClaw (their OpenClaw security wrapper) pre-configured on DGX Spark. Ollama is pre-installed. Models like Nemotron 3 Super 120B (12B active), Llama 3.1 8B (20 tokens/second), and Qwen3 32B run locally. However, if you're using cloud APIs (Claude, GPT, DeepSeek), the DGX Spark's local inference capability is unused. A $5 VPS handles the gateway just as well.
Is the DGX Spark better than a Mac Studio for AI agents?
Depends on your priority. DGX Spark: 128GB memory (loads larger models), CUDA compatibility, NVIDIA software stack, $4,699. Mac Studio M4 Ultra: 192GB memory, 819 GB/s bandwidth (3x faster inference), no CUDA, $5,999+. For NVIDIA ecosystem users running 8-20B models: DGX Spark. For maximum inference speed on 30-70B models: Mac Studio.
How much does the DGX Spark cost compared to cloud or BetterClaw?
DGX Spark: $4,699 one-time (plus electricity, ~$50-100/year). Cloud H100: ~$2/hour ($1,460/month 24/7). BetterClaw: $0 (free tier) or $19/month (Pro), no hardware needed. The DGX Spark breaks even versus cloud in ~97 days of daily dev use. BetterClaw costs 0.4% of the Spark's purchase price per month and handles all infrastructure.
Is 273 GB/s enough bandwidth for production AI agents?
For development and personal agents using 8-20B models: yes, performance is good (15-40 tokens/second). For production multi-user agents or models above 30B: no, the shared bandwidth creates a noticeable bottleneck. Spheron noted: "DGX Spark is a desktop computer. No managed uptime, no automatic failover, no replacement SLA." Production agents belong on managed infrastructure or cloud GPUs with higher bandwidth.